摘要:
名称 Hudi Paimon Iceberg Delta Lake 安装依赖 基础:JavaHudi依赖于Apache Hadoop和Apache Spark 基础:Java集群:Hadoop、Zookeeper 基础:Java 基础:Java Docker 部署 可Docker 部署 ACID 事 阅读全文
摘要:
传统离线大数据架构 21世纪初随着互联网时代的到来,数据量暴增,大数据时代到来。Hadoop生态群及衍生技术慢慢走向“舞台”,Hadoop是以HDFS为核心存储,以MapReduce(简称MR)为基本计算模型的批量数据处理基础设施,围绕HDFS和MR,产生了一系列的组件,不断完善整个大数据平台的 阅读全文
摘要:  集合工厂 List<String> friends = Arrays.asList("Raphael", "Olivia"); friends.set(0, "Richard"); friends.add("Thibaut"); ← 抛出一个UnsupportedModificationExcept 阅读全文
集合工厂 List<String> friends = Arrays.asList("Raphael", "Olivia"); friends.set(0, "Richard"); friends.add("Thibaut"); ← 抛出一个UnsupportedModificationExcept 阅读全文
集合工厂 List<String> friends = Arrays.asList("Raphael", "Olivia"); friends.set(0, "Richard"); friends.add("Thibaut"); ← 抛出一个UnsupportedModificationExcept 阅读全文
摘要:
第6章 用Collectors类创建和使用收集器 将数据流归约为一个值 汇总:归约的特殊情况 数据分组和分区 开发你的自定义收集器 对一个交易列表按货币分组,获得该货币的所有交易额总和(返回一个Map<Currency, Integer>)。 将交易列表分成两组:贵的和不贵的(返回一个Map<Boo 阅读全文
摘要:
PostgreSQL中除IN多参数写法 之 ANY[ARRAY] Postgresql的in条件查询默认最大参数个数1000 PostgreSQL对于”IN”条件中的参数数量有一定的限制。 这个限制是由可配置的参数 max_expr 控制的 unnest 函数用于将数组展开成一个或多个元素的行集。它 阅读全文
摘要: 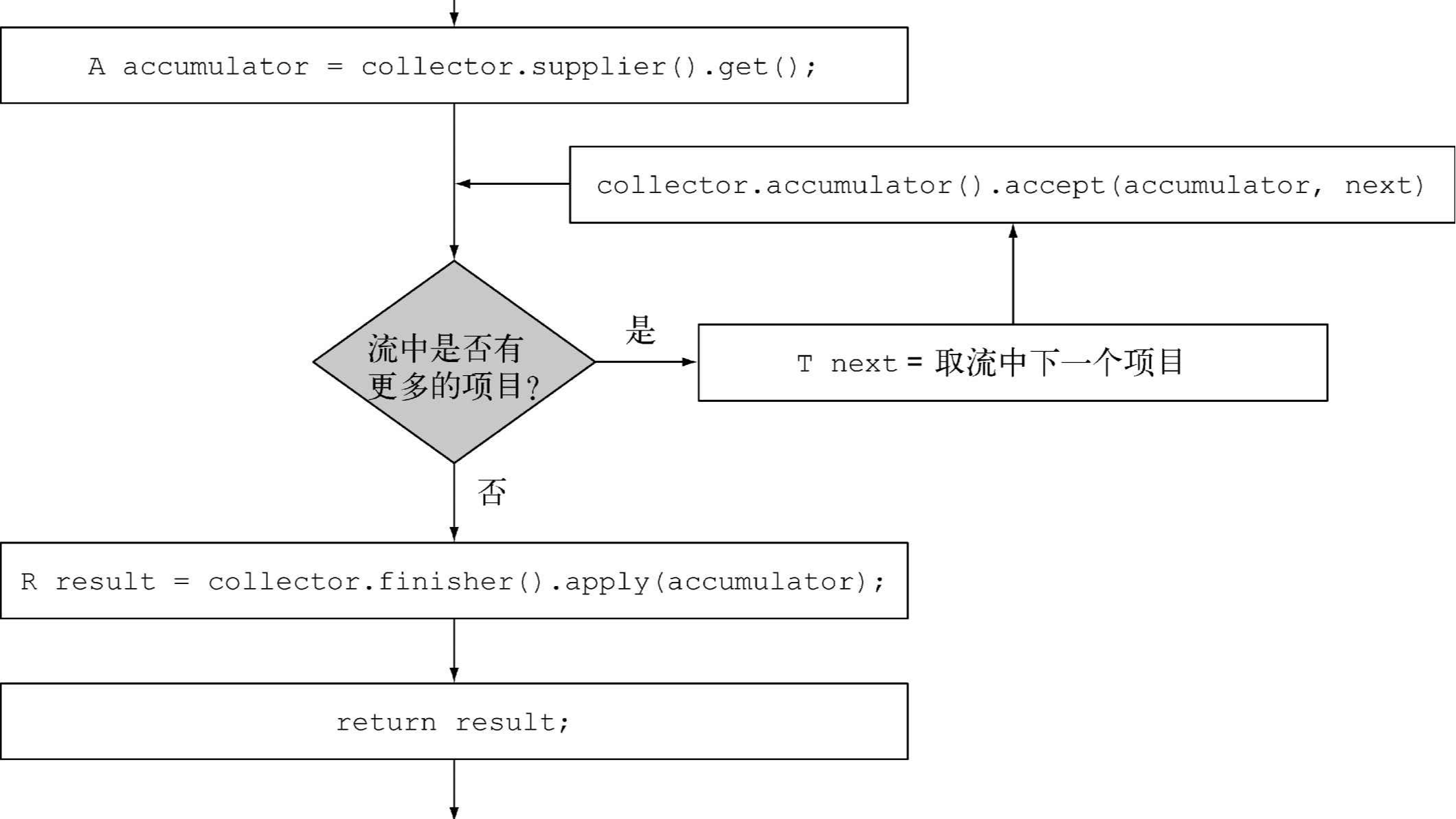 第6章 用Collectors类创建和使用收集器 将数据流归约为一个值 汇总:归约的特殊情况 数据分组和分区 开发你的自定义收集器 对一个交易列表按货币分组,获得该货币的所有交易额总和(返回一个Map<Currency, Integer>)。将交易列表分成两组:贵的和不贵的(返回一个Map<Bool 阅读全文
第6章 用Collectors类创建和使用收集器 将数据流归约为一个值 汇总:归约的特殊情况 数据分组和分区 开发你的自定义收集器 对一个交易列表按货币分组,获得该货币的所有交易额总和(返回一个Map<Currency, Integer>)。将交易列表分成两组:贵的和不贵的(返回一个Map<Bool 阅读全文
