索引以及索引缓冲区
什么是索引呢?为什么需要索引呢?
在“顶点与顶点缓冲区”中,我们介绍了关于顶点的概念。GPU在拿到了顶点数据以后,需要将这些顶点绘制成为三角形,
但是,GPU却不知道要将这些顶点怎么样组合成为一个个的三角形,因为组合的可能有多种多样,并不唯一,因此我们
需要使用索引数据来告诉GPU,如何将这些顶点绘制成为三角形。
假设现在有四个点,组成两个三角形。点分为别为 P0,P1,P2,P3
对应的索引数据为[0,1,2,2,3,0].也就是说,点P0,P1,P2组合成为一个三角形,点P2,P3,P0组合成为第二个三角形。
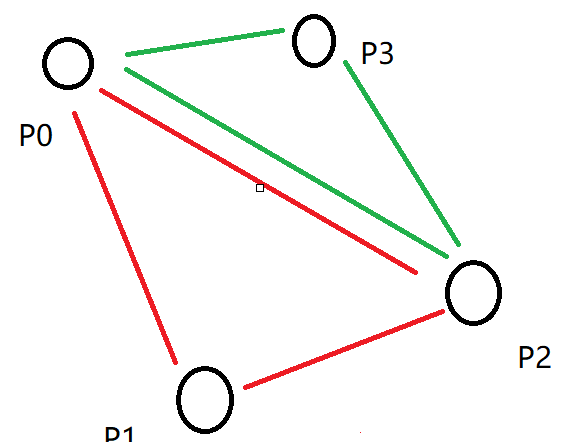
同时,根据三角形索引数据的顺序,也就能够确认三角形的法线了。
DX习惯顺时针为正方向
OpenGL则习惯逆时针为正方向
将一个模型的索引数据,装入一个容器中,然后上传给GPU处理,这里的容器,就是所谓的索引缓冲区。
在一些低端设备上,它最多能够支持的索引数量是有限的,为65535个。如果遇到这样的设备,就需要
做索引数据拆分。
索引也可以合并上传给GPU,这样能节约性能,那么如何合并索引数据呢?
假设:
A模型 顶点数据为[P0,P1,P2]
A模型 索引数据为[0,1,2]
B模型 顶点数据为[P3,P4,P5]
B模型 索引数据为[0,1,2]
合并顶点数据为[P0,P1,P2,P3,P4,P5]
合并索引数据为[0,1,2,(0+3),(1+3),(2+3)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号