Dubbo高性能网关--Flurry介绍
1.背景
什么是API网关,它的作用是什么,产生的背景是啥?
从架构的角度来看,API网关暴露http接口服务,其本身不涉及业务逻辑,只负责包括请求路由、负载均衡、权限验证、流量控制、缓存等等功能。其定位类似于Nginx请求转发、但功能要多于Nginx,背后连接了成百上千个后台服务,这些服务协议可能是rest的,也可能是rpc协议等等。
网关的定位决定了它生来就需要高性能、高效率的。网关对接着成百上千的服务接口,承受者高并发的业务需求,因此我们对其性能要求严苛,其基本功能如下:
-
协议转换
一般从前端请求来的都是HTTP接口,而在分布式构建的背景下,我们后台服务基本上都是以RPC协议而开发的服务。这样就需要网关作为中间层对请求和响应作转换。
将HTTP协议转换为RPC,然后返回时将RPC协议转换为HTTP协议 -
请求路由
网关背后可能连接着成本上千个服务,其需要根据前端请求url来将请求路由到后端节点中去,这其中需要做到负载均衡 -
统一鉴权
对于鉴权操作不涉及到业务逻辑,那么可以在网关层进行处理,不用下层到业务逻辑。 -
统一监控
由于网关是外部服务的入口,所以我们可以在这里监控我们想要的数据,比如入参出参,链路时间。 -
流量控制,熔断降级
对于流量控制,熔断降级非业务逻辑可以统一放到网关层。
有很多业务都会自己去实现一层网关层,用来接入自己的服务,但是对于整个公司来说这还不够。
2.Flurry Dubbo API网关
Flurry是云集自研的一款轻量级、异步流式化、针对Dubbo的高性能API网关。与业界大多数网关不同的是,flurry自己实现了 http与dubbo协议互转的流式化的dubbo-json协议,可高性能、低内存要求的对http和dubbo协议进行转换。除此之外,其基于 netty作为服务容器,提供服务元数据模型等等都是非常具有特点的。下面我们将详细介绍 flurry的特性:
2.1 基于Netty容器
传统网关大多采用tomcat作为容器,其请求于响应没有做到异步,tomcat会有一个核心线程池来处理请求和响应,如果RT比较高的话,将会对性能有一定的影响。
Flurry 网关请求响应基于Netty线程模型,后者是实现了Reactive,反应式模式规范的,其设计就是来榨干CPU的,可以大幅提升单机请求响应的处理能力。
最终,Flurry通过使用Netty线程模型和NIO通讯协议实现了HTTP请求和响应的异步化。
每一次http请求最终都会由Netty的一个Client Handler来处理,其最终以异步模式请求后台服务,并返回一个CompletableFuture,当有结果返回时才会将结果返回给前端。
见下面一段例子:
- ServerProcessHandler
public class ServerProcessHandler extends SimpleChannelInboundHandler<RequestContext> {
public void handlerPostAsync(RequestContext context, ChannelHandlerContext ctx) throws RpcException {
