
「消息队列」看过来!
消息队列」看过来!
一、什么是消息队列?

当我试图用一则通俗的比喻来说明这个概念的时候,我想到一个有意思的比喻:如果把队列抽象成一个集合体,那么消息队列也就是一堆消息的集合。按照这个思路我想到了「杂志」。这不就是一堆消息的集合吗,关心这些消息的人都能通过「购买」来获得这些消息,而我可以通过不同种类的「杂志」或许到不同的消息。并且如果我作为出版方,我可以提供所有出版过的「杂志」,也可以选择让读者只能购买近期的。
二、为什么需要消息队列?
好处一:解耦
假设我们做了一个会议室预定系统,我们的一个设备坏了。我们需要通知预定这个会议室的所有人,于是我们需要发邮件,伪代码如下:
@Service
public class EquipmentServiceImpl implements EquipmentService {
@Autowired private EmailService emailService;
@Autowired private EquipmentRepository equipmentRepository;
public void setEquipmentBroken(Long id) {
Equipment equipment = equipmentRepository.findById(id);
equipment.setStatus(Equipment.StatusEnum.BROKEN);
emailService.sendEmail();
}
}问题来了,如果我们后来发现设备坏了并且需要更改可用库存的数量,这时候我们是不是要在这里加入 InventoryService 库存服务的代码呢?后来如果经理说设备坏了应该通知他才对啊,所以我们要不要加入 emailService.sendEmailTo(Manager) 这样的代码呢?
随着我们业务模块接入越来越多,我们的代码与其他模块越来越耦合,修改代码的难度也指数级的增加,所以我们引入「消息队列」,把「设备坏了」这样的消息发送到队列中,其他关心这条消息的业务就会得到这样的「通知」,然后就会去做对应的事,这样各个模块之间就解耦了。伪代码看上去如下:
public void setEquipmentBroken(Long id) {
Equipment equipment = equipmentRepository.findById(id);
equipment.broken();
eventBus.publish(new EquipmentBrokenEvent(equipment.id));
}好处二:异步处理
接着上面的例子,假设我们已经把「发送邮件」、「修改库存」以及「通知经理」的代码都写入了我们的 Service 代码中,它们分别耗时:30ms、50ms、80ms,并且我们得知,原本最主要的功能其实是「发送邮件」,但我们完成主要的功能之后却等待了更多的额外时间,这显示是不合理的。
所以我们为了提高用户体验&提高吞吐量,我们其实可以引入「消息队列」来进行异步的操作。
好处三:削峰/限流

假设我们的服务器最多能支持每秒 1000 个请求,而我们公司在节日要搞促销,为了避免服务器挂掉我们额外申请了两台服务器做了负载均衡,于是我们现在的机器最理想的情况能够支持每秒 3000 个请求,但奈何活动太火爆了,每秒来的请求有大概 4000 个,这些多出来的请求就可能导致服务器给直接挂掉了。

所以我们就引入了一个「消息队列」,让消息不直接到达服务器,而是先让「消息队列」保存这些数据,然后让下面的服务器每一次都取各自能处理的请求数再去处理,这样当请求数超过服务器最大负载时,就不至于把服务器搞挂了。
三、消息队列适用的场景
基于上面的描述,我们大概能想到「消息队列」的局限性,例如当「生产者」需要「从消费者获得反馈」时,就会出现一定的问题。例如我之前尝试着使用「事件驱动」的方式编码时,我想要把 Service 的一些主逻辑给转移到关注该事件的监听器上时,发现有点问题,我原本的意图是想让一部分代码解耦,但作为主逻辑的一部分我需要保证它们准确的执行,当我使用「消息」的方式传递出去时,我无法得到消费者的反馈,所以最终我还是把主逻辑给迁回来了,算是一次失败的尝试吧。
场景一:异步处理
通过上述的问题你也看到了,「消息队列」适用于异步处理,并且是那些不期望从消费者得到反馈的处理。就好像一开始说到的设备坏了的问题,我只需要通知设备坏了,至于之后需要做什么事,关心的人自然会去做相应的处理。
场景二:日志收集
上面提到的异步处理,跟日志系统似乎搭配起来也很好。特别是当你需要把日志发往单独的数据平台的时候,「消息队列」尤为有用,我们不再需要在业务代码里面侵入我们的各种打点or日志,只需要简单的发布一条消息,再去关注做处理就好了。
场景四:应用解耦
基于上面的例子你应该也能感受一二了。
场景三:流量削峰
这也是「消息队列」常见的场景,通过引入「消息队列」,我们一来可以控制请求的人数,二来也可以缓解短时间内高流量的压力。
场景四:消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
场景五:可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
场景六:顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。
场景七:缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。消息队列通过一个缓冲层来帮助任务最高效率的执行,该缓冲有助于控制和优化数据流经过系统的速度。以调节系统响应时间。
Mq原理
1、MQ原型
1)MQ原型-Pub/Sub发布订阅
(广播:生产者-消费之1对多):使用topic作为通信载体

