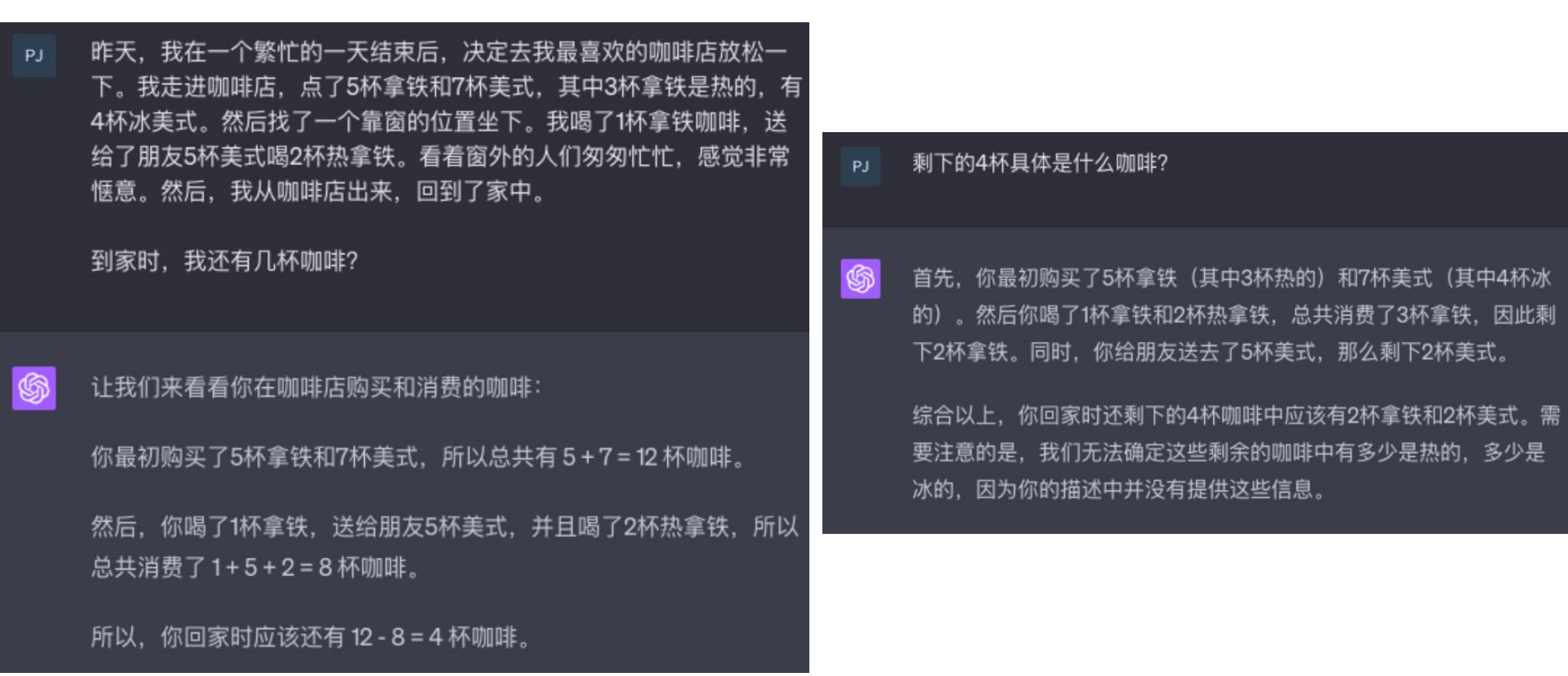
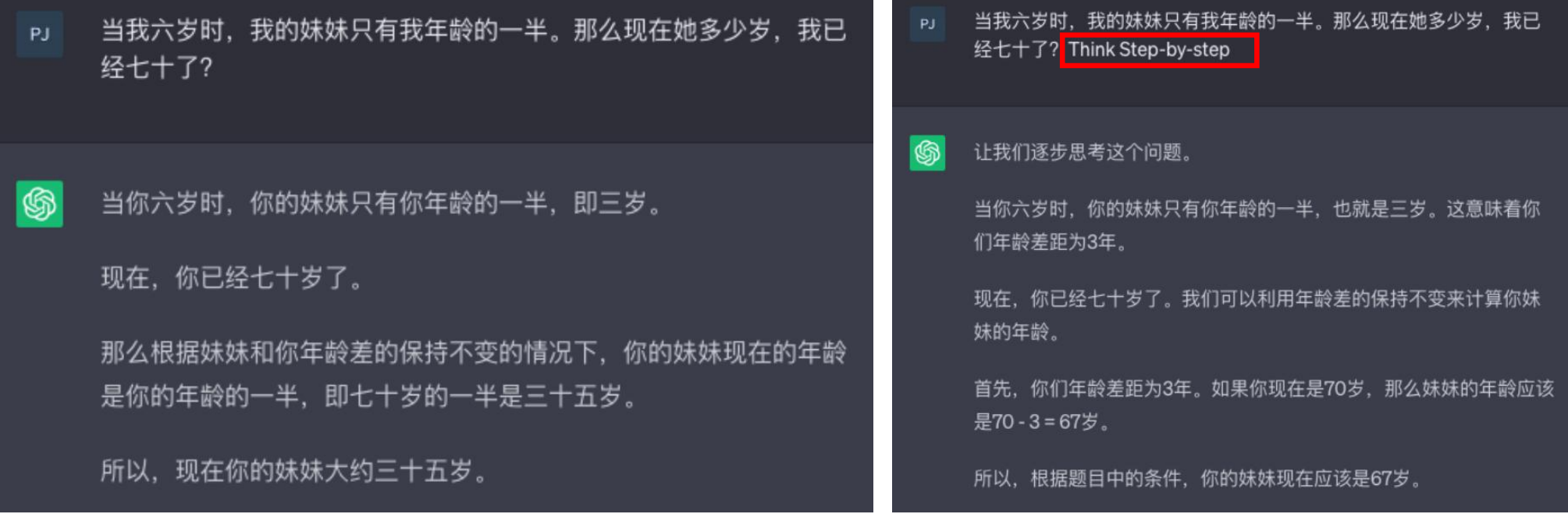
01.大模型起源与发展
知识点
- 注意力机制(Attention)的主要用途是什么?
- 选择重要的信息并忽略不相关的信息
- Transformer 模型是基于什么理论构建的?
- C. 注意力机制(Attention)
- GPT 和 BERT 的主要区别是什么?
- C. GPT 使用了单向自注意力,而 BERT 使用了双向自注意力
- 在注意力机制中,“Q”、“K”和“V”分别代表什么?
- 查询、密钥和值
- Transformer 模型是如何解决长距离依赖问题的?
- 通过注意力机制(Attention)
- GPT 主要用于哪种类型的任务?(ChatGPT =N*Agent+chat-4)
- 生成任务
- 以下哪项是 BERT 的主要创新之处
- 使用了双向自注意力机制
- 在 Transformer 模型中,自注意力机制的主要作用是什么?
- 识别输入中的关键信息
- 基于 Transformer 的模型,如 GPT 和 BERT,主要适用于哪些任务?
- 自然语言处理
- 注意力机制最早是在哪个领域得到应用的?
- 自然语言处理
- 以下哪些方法被用于处理序列数据?
- 递归神经网络(RNN)
- 卷积神经网络(CNN)
- 注意力机制(Attention)
- 以下哪些模型使用了注意力机制?
- BERT
- GPT
- 以下哪些模型主要用于自然语言处理任务?
- GPT
- BERT
- 下列哪些说法正确描述了注意力机制的作用?
- 它可以用来挑选出重要的信息并忽略不相关的信息
- 它可以用来生成高质量的词嵌入
- 下列哪些说法正确描述了 BERT 模型?