CompletableFuture<String> jsonResponse = asyncSender.sendAsync(context, ctx);
jsonResponse.whenComplete((result, t) -> {
long et = System.currentTimeMillis();
if (t != null) {
String errorMessage = HttpHandlerUtil.wrapCode(GateWayErrorCode.RemotingError);
doResponse(ctx, errorMessage, context.request());
} else {
doResponse(ctx, HttpHandlerUtil.wrapSuccess(context.requestUrl(), result), context.request());
}
});
}
//省略部分代码
public static void sendHttpResponse(ChannelHandlerContext ctx, String content, FullHttpRequest request) {
//将结果写回Client,返回前端
ctx.writeAndFlush(response);
}
}
2.2 服务元数据模型
所谓的服务元数据信息,是指服务接口的方法列表、每个方法的输入输出参数信息、每个参数的字段信息以及上述(方法、参数以及字段)的注释,其非常类似于Java Class的反射信息。
元数据的作用
有了服务元数据,我们就可以不必需要服务的API包,并能够清晰的知道整个服务API的定义。
这在Dubbo服务Mock调用、服务测试、文档站点、流式调用等等场景下都可以发挥抢到的作用。
元数据与注册中心数据比较
| \ | 服务元数据 | 注册中心数据 |
|---|---|---|
| 变化频率 | 基本不变,随着服务迭代更改而更改 | 随着服务节点上下线而随时进行变化 |
| 职责 | 描述服务,定义服务的基本属性 | 存储地址列表 |
| 使用场景 | 无API依赖包模式调用(直接json),文档站点,Mock测试等 | 服务治理和调用 |
| 交互模型 | 服务编译期生成元信息,client通过接口调用模式获取 | 发布订阅模型,线上进行交互 |
元数据中心的价值
小孩子才分对错,成年人只看利弊。额外引入一个元数据生成机制,必然带来运维成本、理解成本、迁移成本等问题,那么它具备怎样的价值,来说服大家选择它呢?上面我们介绍元数据中心时已经提到了服务测试、服务 MOCK 等场景,这一节我们重点探讨一下元数据中心的价值和使用场景。
那么,Dubbo服务元数据能够利用到哪些场景呢?下面我们来详细描述。
2.3 流式协议转换
flurry网关对外提供的是HTTP Rest风格的接口,并辅以JSON数据的形式进行传输。因此flurry需要做到将外部的HTTP协议请求转换为dubbo RPC协议,然后再将dubbo协议的返回结果转换为HTTP协议返回给前端。
