索引底层实现原理
要了解数据库索引的底层原理,我们就得先了解一种叫树的数据结构,而树中很经典的一种数据结构就是二叉树!所以下面我们就从二叉树到平衡二叉树,再到B-树,最后到B+树来一步一步了解数据库索引底层的原理!
二叉树(Binary Search Trees)
二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树有如下特性:
1、每个结点都包含一个元素以及n个子树,这里0≤n≤2。
2、左子树和右子树是有顺序的,次序不能任意颠倒。左子树的值要小于父结点,右子树的值要大于父结点
平衡二叉树 (AVL Trees)
平衡二叉树是一种特殊的二叉树,所以他也满足前面说到的二叉树的两个特性,同时还有一个特性:
它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
B-Tree
这颗矮胖的树就是B-Tree,注意中间是杠精的杠而不是减,所以也不要读成B减Tree了~
那B-Tree有哪些特性呢?一棵m阶的B-Tree有如下特性:
1、每个结点最多m个子结点。
2、除了根结点和叶子结点外,每个结点最少有m/2(向上取整)个子结点。
3、如果根结点不是叶子结点,那根结点至少包含两个子结点。
4、所有的叶子结点都位于同一层。
5、每个结点都包含k个元素(关键字),这里m/2≤k<m,这里m 2向下取整。
7、每个元素(关键字)字左结点的值,都小于或等于该元素(关键字)。右结点的值都大于或等于该元素(关键字)。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构。B+Tree与B-Tree的结构很像,但是也有几个自己的特性:
1、所有的非叶子节点只存储关键字信息。
2、所有卫星数据(具体数据)都存在叶子结点中。
3、所有的叶子结点中包含了全部元素的信息。
4、所有叶子节点之间都有一个链指针。
Hash数据结构存储
在mysql中建立索引的时候,可以选择是用hash,还是B+Tree.Hash是这样的,当你存入索引的时候会通过hash算法生成一个hashCode,在存入内存的时候就将你的这个hashCode和地址指针配对存入。这样做的好处就是当你在查询的时候,能够快速的定位,根本不需要去比较查找,只要根据这个值通过hash算法就可以找到你要的数据了。但是这种结构在实际应用中基本上是很少用的(至少我是没遇到过),为什么呢?因为在实际的应用中我们的sql语句查询用的比较多的是范围查找而不是精准定位。
综上所述,B+Tree成为了mysql,oracle等数据库的底层数据结构的不二之选。
聚集(clustered)索引,也叫聚簇索引。
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
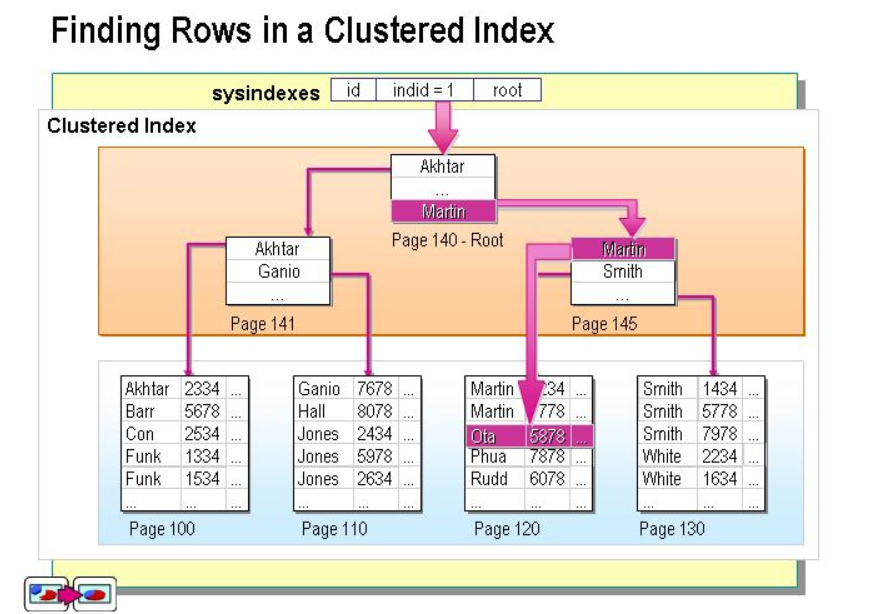
聚集索引实际存放的示意图
从上图可以看出聚集索引的好处了,索引的叶子节点就是对应的数据节点(MySQL的MyISAM除外,此存储引擎的聚集索引和非聚集索引只多了个唯一约束,其他没什么区别),可以直接获取到对应的全部列的数据,而非聚集索引在索引没有覆盖到对应的列的时候需要进行二次查询,后面会详细讲。因此在查询方面,聚集索引的速度往往会更占优势。
非聚集索引
非聚集(unclustered)索引。
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如果非要把非聚集索引类比成现实生活中的东西,那么非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致
非聚集索引叶子节点还是索引节点。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据,如下图
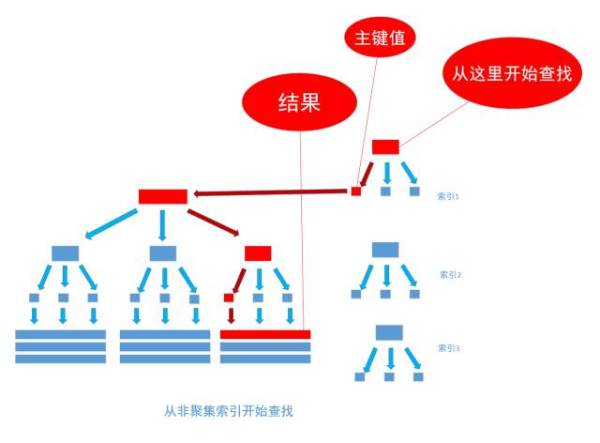
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
如果查询的字段中包含了其它索引中不存在的字段,那么就会进行二次查询。
其它详情参考:https://www.cnblogs.com/s-b-b/p/8334593.html https://www.cnblogs.com/yatou-blog/articles/lipingyatou.html
本文来自博客园,作者:风光小磊,转载请注明原文链接:https://www.cnblogs.com/lei-z/p/15839133.html
