
Elasticsearch6.2集群搭建
Elasticsearch6.2集群搭建
版权声明:本博客为学习、笔记之用,以笔记形式记录学习的知识与感悟。学习过程中可能参考各种资料,如觉文中表述过分引用,请务必告知,以便迅速处理。如有错漏,不吝赐教。 https://blog.csdn.net/qq_34021712/article/details/79330028
原文地址,转载请注明出处:https://blog.csdn.net/qq_34021712/article/details/79330028 ©王赛超
环境介绍
| 服务器 | 是否可以成为主节点 | 是否为数据节点 |
| 192.168.8.101 | true | true |
| 192.168.8.103 | true | true |
| 192.168.8.104 | true | true |
前提是安装java环境,ELK6.2版本需要jdk为1.8,官方推荐安装OracleJDK 最好不要安装OpenJDK.安装jdk参考:linux安装jdk 只需要将安装包换成1.8的就行。
Elasticsearch安装
①解压文件
tar -zxvf elasticsearch-6.2.1.tar.gzmv elasticsearch-6.2.1 /usr/local/elk/elasticsearchmkdir /usr/local/elk/elasticsearch/datamkdir /usr/local/elk/elasticsearch/logs-
#添加用户
-
useradd es
-
#赋予文件夹权限
-
chown -R es:es /usr/local/elk/elasticsearch
vim /usr/local/elk/elasticsearch/config/elasticsearch.yml 将配置文件以下内容进行修改:
-
#集群的名称
-
cluster.name: es6.2
-
#节点名称,其余两个节点分别为node-2 和node-3
-
node.name: node-1
-
#指定该节点是否有资格被选举成为master节点,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master
-
node.master: true
-
#允许该节点存储数据(默认开启)
-
node.data: true
-
#索引数据的存储路径
-
path.data: /usr/local/elk/elasticsearch/data
-
#日志文件的存储路径
-
path.logs: /usr/local/elk/elasticsearch/logs
-
#设置为true来锁住内存。因为内存交换到磁盘对服务器性能来说是致命的,当jvm开始swapping时es的效率会降低,所以要保证它不swap
-
bootstrap.memory_lock: true
-
#绑定的ip地址
-
network.host: 0.0.0.0
-
#设置对外服务的http端口,默认为9200
-
http.port: 9200
-
# 设置节点间交互的tcp端口,默认是9300
-
transport.tcp.port: 9300
-
#Elasticsearch将绑定到可用的环回地址,并将扫描端口9300到9305以尝试连接到运行在同一台服务器上的其他节点。
-
#这提供了自动集群体验,而无需进行任何配置。数组设置或逗号分隔的设置。每个值的形式应该是host:port或host
-
#(如果没有设置,port默认设置会transport.profiles.default.port 回落到transport.tcp.port)。
-
#请注意,IPv6主机必须放在括号内。默认为127.0.0.1, [::1]
-
discovery.zen.ping.unicast.hosts: ["192.168.8.101:9300", "192.168.8.103:9300", "192.168.8.104:9300"]
-
#如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 - 分裂的大脑 - 这将导致数据丢失
-
discovery.zen.minimum_master_nodes: 3
grep '^[a-z]' /usr/local/elk/elasticsearch/config/elasticsearch.yml
⑦调整jvm内存
-
vim /usr/local/elk/elasticsearch/config/jvm.options
-
#默认是1g官方建议对jvm进行一些修改,不然很容易出现OOM,参考官网改参数配置最好不要超过内存的50%
-
-Xms1g
-
-Xmx1g
分别启动三台Elasticsearch
注意:请使用es用户启动 su - es
![]()
第一个坑:日志文件会以集群名称命名,查看es6.2.log文件,日志报以下异常:
切回root用户su - root,修改配置
注意:请使用es用户启动 su - es
/usr/local/elk/elasticsearch/bin/elasticsearch -d
第一个坑:日志文件会以集群名称命名,查看es6.2.log文件,日志报以下异常:
-
[2018-02-14T23:40:16,908][ERROR][o.e.b.Bootstrap ] [node-1] node validation exception
-
[3] bootstrap checks failed
-
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
-
[2]: memory locking requested for elasticsearch process but memory is not locked
-
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
-
[2018-02-14T23:40:16,910][INFO ][o.e.n.Node ] [node-1] stopping ...
-
[2018-02-14T23:40:17,016][INFO ][o.e.n.Node ] [node-1] stopped
-
[2018-02-14T23:40:17,016][INFO ][o.e.n.Node ] [node-1] closing ...