Dubbo原生泛化实现
泛化模式就是针对Dubbo Consumer端没有服务接口API包的情况下,使用Map的形式将POJO的每一个属性映射为Key,Value的模式来请求Dubbo服务端,在Dubbo服务端处理完成请求之后,再将结果POJO转为Map的形式返回给消费端。
使用泛化模式来实现对Http <-> Dubbo的转换流程大致如下图所示:
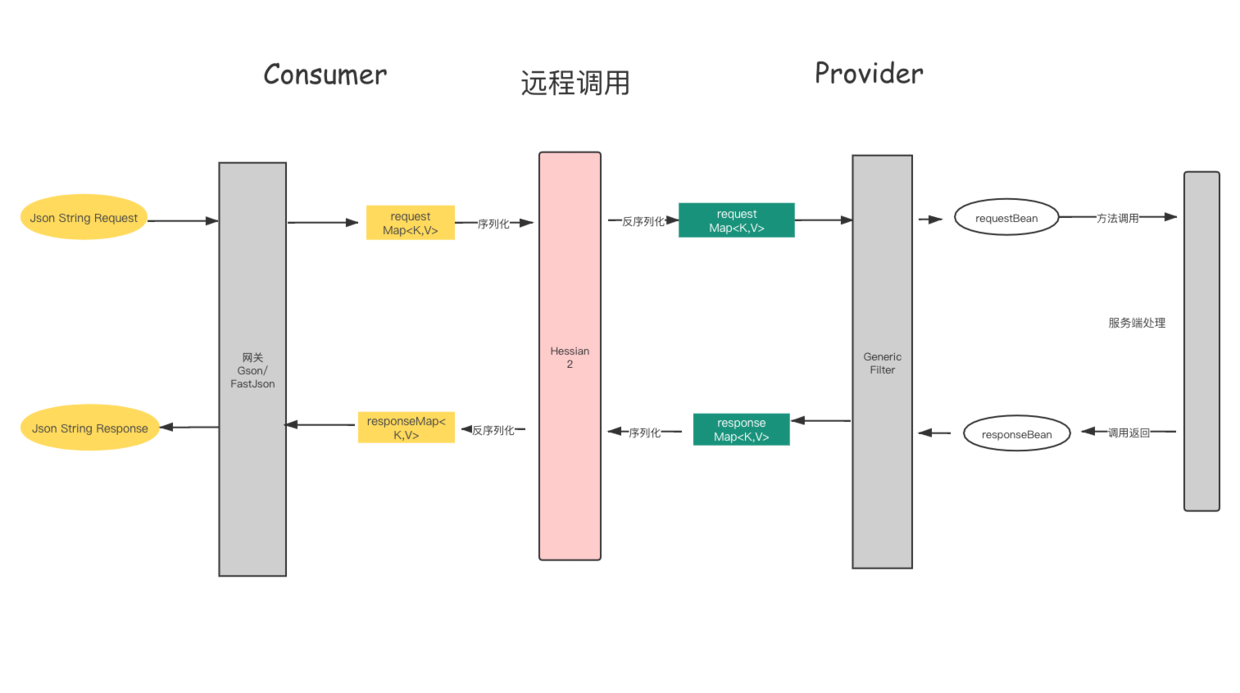
Http请求,数据通过JSON传输,其格式严格按照接口POJO属性。返回结果再序列化为Json返回前端。现在大多数开源的网关,在dubbo协议适配上都是采用的泛化模式来做到协议转换的,这其中就包括 Soul 等。
泛化模式的协议转换数据流动流程:
JsonString -> JSONObject(Map) -> Binary
将JSON 字符串转换为 JSON 对象模型(JSONObject),此处通过第三方JSON映射框架(如Google的Gson, 阿里的FastJSON等)来做,然后将Map通过Hessian2 协议序列化为Binaray。
泛化缺点
-
泛化过程数据流会经过了三次转换, 会产生大量的临时对象, 有很大的内存要求。使用反射方式对于旨在榨干服务器性能以获取高吞吐量的系统来说, 难以达到性能最佳。
-
同时服务端也会对泛化请求多一重 Map <-> POJO 的来回转换的过程。整体上,与普通的Dubbo调用相比有10-20%的损耗。
自定义Dubbo-Json协议
我们的需求是要打造一款高性能、异步、流式的Dubbo API网关,当然要对不能容忍上述泛化带来的序列化的痛点,针对http与dubbo协议转换,我们的要求如下:
自定义的Dubbo-Json协议参考了dapeng-soa 的流式解析协议的思想,详情请参考:dapeng-json
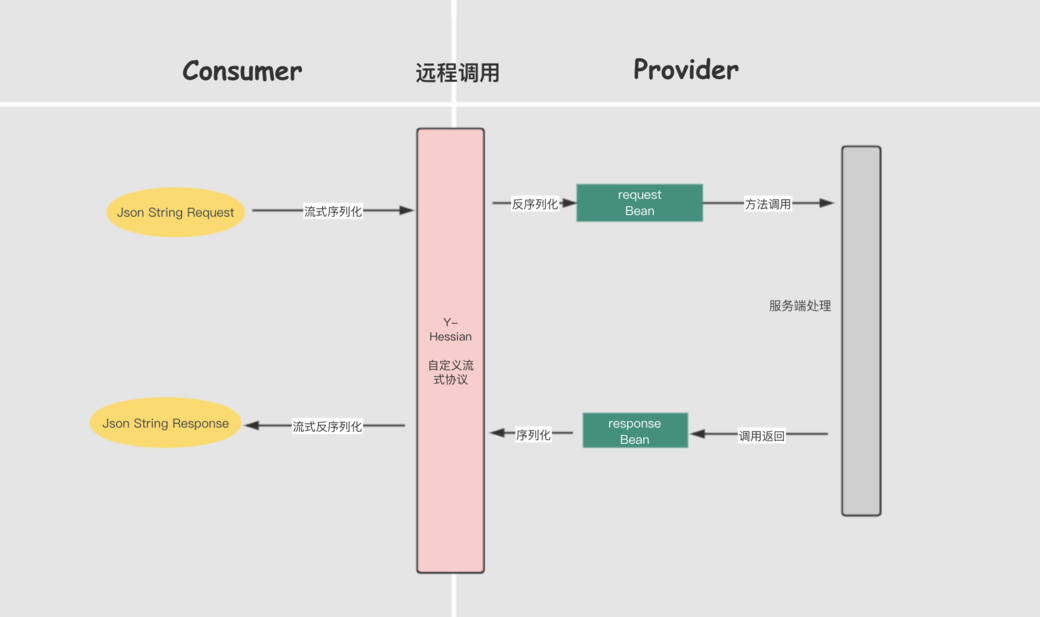
针对上述泛化模式转换Dubbo协议的缺点,我们在flurry-core 中的 Dubbo-Json 序列化协议做到了这点,下面我们来讲解它是如何高效率的完成JsonString到 dubbo hessian2 序列化buffer的转换的。
-
高性能
此协议用来在网关中作为http和rpc协议的转换,要求其能实现高效的序列化以及反序列化, 以支持网关海量请求的处理. -
低内存使用
虽然大部分情况下的JSON请求、返回都是数据量较小的场景, 但作为平台框架, 也需要应对更大的JSON请求和返回, 比如1M、甚至10M. 在这些场景下, 如果需要占用大量的内存, 那么势必导致巨大的内存需求, 同时引发频繁的GC操作, 也会联动影响到整个网关的性能.
Dubbo-Json参考了XML SAX API的设计思想, 创造性的引入了JSON Stream API, 采用流式的处理模式, 实现JSON 对 hessian2 的双向转换, 无论数据包有多大, 都可以在一定固定的内存规模内完成.