- BERT 模型是基于 Transformer 的
- BERT 模型使用了双向自注意力机制
- Bert 是基于编码器,GPT 是基于解码器,不是编码和解码一块用吗?
- BERT(Bidirectional Encoder Representations from Transformers)和 GPT(Generative Pretrained Transformer)确实分别采用了基于编码器和解码器的结构,但他们的运用方式有所不同。
- BERT 利用了 Transformer 中的编码器结构,编码器能够处理输入序列的所有元素,然后输出一个新的已经被处理过的序列。最重要的是,编码器在处理序列的时候是双向的,也就是说,在处理某个元素时,它会同时考虑到该元素的上下文,包括它前面和后面的元素。这就使得 BERT 在处理自然语言处理任务时,具有更好的上下文理解能力。
- 而 GPT 则采用了 Transformer 中的解码器结构,这个结构通常被用于生成序列。与编码器不同的是,解码器在处理序列的时候是单向的,即在处理某个元素时,只会考虑到该元素之前的元素,不会考虑到后面的元素。这就使得 GPT 非常适合用于生成型的自然语言处理任务,如文本生成、对话系统等。
- 编码和解码一块使用,通常出现在 seq2seq(序列到序列)模型中,例如机器翻译或者文本摘要等任务,输入序列首先通过编码器处理,然后解码器生成输出序列。这种模式并没有在 BERT 或 GPT 中直接使用,而是被一些其它的模型,如 T5 或 BART 所使用。
NLP 语言模型技术发展一览
| 阶段 | 时间 | 代表性成果 | 数据规模 | 技术栈 |
|---|---|---|---|---|
| 人工规则 | 1950年代-1990年代 | 基于手工设计的规则系统 | 少量规则集 | 基于专家知识和规则的系统 |
| 统计机器学习 | 1990年-2012年 | HMM, CTF, SVM | 百万级 标注数据 | 统计机器学习算法 |
| 深度学习 | 2013年-2018年 | Encoder-Decoder Word2vec, Attention | 十亿级 标注数据 | 深度神经网络 + 框架 |
| 预训练 | 2018年-2020年 | Transformer. ELMo. GPT-1, BERT, GPT-2, GPT-3 | 数千亿 未标注数据 | Pre-training + Fine-tuning |
| 大语言模型 | 2020年一至今 | GPT-3.5,GPT-4,GPT-4o | 更大规模用户数据 | Instruction-tuning Prompt-tuning RLHF |
预训练语言模型 (Pre-trained language models)
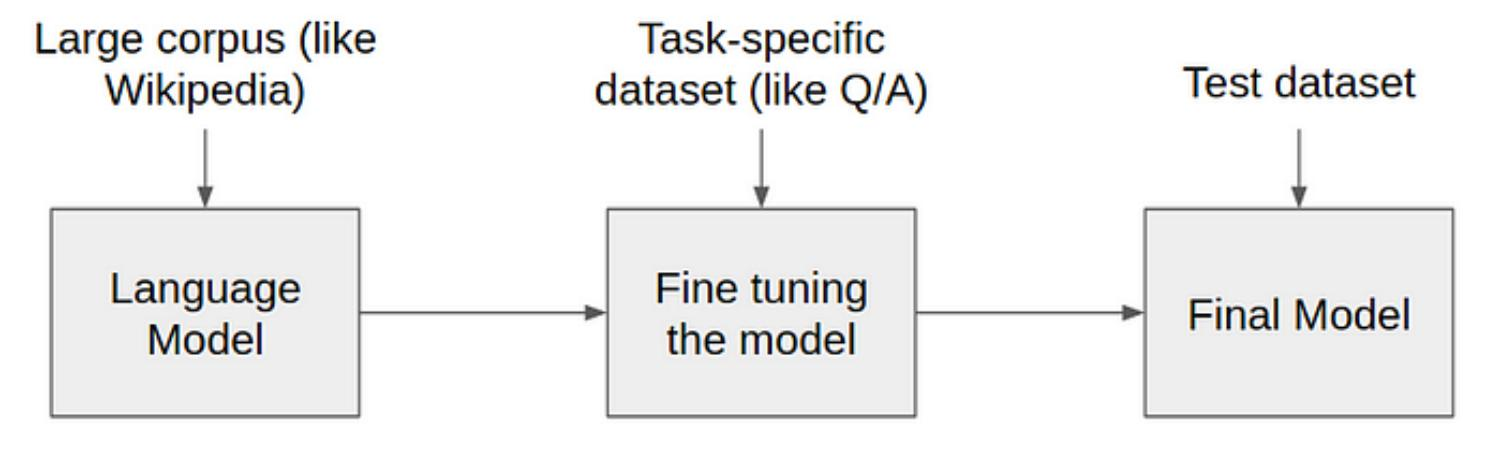
预训练语言模型的三种网络架构(2018-2020)

生成式预训练转换器 (GPT-1) [Radford等人,2018 年]
半监督序列学习 context2Vec 预训练的 seq2seq
已公开信息 GPT 3 参数为175B参数