-
[2018-02-14T23:40:17,032][INFO ][o.e.n.Node ] [node-1] closed
切回root用户su - root,修改配置
① vim /etc/security/limits.conf
-
* soft nofile 65536
-
* hard nofile 65536
-
* soft nproc 2048
-
* hard nproc 4096
-
#我选择锁住swapping因此需要在这个配置文件下再增加两行代码
-
es soft memlock unlimited
-
es hard memlock unlimited
② vim /etc/sysctl.conf
-
vm.max_map_count=655360
-
fs.file-max=655360
再次重启三台Elasticsearch
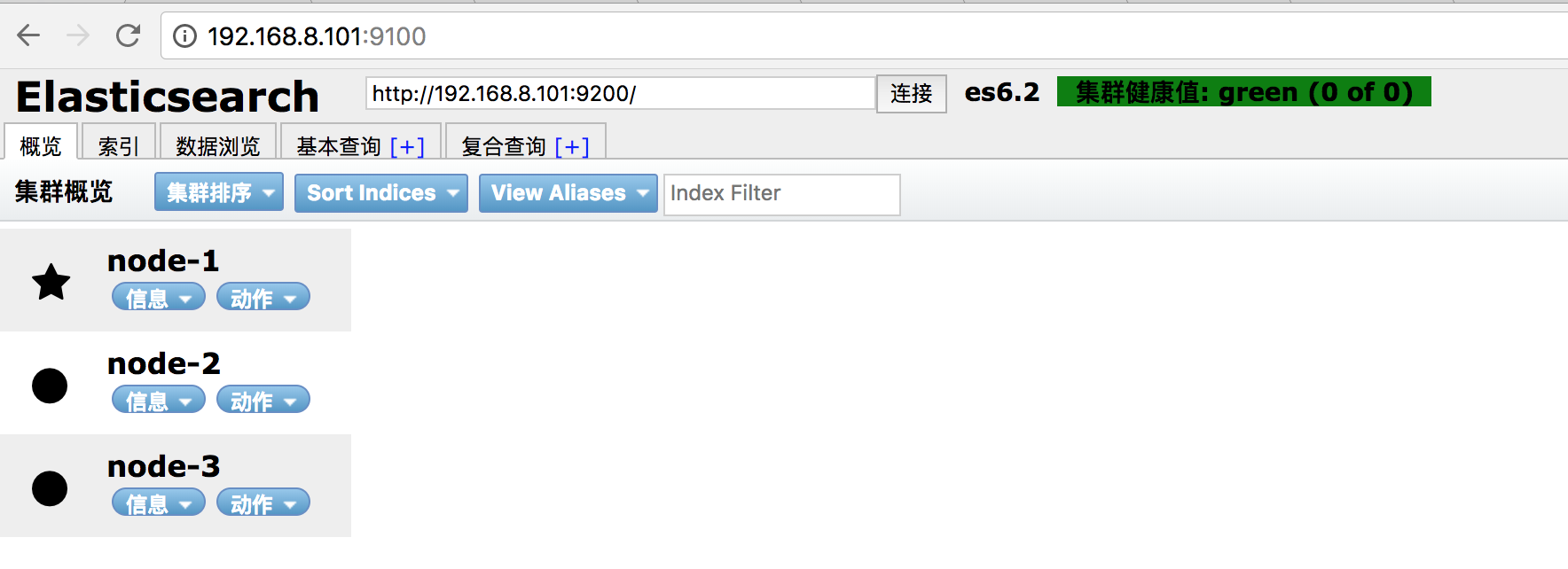
使用ps -ef|grep elasticsearch进程查看命令已启动,使用netstat -ntlp查看9200端口也被占用了。
但是我们发现,3个节点都正常started了,但是就是无法形成集群,使用Elasticsearch Head插件缺发现没有连接上集群,
但是我们发现,3个节点都正常started了,但是就是无法形成集群,使用Elasticsearch Head插件缺发现没有连接上集群,
Head插件安装参考:Elasticsearch-head插件安装
第二个坑:查看日志报以下错误:
关于discovery.zen.minimum_master_nodes参数介绍,参考:
再次启动
第二个坑:查看日志报以下错误:
-
[2018-02-15T21:15:06,352][INFO ][rest.suppressed ] /_cat/health Params: {h=node.total}
-
MasterNotDiscoveredException[waited for [30s]]
-
at org.elasticsearch.action.support.master.TransportMasterNodeAction$4.onTimeout(TransportMasterNodeAction.java:160)
-
at org.elasticsearch.cluster.ClusterStateObserver$ObserverClusterStateListener.onTimeout(ClusterStateObserver.java:239)
-
at org.elasticsearch.cluster.service.InternalClusterService$NotifyTimeout.run(InternalClusterService.java:630)
-
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
-
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
-
at java.lang.Thread.run(Thread.java:745)
关于discovery.zen.minimum_master_nodes参数介绍,参考:
再次启动
第三个坑:使用Head插件查看,发现只有192.168.8.101为主节点,其他两个节点并没有连接上来,查看日志发现报以下异常
[2018-02-15T21:53:58,084][INFO ][o.e.d.z.ZenDiscovery ] [node-3] failed to send join request to master [{node-1}{SVrW6URqRsi3SShc1PBJkQ}{y2eFQNQ_TRenpAPyv-EnVg}{192.168.8.101}{192.168.8.101:9300}], reason [RemoteTransportException[[node-1][192.168.8.101:9300][internal:discovery/zen/join]]; nested: IllegalArgumentException[can't add node {node-3}{SVrW6URqRsi3SShc1PBJkQ}{uqoktM6XTgOnhh5r27L5Xg}{192.168.8.104}{192.168.8.104:9300}, found existing node {node-1}{SVrW6URqRsi3SShc1PBJkQ}{y2eFQNQ_TRenpAPyv-EnVg}{192.168.8.101}{192.168.8.101:9300} with the same id but is a different node instance]; ]再次重新启动,成功!
![]()
技术改变一切

 浙公网安备 33010602011771号
浙公网安备 33010602011771号