夺命雷公狗—JAVA---005---编码问题
在编写程序的时候我们是需要注意一下编码问题的,比如我们创建一个Hello.java 的文件,代码如下所示:
class Hello{ public static void main(String[] args){ System.out.println("你好"); } }
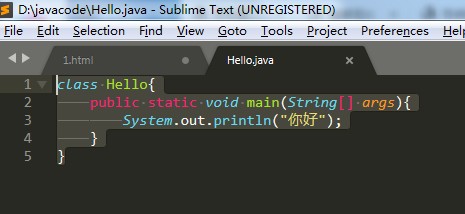
然后我们来到文件夹下进行编译和运行即可发现如下问题:
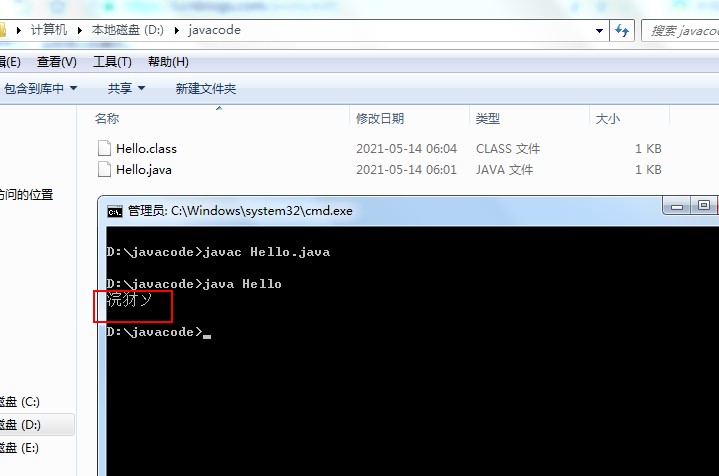
这样即可发现直接输出了一堆乱码~ ~!
问题出现点,如下所示:
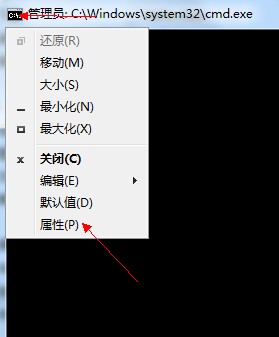
由下图可以清晰的看到,我们的系统默认是使用了GBK编码的,所以我们的代码才会直接爆出一堆乱码:
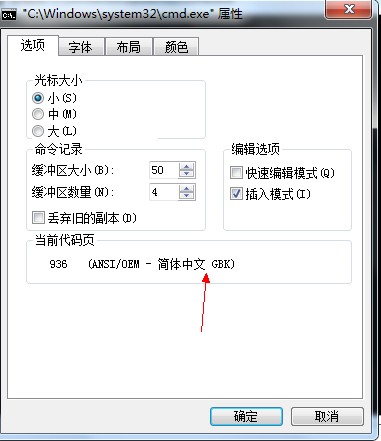
因为计算机他的世界中只是认识0和1,人类世界的字符他是很丰富的~ ~!
因为0和1这些字符人类看起来太费劲了,所以人类就创造出了ASCII码
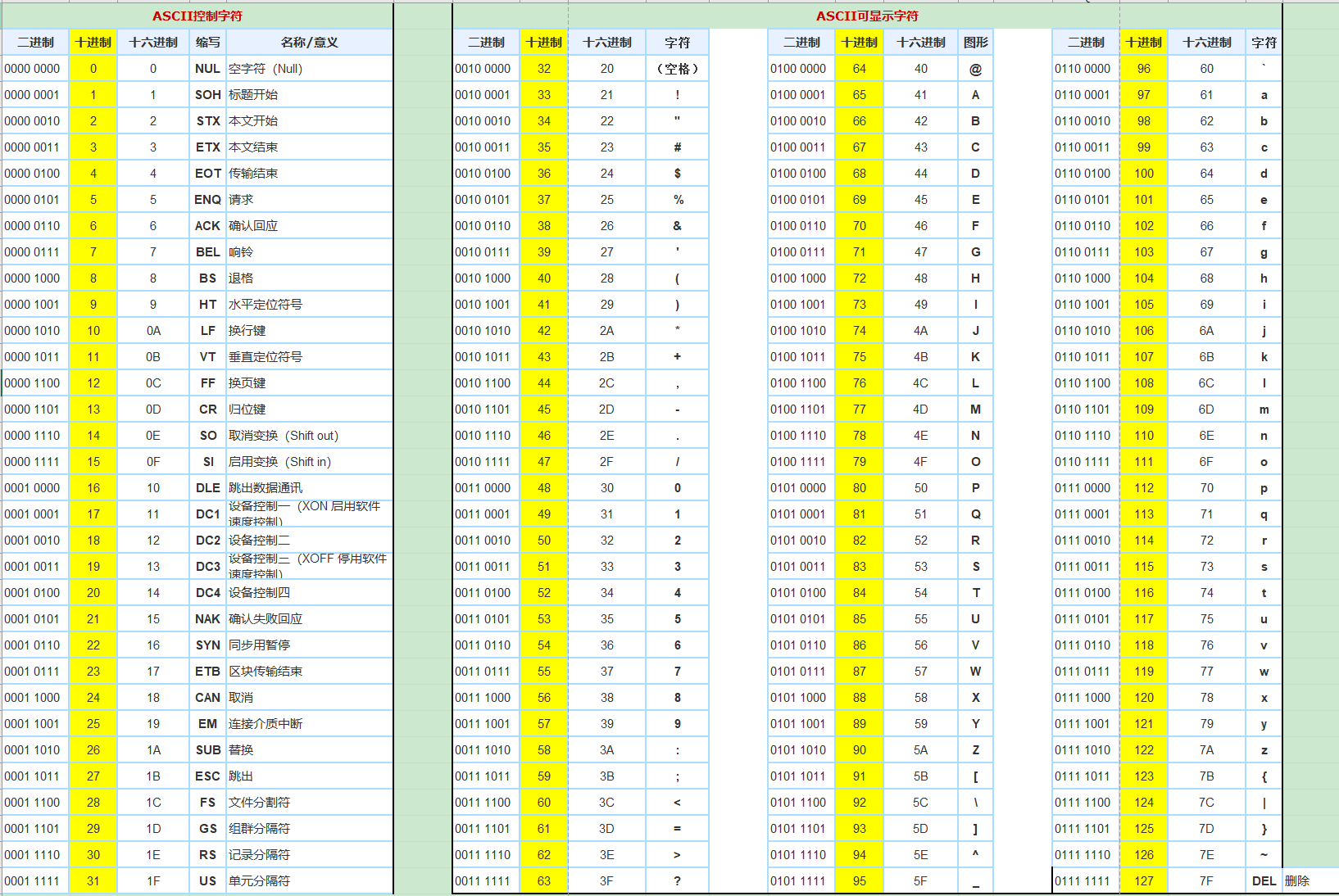