三个关键概念
In-Context Learning
在上下文中学习指的是大型语言模型如GPT-3的一种能力,即在给定的上
下文中使用新的输入来改善模型的输出。这种学习方式并不涉及到梯度更新或微调模型的参数,
而是通过提供一些具有特定格式或结构的示例输入,使模型能够在生成输出时利用这些信息。例
如,如果你在对话中包含一些英法翻译的例子,然后问模型一个新的翻译问题,模型可能会根据
你提供的上下文示例生成正确的翻译。
Few-Shot Learning
少样本学习是指用极少量的标注样本来训练机器学习模型的技术。在GPT- 3的案例中,少样本学习的实现方式是向模型提供少量的输入-输出对示例,这些示例作为对话的
一部分,描述了模型应该执行的任务。然后,模型会生成一个输出,该输出是对与示例类似的新
输入的响应。例如,你可以给模型提供几个英法翻译的例子,然后给出一个新的英文单词让模型
翻译,模型会尝试产生一个正确的翻译。
Prompt Engineering
提示工程是指设计和优化模型的输入提示以改善模型的输出。在大型语言
模型中,如何提问或构造输入的方式可能对模型的输出有重大影响。因此,选择正确的提示对于
获取有用的输出至关重要。例如,为了让GPT-3生成一个诗歌,你可能需要提供一个详细的、引
导性的提示,如“写一首关于春天的十四行诗”而不仅仅是“写诗”
Pre-Trained LM + Fine-Tuning 范式
模型预训练与微调
在 GPT 模型的演进过程中,OpenAI 采用了一系列的训练策略,这包括基础的大规模预训练,也包括后
续的指令微调等方法。这两种策略在模型的训练过程中起到了不同的作用。
• 预训练(Pre-Trained):大规模预训练是为了使模型获取丰富的语言知识和理解能力。在预训练过程
中,模型通过大量的无标签数据来学习语言的基础知识,这一过程主要是依赖无监督学习的。
• 指令微调(Instruction-Tuning):在预训练模型的基础上,通过针对特定任务的标注数据进行微调,
能够使模型在特定任务上的表现得到提升。同时,通过对微调数据的精心设计和选择,还能够引导模
型按照人类的预期来执行任务。这一过程主要依赖有监督学习。
在这个过程中,预训练和微调是相辅相成的。预训练为模型提供了丰富的语言知识,而微调则利用这些
知识来解决特定的任务。然而,微调的数据量通常比预训练的数据量要少得多,因此微调的主要作用并
不是为模型注入新的知识,而是激发和引导模型利用已有的知识来完成特定任务。
在GPT模型的演进过程中,OpenAI还探索了多种微调策略,例如GPT-3.5的分化技能树等。这些微调策
略能够帮助模型在不同的任务上表现得更好,同时也使模型的输出更符合人类的预期。
此外,OpenAI还注意到,模型在进行微调时可能会出现一些问题,例如数据稀疏性、灾难遗忘、资源
浪费和通用性差等。为了解决这些问题,OpenAI提出了一种新的训练策略,即提示学习。通过设计提
示信息,可以激发预训练大模型的能力,从而提高模型在具体任务上的表现。
:::info
现常见可落地方式为本地大模型+RAG、第三方大模型+RAG、微调大模型私有化部署、构建大模型
:::
ChatGPT三段训练法
