nginx实现高并发的原理
Nginx
首先要明白,Nginx 采用的是多进程(单线程) & 多路IO复用模型。使用了 I/O 多路复用技术的 Nginx,就成了”并发事件驱动“的服务器。
异步非阻塞(AIO)的详解http://www.ibm.com/developerworks/cn/linux/l-async/
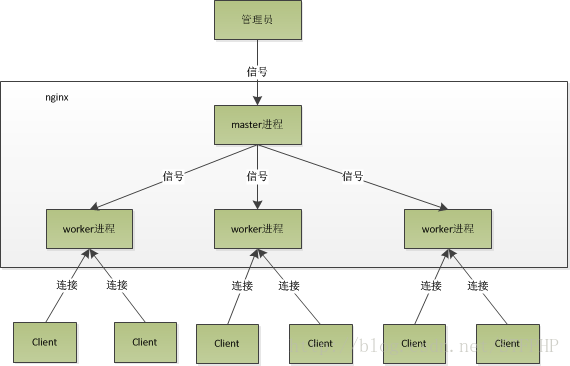
多进程的工作模式
-
1、Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程。
-
2、接收来自外界的信号,向各worker进程发送信号,每个进程都有可能来处理这个连接。
-
3、 master 进程能监控 worker 进程的运行状态,当 worker 进程退出后(异常情况下),会自动启动新的 worker 进程。
注意 worker 进程数,一般会设置成机器 cpu 核数。因为更多的worker 数,只会导致进程相互竞争 cpu,从而带来不必要的上下文切换。
使用多进程模式,不仅能提高并发率,而且进程之间相互独立,一个 worker 进程挂了不会影响到其他 worker 进程。
惊群现象
主进程(master 进程)首先通过 socket() 来创建一个 sock 文件描述符用来监听,然后fork生成子进程(workers 进程),子进程将继承父进程的 sockfd(socket 文件描述符),之后子进程 accept() 后将创建已连接描述符(connected descriptor)),然后通过已连接描述符来与客户端通信。
那么,由于所有子进程都继承了父进程的 sockfd,那么当连接进来时,所有子进程都将收到通知并“争着”与它建立连接,这就叫“惊群现象”。大量的进程被激活又挂起,只有一个进程可以accept() 到这个连接,这当然会消耗系统资源。
Nginx对惊群现象的处理
Nginx 提供了一个 accept_mutex 这个东西,这是一个加在accept上的一把共享锁。即每个 worker 进程在执行 accept 之前都需要先获取锁,获取不到就放弃执行 accept()。有了这把锁之后,同一时刻,就只会有一个进程去 accpet(),这样就不会有惊群问题了。accept_mutex 是一个可控选项,我们可以显示地关掉,默认是打开的。
Nginx进程详解
Nginx在启动后,会有一个master进程和多个worker进程。
master进程
主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。
master进程充当整个进程组与用户的交互接口,同时对进程进行监护。它不需要处理网络事件,不负责业务的执行,只会通过管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。
我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
worker进程
而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。
worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
worker进程工作流程
当一个 worker 进程在 accept() 这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,一个完整的请求。一个请求,完全由 worker 进程来处理,而且只能在一个 worker 进程中处理。
这样做带来的好处:
1、节省锁带来的开销。每个 worker 进程都是独立的进程,不共享资源,不需要加锁。同时在编程以及问题查上时,也会方便很多。
2、独立进程,减少风险。采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master 进程则很快重新启动新的 worker 进程。当然,worker 进程的也能发生意外退出。
多进程模型每个进程/线程只能处理一路IO,那么 Nginx是如何处理多路IO呢?