- 容错性好
前面我们引入了服务元数据的概念,因此在此基础上,通过元数据提供的接口文档站点,自动生成请求数据模板,每一个属性的类型精确定义,譬如必须使用正确的数据类型, 有的字段是必填的等。
那么在Json -> Hessian2Buffer的转换过程中,如果出现与元数据定义不符合的情况,就回直接报错,定位方便。
流式协议解析过程
流式协议,顾名思义就是边读取边解析,数据像水流一样在管道中流动,边流动边解析,最后,数据解析完成时,转换成的hessian协议也已全部写入到了buffer中。
这里处理的核心思想就是实现自己的Json to hessian2 buffer 的语法和此法解析器,并配合前文提及的元数据功能,对每一个读取到的json片段通过元数据获取到其类型,并使用 hessian2协议以具体的方式写入到buffer中。
JSON结构简述
首先我们来看看JSON的结构. 一个典型的JSON结构体如下
{
"request": {
"orderNo": "1023101",
"productCount": 13,
"totalAmount: 16.54
}
}
其对应Java POJO 自然就是上述三个属性,这里我们略过。下面是POJO生成的元数据信息
<struct namespace="org.apache.dubbo.order" name="OrderRequest">
<fields>
<field tag="0" name="orderNo" optional="false" privacy="false">
<dataType>
<kind>STRING</kind>
</dataType>
</field>
<field tag="1" name="productCount" optional="false" privacy="false">
<dataType>
<kind>INTEGER</kind>
</dataType>
</field>
<field tag="2" name="totalAmount" optional="false" privacy="false">
<dataType>
<kind>DOUBLE</kind>
</dataType>
</field>
</fields>
</struct>
Json解析器
相比XML而言,JSON数据类型比较简单, 由Object/Array/Value/String/Boolean/Number等元素组成, 每种元素都由特定的字符开和结束. 例如Object以'{'以及'}'这两个字符标志开始以及结束, 而Array是'['以及']'. 简单的结构使得JSON比较容易组装以及解析。
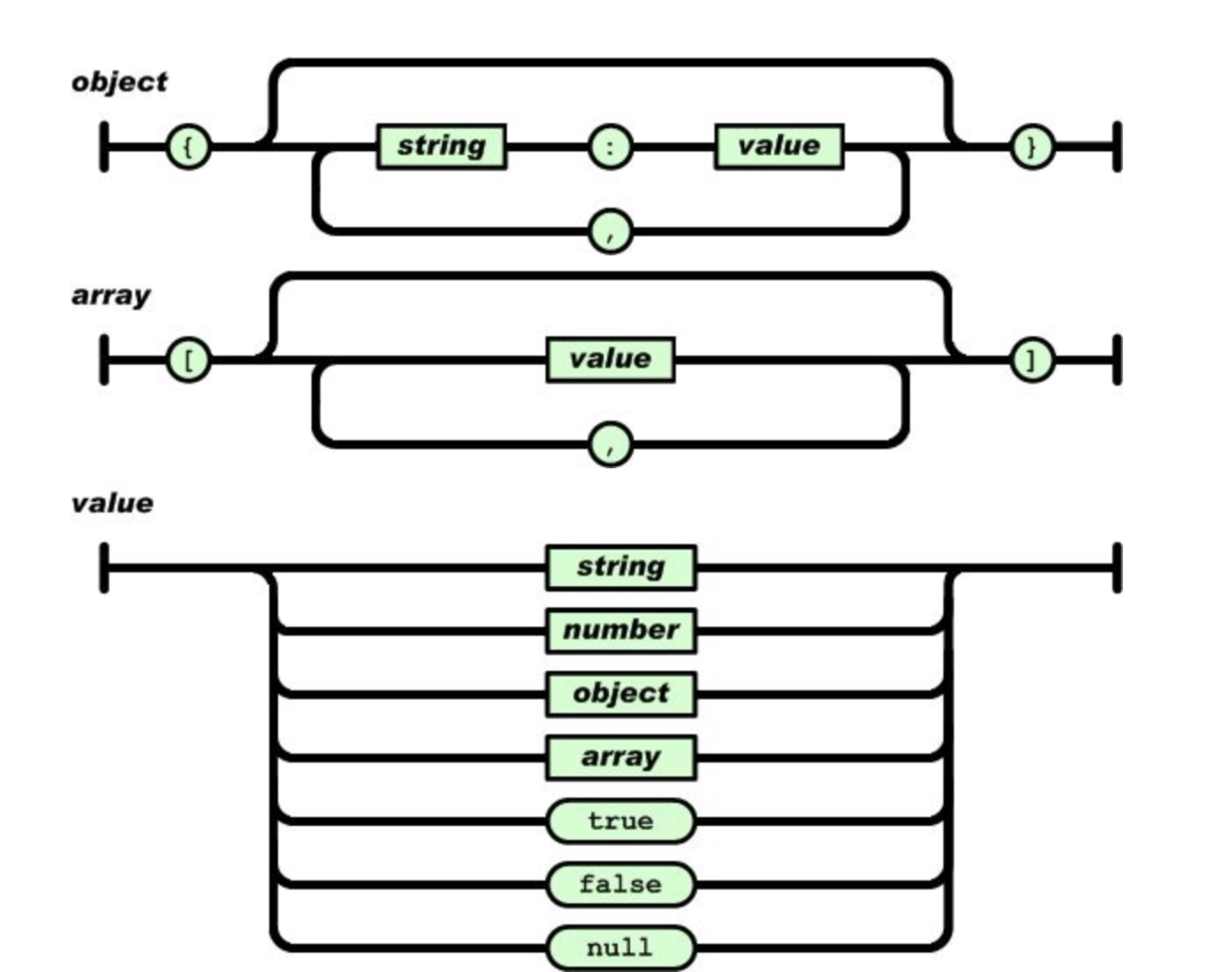
如图,我们可以清晰的了解JSON的结构,那么对上述JSON进行解析时,当每一次解析到一个基本类型时,先解析到key,然后根据key到元数据信息中获取到其value类型,然后直接根据对应类型的hessian2序列化器将其序列化到byte buffer中。