提示工程
Prompt Learning vs In-context Learning
**Prompt learning **是一种使用预训练语言模型的方法,它不会修改模型的权重。在这种方法中,模型
被给予一个提示(prompt),这个提示是模型输入的一部分,它指导模型产生特定类型的输出。这
个过程不涉及到对模型权重的修改,而是利用了模型在预训练阶段学习到的知识和能力。
**In-context learning **是指模型在处理一系列输入时,使用前面的输入和输出作为后续输入的上下
文。这是Transformer模型(如GPT系列)的一种基本特性。例如,当模型在处理一个对话任务时,
它会使用对话中的前几轮内容作为上下文,来生成下一轮的回答。这个过程也不涉及到对模型权重的
修改。
总的来说,prompt learning和in-context learning都是利用预训练语言模型的方法,它们都不会修改模
型的权重。它们的主要区别在于,prompt learning关注的是如何通过设计有效的提示来引导模型的输
出,而in-context learning则关注的是如何利用输入序列中的上下文信息来影响模型的输出
Prompt Learning vs Prompt Tuning
Prompt learning和prompt tuning都是自然语言处理(NLP)中的概念,它们都与如何使用和优化预
训练语言模型(例如GPT-3或GPT-4)有关。
•** Prompt learning**:是一种方法,其中模型被训练以响应特定的提示(prompt)。在这种情况下,
提示是模型输入的一部分,它指导模型产生特定类型的输出。例如,如果你向模型提供了"Translate
the following English text to French: {text}"这样的提示,模型就会学习到这是一个翻译任务,并尝试
将{text}从英语翻译成法语。这种方法的关键在于找到能够引导模型正确响应的有效提示。
• Prompt tuning,又称为"prompt engineering",是一种优化技术,它涉及到寻找或生成能够最大限
度提高模型性能的提示。这可能涉及到使用启发式方法、人工智能搜索算法,或者甚至是人工选择和
优化提示。Prompt tuning的目标是找到一种方式,使得当给定这个提示时,模型能够生成最准确、
最相关的输出。
总的来说,prompt learning和prompt tuning都与如何使用和优化模型的输入提示有关。它们的主要区
别在于,prompt learning更关注于如何训练模型以响应特定的提示,而prompt tuning则更关注于如何
找到或生成最优的提示以提高模型的性能
思维链
Chain-of-Thought Prompting
**CoT Prompting **作为一种促进语言模型推理的方法具有几个吸引人的特点:
• 首先,从原则上讲,CoT 允许模型将多步问题分解为中间步骤,这意味着可以将额外计算资源分配
给需要更多推理步骤的问题。
• 其次,CoT 提供了对模型行为的可解释窗口,提示了它可能是如何得出特定答案的,并提供了调试