如果不使用 IO 多路复用,那么在一个进程中,同时只能处理一个请求,比如执行 accept(),如果没有连接过来,那么程序会阻塞在这里,直到有一个连接过来,才能继续向下执行。
而多路复用,允许我们只在事件发生时才将控制返回给程序,而其他时候内核都挂起进程,随时待命。
核心:Nginx采用的 IO多路复用模型epoll
epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树),其工作流程分为三部分:
-
1、调用 int epoll_create(int size)建立一个epoll对象,内核会创建一个eventpoll结构体,用于存放通过epoll_ctl()向epoll对象中添加进来
-
的事件,这些事件都会挂载在红黑树中。
-
2、调用 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) 在 epoll 对象中为 fd 注册事件,所有添加到epoll中的件
-
都会与设备驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个sockfd的回调方法,将sockfd添加到eventpoll 中的双链表
-
3、调用 int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) 来等待事件的发生,timeout 为 -1 时,该
-
调用会阻塞知道有事件发生
-
这样,注册好事件之后,只要有 fd 上事件发生,epoll_wait() 就能检测到并返回给用户,用户就能”非阻塞“地进行 I/O 了。
epoll() 中内核则维护一个链表,epoll_wait 直接检查链表是不是空就知道是否有文件描述符准备好了。(epoll 与 select 相比最大的优点是不会随着 sockfd 数目增长而降低效率,使用 select() 时,内核采用轮训的方法来查看是否有fd 准备好,其中的保存 sockfd 的是类似数组的数据结构 fd_set,key 为 fd,value 为 0 或者 1。)
能达到这种效果,是因为在内核实现中 epoll 是根据每个 sockfd 上面的与设备驱动程序建立起来的回调函数实现的。那么,某个 sockfd 上的事件发生时,与它对应的回调函数就会被调用,来把这个 sockfd 加入链表,其他处于“空闲的”状态的则不会。在这点上,epoll 实现了一个”伪”AIO。但是如果绝大部分的 I/O 都是“活跃的”,每个 socket 使用率很高的话,epoll效率不一定比 select 高(可能是要维护队列复杂)。
可以看出,因为一个进程里只有一个线程,所以一个进程同时只能做一件事,但是可以通过不断地切换来“同时”处理多个请求。
例子:Nginx 会注册一个事件:“如果来自一个新客户端的连接请求到来了,再通知我”,此后只有连接请求到来,服务器才会执行 accept() 来接收请求。又比如向上游服务器(比如 PHP-FPM)转发请求,并等待请求返回时,这个处理的 worker 不会在这阻塞,它会在发送完请求后,注册一个事件:“如果缓冲区接收到数据了,告诉我一声,我再将它读进来”,于是进程就空闲下来等待事件发生。
这样,基于 多进程+epoll, Nginx 便能实现高并发。
使用 epoll 处理事件的一个框架,代码转自:http://www.cnblogs.com/fnlingnzb-learner/p/5835573.html
-
for( ; ; ) // 无限循环
-
{
-
nfds = epoll_wait(epfd,events,20,500); // 最长阻塞 500s
-
for(i=0;i<nfds;++i)
-
{
-
if(events[i].data.fd==listenfd) //有新的连接
-
{
-
connfd = accept(listenfd,(sockaddr *)&clientaddr, &clilen); //accept这个连接
-
ev.data.fd=connfd;
-
ev.events=EPOLLIN|EPOLLET;
-
epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev); //将新的fd添加到epoll的监听队列中
-
}
-
else if( events[i].events&EPOLLIN ) //接收到数据,读socket
-
{
-
n = read(sockfd, line, MAXLINE)) < 0 //读
-
ev.data.ptr = md; //md为自定义类型,添加数据
-
ev.events=EPOLLOUT|EPOLLET;
-
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);//修改标识符,等待下一个循环时发送数据,异步处理的精髓
-
}
-
else if(events[i].events&EPOLLOUT) //有数据待发送,写socket
-
{
-
struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; //取数据
-
sockfd = md->fd;
-
send( sockfd, md->ptr, strlen((char*)md->ptr), 0 ); //发送数据
-
ev.data.fd=sockfd;
-
ev.events=EPOLLIN|EPOLLET;
-
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
-
}
-
else
-
{
-
//其他的处理
-
}
-
}
-
}
Nginx 与 多进程模式 Apache 的比较:
对于Nginx来讲,一个进程只有一个主线程,通过异步非阻塞的事件处理机制,实现了循环处理多个准备好的事件,从而实现轻量级和高并发。
事件驱动适合于I/O密集型服务,多进程或线程适合于CPU密集型服务:
1、Nginx 更主要是作为反向代理,而非Web服务器使用。其模式是事件驱动。
2、事件驱动服务器,最适合做的就是这种 I/O 密集型工作,如反向代理,它在客户端与WEB服务器之间起一个数据中转作用,纯粹是 I/O 操作,自身并不涉及到复杂计算。因为进程在一个地方进行计算时,那么这个进程就不能处理其他事件了。
3、Nginx 只需要少量进程配合事件驱动,几个进程跑 libevent,不像 Apache 多进程模型那样动辄数百的进程数。
5、Nginx 处理静态文件效果也很好,那是因为读写文件和网络通信其实都是 I/O操作,处理过程一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号