每个0和1组成的二进制代码分别可以表示不同的意义,计算机他的底层自动将二进制,十进制,十六进制等进行编译成人类能看懂的文字从而让大家可以更轻松的进行交互~ ~ !
ASCII最开始只能表示128个字符,但是计算机慢慢的发展,计算机也不仅仅是美国人的专属,慢慢的流向其他国家~ ~!
各个国家后来都慢慢的在ASCII码128个的基础上扩展了128个,从而就变成了256个,但是每个国家扩展后的ASCII后期扩展的128个是不具有通用性的。
随着计算机传入亚洲就开始出现了多字节编码了,比如我们中国所使用的的GBK2312,后来的GBK,或者中国台湾地区的Big5等等,每个地方都有自己的文字放进去。
如果不同国家的计算机为了文档传输,那么问题就会出现了~ ~!
计算机希望在全世界范围内可以无障碍交流,开始引入了万国码(Unicode编码表)
Unicode编码表,可以使用它的规则表示全世界所有的字符,每一个字符都有自己唯一的编码。
但是Unicode编码表只是说了,字符用什么数字表示,但是这个数字范围跨度太大了,有1个字节,2个字节,3个字节的,4个字节等等的。
那么在网络传说中就出现问题了,比如收到4个字节数据时,那么该表示4个字符还是1个字符呢?