推理路径错误之处的机会(尽管完全描述支持答案的模型计算仍然是一个未解决问题)。
• 第三,在数学应用题、常识推理和符号操作等任务中都可以使用思维链推理(CoT Reasoning),
并且在原则上适用于任何人类能够通过语言解决的任务。
• 最后,在足够大规模现成语言模型中很容易引发 CoT Reasoning ,只需在少样本提示示例中包含一
些连贯思路序列即可
错误

正确

思维链
- 对于小模型来说,CoT Prompting无法带来性能提升,甚至可能带来性能的下降。
- 对于大模型来说,CoT Prompting涌现出了性能提升。
- CoT Prompting能获得更多的性能收益。3.对于复杂的问题
CoT Prompt :Think step-by-step
自洽性(Self-Consistency):多路径推理
通过思维链,我们可以看到大语言模型的强与弱:
- 它强在,模型规模的提高,让语义理解、符号映射、连贯文本生成等能力跃升,从而让多步骤推理的思维链成为可能,带来“智能涌现”
- 它弱在,即使大语言模型表现出了前所未有的能力,但思维链暴露了它,依然是鹦鹉学舌,而非真的产生了意识。
没有思维链,大模型几乎无法实现逻辑推理。
但有了思维链,大语言模型也可能出现错误推理,尤其是非常简单的计算错误。Jason Wei 等的
论文中,曾展示过在 GSM8K 的一个子集中,大语言模型出现了 8% 的计算错误,比如6 * 13 =
68(正确答案是78)
思维树(Tree-of-Thoughts, ToT)
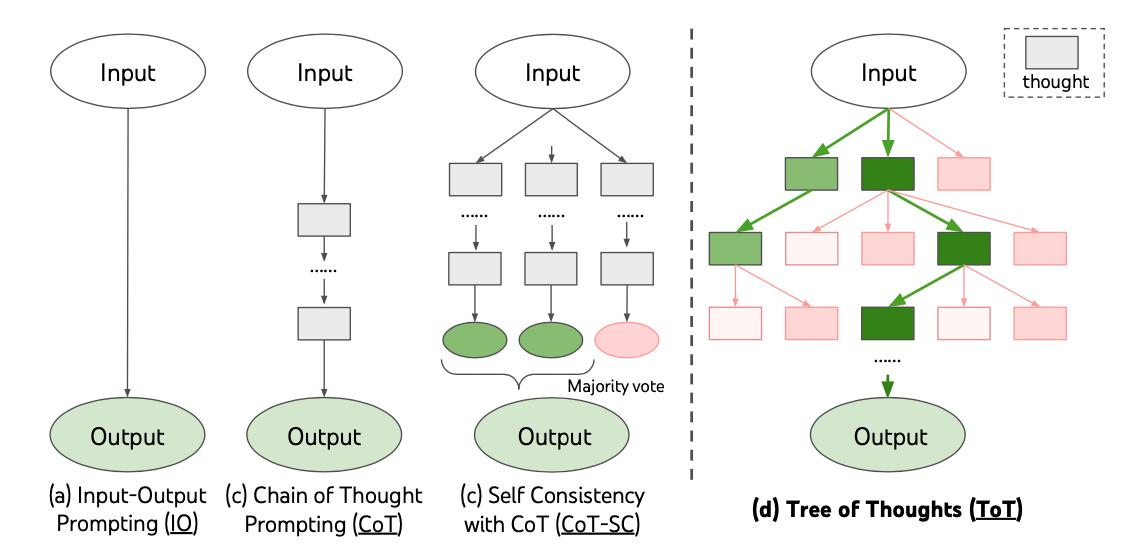
ToT 工作原理解读: Step 1 思维分解
虽然CoT样本以连贯的方式呈现思维,没有明确的分解过程,但ToT利用问题属性来设计
和分解中间思维步骤。如下表所示,根据不同的问题,一个思维可以是几个词(填字游
戏),一行方程式(24点游戏),或者是整段写作计划(创意写作)。
总体而言,一个思维应该足够“小”,以便语言模型能够生成有前景且多样化的样本(例如
生成整本书通常太“大”而无法连贯),同时又足够“大”,以便语言模型能够评估其对于问
题求解的前景(例如仅生成一个标记通常太“小”无法评估)。

ToT 工作原理解读: Step 2 思维生成
定义思维生成器 G(pθ, s, k):给定一个树状态 s = [x, z1···i],我们考虑两种策略来为下一个思维步骤生成 k 个候选项:
- 从 CoT 提示(创意写作)中独立同分布地抽样思维:z(j) ∼ pCoT (zi+1|s) = pCoT(zi+1|x, z1···i) (j = 1 · · · k)。当思维空间丰富时(例如每个思维是一段落),独立同分布的样本能够带来多样性;
- 使用“提议提示”逐个提出思维(24点游戏和迷你填字游戏):[z(1),· · ·, z(k)] ∼ppropose(z(1···k)|s)。当思维 θ i+1 空间更受限制时(例如每个思维只是一个词或一行),在相同语境中提出不同的想法可以避免重复。
ToT 工作原理解读: Step 3 状态评估
定义状态评估器V(pθ,S):给定一组不同状态的前沿,状态评估器评估它们解决问题的进展情况,作为搜索算