第6章 用Collectors类创建和使用收集器 将数据流归约为一个值 汇总:归约的特殊情况 数据分组和分区 开发你的自定义收集器 对一个交易列表按货币分组,获得该货币的所有交易额总和(返回一个Map<Currency, Integer>)。将交易列表分成两组:贵的和不贵的(返回一个Map<Bool 阅读全文
摘要:  第 4 章 引入流 流可以认为是遍历数据集的高级迭代器。 流还可以透明地并行处理,无须写任何多线程代码 代码是以声明性方式写 可以把几个基础操作链接起来,来表达复杂的数据处理流水线(在filter后面接上sorted、map和collect操作 filter、sorted、map和collect等操 阅读全文
第 4 章 引入流 流可以认为是遍历数据集的高级迭代器。 流还可以透明地并行处理,无须写任何多线程代码 代码是以声明性方式写 可以把几个基础操作链接起来,来表达复杂的数据处理流水线(在filter后面接上sorted、map和collect操作 filter、sorted、map和collect等操 阅读全文
第 4 章 引入流 流可以认为是遍历数据集的高级迭代器。 流还可以透明地并行处理,无须写任何多线程代码 代码是以声明性方式写 可以把几个基础操作链接起来,来表达复杂的数据处理流水线(在filter后面接上sorted、map和collect操作 filter、sorted、map和collect等操 阅读全文
摘要:  1、基础知识 第 1 章 Java 8、9、10以及11的变化 方法引用 Lmbada表达式 static List<Apple> filterApples(List<Apple> inventory,Predicate<Apple> p) { ← 方法作为Predicate参数p传递进去(见附注栏 阅读全文
1、基础知识 第 1 章 Java 8、9、10以及11的变化 方法引用 Lmbada表达式 static List<Apple> filterApples(List<Apple> inventory,Predicate<Apple> p) { ← 方法作为Predicate参数p传递进去(见附注栏 阅读全文
1、基础知识 第 1 章 Java 8、9、10以及11的变化 方法引用 Lmbada表达式 static List<Apple> filterApples(List<Apple> inventory,Predicate<Apple> p) { ← 方法作为Predicate参数p传递进去(见附注栏 阅读全文
摘要:
- ``` pg_wal文件过多过大 ``` - 如果 PostgreSQL 中的 `pg_wal` 文件过多或过大,可能是由于以下原因: 1. 数据库写入负载过大:如果你的数据库有大量的写入操作,会导致 `pg_wal` 文件的增长速度很快。 2. 备份和复制延迟:如果你的数据库设置了基于 WAL 阅读全文
摘要:
## 发布主题 ### 设置发布为true 这个语句是针对 PostgreSQL 数据库中的逻辑复制功能中的逻辑发布(Logical Publication)进行设置的。 PostgreSQL 中,逻辑复制是一种基于逻辑日志的复制方法,允许将数据更改从一个数据库实例复制到另一个数据库实例,而不是通过 阅读全文