

centos7 离线搭建kafka集群
在安装kafka之前,需要搭建zookeeper集群
搭建zookeeper集群之前后搭建步骤:https://www.cnblogs.com/leihongnu/p/16280097.html
启动成功zookeeper集群后,开始搭建kafka集群
1、安装包
地址:https://archive.apache.org/dist/kafka/0.11.0.2/kafka_2.12-0.11.0.2.tgz
2、解压文件到 /usr/local/
#tar -zxvf kafka_2.12-0.11.0.2.tgz -C /usr/local/

3、修改配置文件
#cd /usr/local/kafka_2.12-0.11.0.2/config
创建kafka数据和日志目录,位置请根据实际磁盘情况创建目录
#mkdir -p /home/kafka/data
#mkdir -p /home/kafka/logs
编辑文件
#vi server.properties
主要修改,红色文字部分
# 唯一标识在集群中的ID,另外的节点不能用0了
broker.id=0
# 默认为true,启用删除主题。如果此配置已关闭,则通过管理工具删除主题将不起作用
delete.topic.enable=true
# 允许自动创建topic
auto.create.topics.enable=true
# 消息体的最大大小,单位是字节
message.max.byte=5242880
# 单个topic默认分区的replication个数,不能大于集群中broker的个数。
default.replication.factor=3
# replicas每次获取数据的最大字节数
replica.fetch.max.bytes=5242880
# broker 服务器要监听的地址及端口
listeners=PLAINTEXT://192.168.59.102:9092
# 这个是对外提供的地址 , 当client请求到kafka时, 会分发这个地址
advertised.listeners=PLAINTEXT://192.168.59.102:9092
# 处理网络请求的最大线程数
num.network.threads=8
# 处理I/O请求的线程数
num.io.threads=3
#发送缓冲区buffer大小,数据不是一下子就发送的,先会存储到缓冲区到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
# 消息日志存放的路径,建议放在容量的的磁盘
log.dirs=/home/kafka/logs
# 默认的分区数,一个topic默认1个分区
num.partitions=3
# 启停时做日志恢复每个目录所需的线程数,采用RAID的时候可以增大该值
num.recovery.threads.per.data.dir=1
# 副本数或备份因子
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
# 默认为true,启用日志清理器进程在服务器上运行
log.cleaner.enable=true
# segment文件保留的最长时间,超时则被删除,默认7天
log.retention.hours=168
# # 单个分片的上限,达到该大小后会生成新的日志分片 1G
log.segment.bytes=1073741824
# 日志分片的检测时间间隔,每隔该时间会根据log保留策略决定是否删除log分片
log.retention.check.interval.ms=300000
# zookeeper集群信息
zookeeper.connect=192.168.59.102:21810,192.168.59.103:21810,192.168.59.104:21810
# zookeeper超时时间
zookeeper.connection.timeout.ms=6000
# 在开发测试环境下该值设置为0,保证启动后马上可以使用。但在生产环境下,默认值3秒更适合
group.initial.rebalance.delay.ms=3000
同理,在103和104服务安装kafka
三台虚拟机安装好后,全部启动服务
#/usr/local/kafka_2.12-0.11.0.2/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.12-0.11.0.2/config/server.properties
查看是否启动成功
#jps
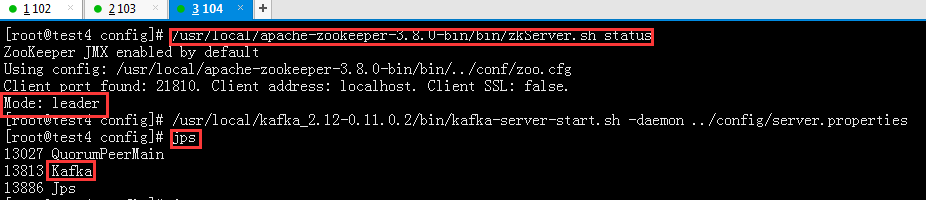
以上kafka集群搭建完成
验证测试
#在1_102窗口进行操作
#进入kafka根目录下的bin
#cd /usr/local/kafka_2.12-0.11.0.2/bin/
#创建一个test主题,分区数为3,备份数为3
#./kafka-topics.sh --create --zookeeper 192.168.59.102:21810 --replication-factor 3 --partitions 3 --topic test
#kafka根目录执行,启动一个生产者
#./kafka-console-producer.sh --broker-list 192.168.59.102:9092 --topic test

新开的4_102窗口
#启动消费者命令
#./kafka-console-consumer.sh --zookeeper 192.168.59.102:21810 --topic test --from-beginning

在1_102(生产者)窗口,输入以下信息:first second third

在4_102(消费者)窗口,可以查看到1_102输入的信息
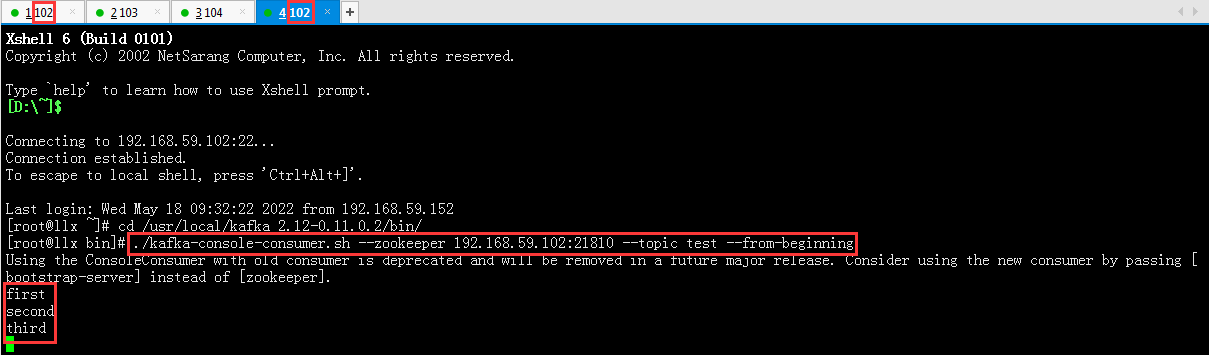
生产者发送消息,消费者接收成功。验证完成!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了