当解析到引用类型,即 Struct类型时,我们将其压入栈顶,就和java方法调用压栈操作类似。
通过上面的步骤一步一步,每解析一步Json,就将其写入到byte buffer中,最终完成整个流式的解析过程。
拿上面json为例:
{
"request": {
"orderNo": "1023101",
"productCount": 13,
"totalAmount: 16.54
}
}
-
解析器每一步会解析一个单元,首先解析到request,然后根据请求附带的接口、版本等信息找到当前请求服务的元数据信息(元数据信息缓存在网关之中,定期刷新)。
-
开始解析属性,解析到 orderNo key时,通过元数据中得知其数据类型为String,然后再解析完value之后,通过调用hessian2的writeString API将其写入到hessian2序列化的byte buffer 缓存中。
-
依次解析后面的属性,当全部属性解析完成之后,解析到最后一个 } 时,此时证明数据全部解析完毕,于是hessian buffer 通过flush 将数据全部写入到bytebuffer中,请求直接发送出去。
-
Dubbo服务端再接收到这个序列化的buffer之后,会像其他普通dubbo consumer调用服务的模式一样的去解析,然后反序列化为请求实体,进行业务逻辑处理。
-
flurry网关再接受到返回的数据时,在没有反序列化之前,其是一个hessian2的二级制字节流,我们仍然通过dubbo-json的解析模式,直接将反序列化出来的属性写为Json String
总结:
上述整个请求和响应,网关处理如下:
- request: Json -> hessian2二进制字节流
- response:hessian2二进制字节流 -> json
请求和响应中没有像泛化模式中的中间对象转换,直接一步到位,没有多余的临时对象占用内存,没有多余的数据转换,整个过程像在管道中流式的进行。
2.4 flurry网关与tomcat接入层比较
传统的dubbo服务接入层是采用tomcat作为容器来实现,每一个业务模块对应一个tomcat应用,其本身需要以来dubbo各个服务的API接口包,tomcat中启动几十个传统的dubbo consumer 服务,然后通过webmvc的模式提供http接口。
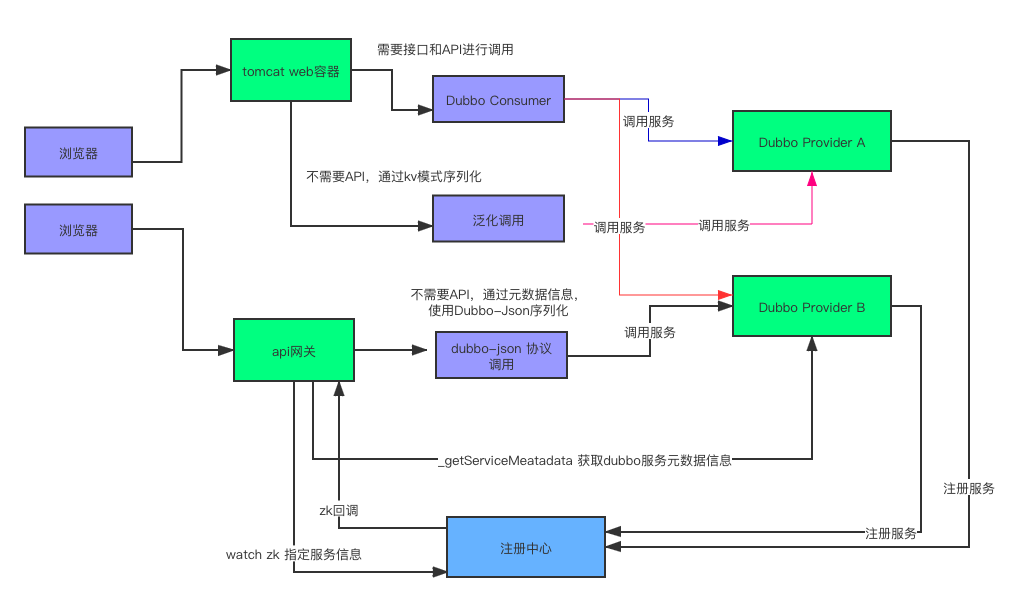
如上图所示,flurry dubbo网关不必依赖任何dubbo接口API包,而是直接通过获取服务元数据、并通过dubbo-json流式协议来调用后端服务。其本身不会耦合业务逻辑。
2.5 性能测试
测试环境
硬件部署与参数调整
| 机型 | 角色 | CPU | 内存 | 带宽 |
|---|---|---|---|---|