希望发送的消息可以不被做任何处理、或者只被一个消息者处理、或者可以被多个消费者处理的话,那么可以采用Pub/Sub模型。
MQ原型-PTP点对点
:使用queue作为通信载体
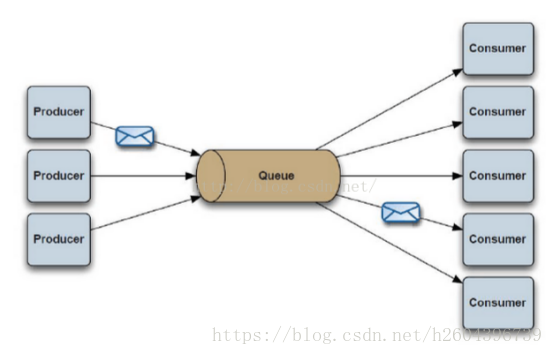
如果希望发送的每个消息都会被成功处理的话,那么需要P2P模式。
MQ原型-多点广播:
MQ适用于不同类型的应用。其中重要的,也是正在发展中的是"多点广播"应用,即能够将消息发送到多个目标站点(Destination List)。可以使用一条MQ指令将单一消息发送到多个目标站点,并确保为每一站点可靠地提供信息。MQ不仅提供了多点广播的功能,而且还拥有智能消息分发功能,在将一条消息发送到同一系统上的多个用户时,MQ将消息的一个复制版本和该系统上接收者的名单发送到目标MQ系统。目标MQ系统在本地复制这些消息,并将它们发送到名单上的队列,从而尽可能减少网络的传输量。
MQ原型-群集(Cluster):
为了简化点对点通讯模式中的系统配置,MQ提供Cluster(群集)的解决方案。群集类似于一个域(Domain),群集内部的队列管理器之间通讯时,不需要两两之间建立消息通道,而是采用群集(Cluster)通道与其它成员通讯,从而大大简化了系统配置。此外,群集中的队列管理器之间能够自动进行负载均衡,当某一队列管理器出现故障时,其它队列管理器可以接管它的工作,从而大大提高系统的高可靠性
2、MQ组成结构
Broker:消息服务器,作为server提供消息核心服务
Producer:消息生产者,业务的发起方,负责生产消息传输给broker,
Consumer:消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理
Topic:主题,发布订阅模式下的消息统一汇集地,不同生产者向topic发送消息,由MQ服务器分发到不同的订阅 者,实现消息的广播
Queue:队列,PTP模式下,特定生产者向特定queue发送消息,消费者订阅特定的queue完成指定消息的接收
Message:消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输
Mq常用协议
AMQP协议
AMQP即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同开发语言等条件的限制。
优点:可靠、通用
MQTT协议
MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分。该协议支持所有平台,几乎可以把所有联网物品和外部连接起来,被用来当做传感器和致动器(比如通过Twitter让房屋联网)的通信协议。
优点:格式简洁、占用带宽小、移动端通信、PUSH、嵌入式系统
STOMP协议
STOMP(Streaming Text Orientated Message Protocol)是流文本定向消息协议,是一种为MOM(Message Oriented Middleware,面向消息的中间件)设计的简单文本协议。STOMP提供一个可互操作的连接格式,允许客户端与任意STOMP消息代理(Broker)进行交互。
优点:命令模式(非topic\queue模式)
XMPP协议
XMPP(可扩展消息处理现场协议,Extensible Messaging and Presence Protocol)是基于可扩展标记语言(XML)的协议,多用于即时消息(IM)以及在线现场探测。适用于服务器之间的准即时操作。核心是基于XML流传输,这个协议可能最终允许因特网用户向因特网上的其他任何人发送即时消息,即使其操作系统和浏览器不同。
优点:通用公开、兼容性强、可扩展、安全性高,但XML编码格式占用带宽大
四、常见消息队列中间件
如果自己设计一个?
我们在讨论市面上常见的「消息队列」中间件之前,我们先来考虑自己造一个怎么样?如果是你自己来设计,你会怎么做?乍一想,似乎每个语言都会有自己实现的「队列」,往队列里塞数据,再从队列里面挨个取就行了?