后来为了解决这个传输问题,就出现了大家所知的UTF-8等编码方式,规定了到底几个字节是一个字符。
我们由于使用的是sublime,他默认是不支持gbk2312的,那么我们需要安装一个插件:
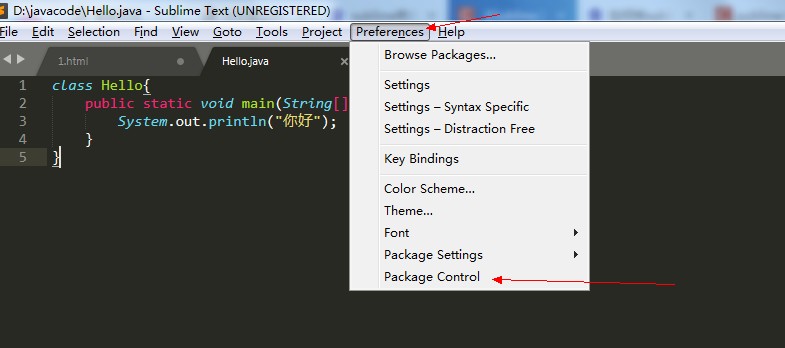
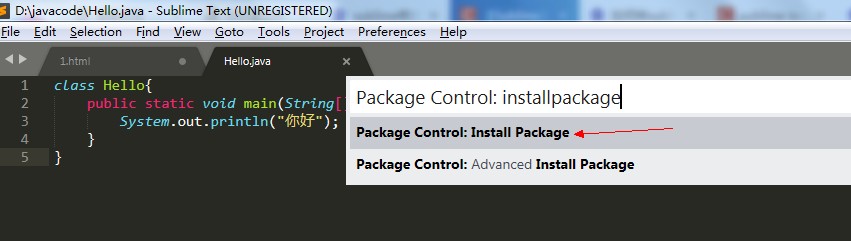
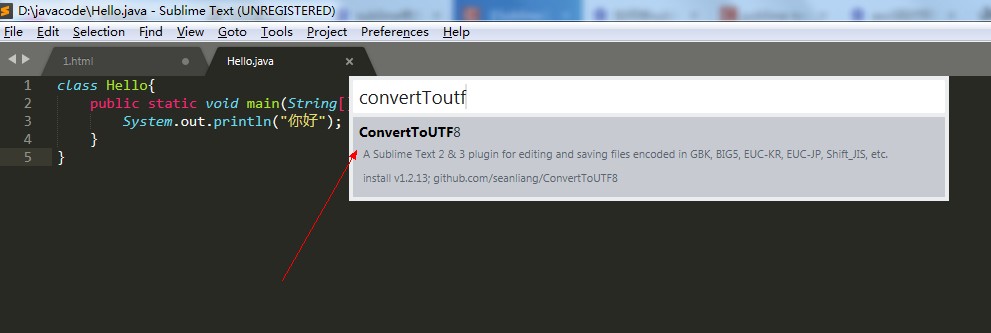
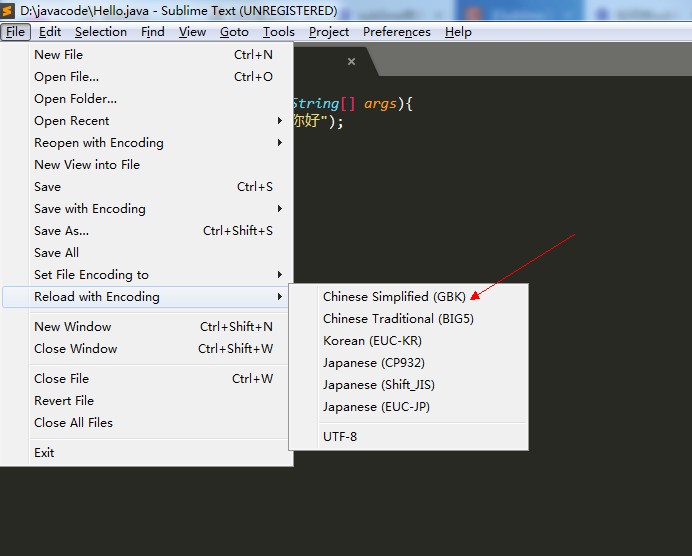
然后再来编译和执行:
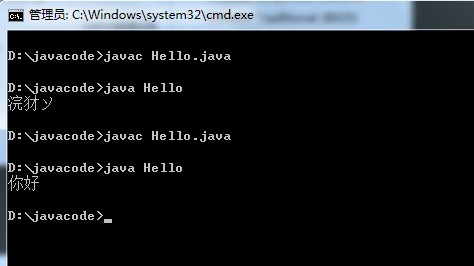
这样他就可以恢复正常了~~!
温馨提示,如果是使用nopad++编辑器,我们只需要将编码设置成 ANSI 即可,这样设置他就会自动成为与系统相同的字符进行展示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号