法确定哪些状态继续探索以及以何种顺序进行的启发式方法。虽然启发式方法是解决搜索问题的标准方法之
一,但通常要么是编程实现(例如DeepBlue),要么是学习模型(例如AlphaGo )。
作者提出了第三种选择,即使用语言模型有意识地推理状态。在适用时,这样一个有意识的启发式方法可以
比编程规则更灵活,并且比学习模型更节约样本。与思维生成器类似,我们考虑两种策略来独立或同时评估
状态:
- 独立地对每个状态进行价值评估:V(pθ,S)(s) ∼ pvalue(v|s),其中值 θ 通过对状态 s 进行推理生成一个标量值 v(例如1-10)或分类结果(例如sure/likely/impossible),该分类结果可以被启发性地转化为一个值。这种评价推理的基础可能因问题和思考步骤而异。在这项工作中,我们通过少数向前看模拟(例如快速确认5、5、14可以通过5 + 5 + 14达到24, 或者“hot l”可以表示“inn”通过在“ ”中填充“e”)以及常识(例如1 2 3太小无法达到24,或者没有单词能以“tzxc”开头)来探索评估。虽然前者可能促进“好”的状态,但后者可以帮助消除“坏”的状态。这样的评估不需要完美,只需要近似即可。
- 跨多个状态进行投票:V(pθ,S)(s)=1[s=s∗],其中一个被投票淘汰的"好"状态∗ ∼pvote(s∗|S),是基于对 S中不同状态进行有意比较的投票提示。当问题成功更难直接价值化时(例如段落连贯性),自然而然地会转而比较不同的部分解决方案,并为最有希望的解决方案投票。这与一种"逐步"自洽策略类似,即将 "要探索哪个状态" 视为多项选择问答,并使用语言模型样本对其进行投票。
对于这两种策略,我们可以多次提示语言模型来聚合值或投票结果,以换取更忠实/稳健的启发式方法所需的
时间/资源/成本
ToT 工作原理解读: Step 4 搜索算法
最后,在ToT框架内,可以根据树结构插入和使用不同的搜索算法。作者探索了两种相对简单的搜索算法,
并将更高级的算法(例如A* 今儿MCTS)留给未来的工作:
(a) 广度优先搜索(ToT-BFS)每步维护一组最有希望的状态集合b个。这适用于24点游戏和创意写作等树深
度受限制(T ≤ 3),并且初始思考步骤可以评估和修剪为一个小集合(b ≤ 5)。
(b) 深度优先搜索(ToT-DFS)首先探索最有希望的状态,直到达到最终输出结果(t > T),或者状态评估器认
为无法解决当前问题。在后一种情况下,从s开始的子树被修剪以进行开发与利用之间的权衡。在这两种情况
下,DFS会回溯到s的父状态以继续探索。
从概念上讲,ToT作为LM通用问题求解方法具有几个优势:
- 泛化性。IO、CoT、CoT-SC和自我完善都可以看作是ToT的特殊情况(即有限深度和广度的树;图1)
- 模块化。基本LM以及思考分解、生成、评估和搜索过程都可以独立变化。
- 适应性。可以适应不同的问题属性、LM能力和资源约束。
- 方便性。无需额外训练,只需要一个预训练好的LM就足够


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!