但是一细想好像事情并不简单。作为一个「消息队列」,你首先要保证数据不能给人家弄丢了吧?存内存?万一断电了怎么办?写磁盘?消息量超过系统写磁盘速率上限了怎么办?备份又该怎么做呢?
好,假设我一整捣鼓,保证了我的数据不会丢失了,下一个问题,生产者怎么往「消息队列」里面塞数据?我的意思是,生产者可能不止一个,把全量的消息放在一个队列似乎不太合适,我需要给这些消息分个类吧?新来了一个分类的消息我怎么动态的扩容呢?消费者又如何消费这些数据呢?多个消费者之间又如何进行协调呢?
好吧..总之问题挺多的..并不像表面那么简单。
RabbitMQ

RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负 载均衡或者数据持久化都有很好的支持。
Redis
Redis 也能用来做「消息队列」。Redis 是一个基于 Key-Value 对的 NoSQL 数据库,开发维护很活跃。虽然它是一个 Key-Value 数据库存储系统,但它本身支持 MQ 功能, 所以完全可以当做一个轻量级的队列服务来使用。对于 RabbitMQ 和 Redis 的入队和出队操作,各执行 100 万次,每 10 万次记录一次执行时间。测试 数据分为 128 Bytes、512 Bytes、1 K和 10 K四个不同大小的数据。实验表明:入队时,当数据比较小时 Redis 的性能要高于 RabbitMQ,而如果数据大小超过了 10 K,Redis 则慢的无法忍受;出队时,无论数据大小,Redis 都表现出非常好的性能,而 RabbitMQ 的出队性能则远低于Redis。
Kafka/Jafka
Kafka 是 Apache 下的一个子项目,是一个高性能跨语言分布式 Publish/Subscribe 消息队列系统,而 Jafka 是在 Kafka 之上孵化而来的,即 Kafka 的一个升级版。
具有以下特性:
- 快速持久化,可以在O(1)的系统开销下进行消息持久化;
- 高吞吐,在一台普通的服务器上既可以达到 10 W/s的吞吐速率;
- 完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现复杂均衡;
- 支持 Hadoop 数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。
Kafka 通过 Hadoop 的并行加载机制来统一了在线和离线的消息处理。Apache Kafka 相对于 ActiveMQ 是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
ZeroMQ
ZeroMQ 号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ 能够实现 RabbitMQ 不擅长的高级 / 复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这 MQ 能够应用成功的挑战。ZeroMQ 具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用 ZeroMQ 程序库,可以使用 NuGet 安装,然后你就可以愉快的在应用程序之间发送消息了。但是 ZeroMQ 仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter 的 Storm 0.9.0 以前的版本中默认使用 ZeroMQ 作为数据流的传输(Storm 从 0.9 版本开始同时支持 ZeroMQ 和 Netty 作为传输模块)。
ActiveMQ
ActiveMQ 是 Apache 下的一个子项目。 类似于 ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于 RabbitMQ,它少量代码就可以高效地实现高级应用场景。