| CVM虚拟机 | API网关 | 8核 | 16GB | 10Mbp/s |
| CVM虚拟机 X2 | Dubbo Provider | 4核 | 8GB | 10Mbp/s |
| CVM虚拟机 | wrk压测机 | 8核 | 16GB | 10Mbp/s |
测试目的
对基于Y-Hessian的 异步化、流式转换的Yunji Dubbo API网关进行性能压测,了解它的处理能力极限是多少,这样有便于我们推断其上线后的处理能力,以及对照现有的Tomcat接入层模式的优势,能够节约多少资源,做到心里有数。
测试脚本
性能测试场景
-
网关入参0.5k请求json,深度为3层嵌套结构,服务端接收请求,返回0.5k返回包
-
网关入参2k请求json,深度为3层嵌套结构,服务端接收请求,返回0.5k返回包
上述场景均使用wrk在压测节点上进行5~10min钟的压测,压测参数基本为12线程256连接或者512连接,以发挥最大的压测性能。
测试结果
性能指标(量化)
| 场景名称 | wrk压测参数 | Avg RT | 实际QPS值 |
|---|---|---|---|
| 0.5k数据 | -t12 -c256 | 3.77ms | 69625 |
| 0.5k数据 | -t12 -c 512 | 7.26ms | 71019 |
| 2k数据 | -t12 -c256 | 5.48ms | 46576 |
| 2k数据 | -t12 -c512 | 10.80ms | 46976 |
运行状况(非量化)
-
API网关(8c16g)运行良好,压测期间CPU占用为550%左右
-
两个 Dubbo Provider 服务运行良好,CPU占用为100%左右
-
各个角色内存运行稳定,无OOM,无不合理的大内存占用等。
3.总结
flurry集Dubbo网关、异步、流式、高性能于一身,其目标就是替代一些以tomcat作为dubbo消费者的接入层,以更少的节点获得更多的性能提升,节约硬件资源和软件资源。
4.后续
后续在flurry的基础上,将实现鉴权管理、流量控制、限流熔断、监控收集等等功能
5.参考项目
Flurry: 基于Dubbo服务的高性能、异步、流式网关
y-hessian: 自定义的Dubbo-hessian 协议,支持流式序列化模式,为flurry网关序列化/反序列化组件。
Yunji-doc-site: 与元数据集成相关的项目,以及文档站点
dapeng-soa: Dapeng-soa 是一个轻量级、高性能的微服务框架,构建在Netty以及定制的精简版Thrift之上。 同时,从Thrift IDL文件自动生成的服务元数据信息是本框架的一个重要特性,很多其它重要特性都依赖于服务元数据信息。 最后,作为一站式的微服务解决方案,Dapeng-soa还提供了一系列的脚手架工具以支持用户快速的搭建微服务系统
dapeng-json:dapeng-json协议介绍

