Day06 - 匿名函数和文件操作
1. 匿名函数 lambda
def 函数名(参数列表):
函数体
'''
匿名函数
'''
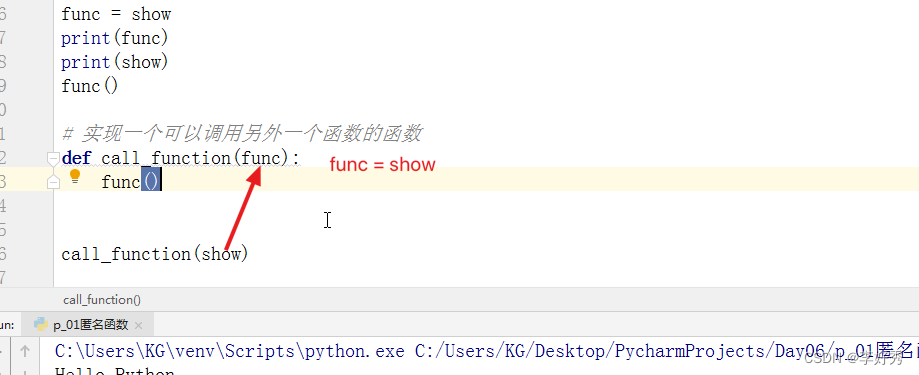
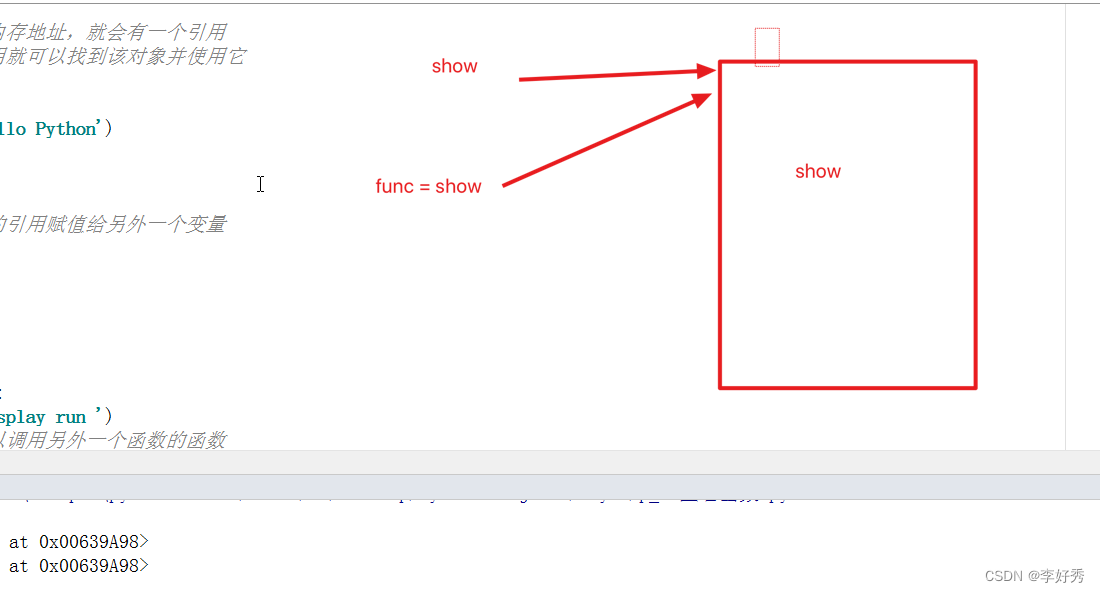
# 万物皆对象
# 对象就会有内存地址,就会有一个引用
# 通过这个引用就可以找到该对象并使用它
def show():
print('Hello Python')
show()
# 将一个函数的引用赋值给另外一个变量
func = show
print(func)
print(show)
func()
def display():
print('Display run ')
# 实现一个可以调用另外一个函数的函数
def call_function(func):
func()
call_function(show)
call_function(display)

格式:
lambda [形参1], [形参2], ... : [单行表达式] 或 [函数调用]
lambda定义和普通函数的区别:
1. lambda 没有函数名
2. lambda 参数列表外没有括号
3. lambda 函数体中,只能实现简单的表达式计算或函数调用
4. lambda 函数体中,不能使用Return,if,while,for-in 这些都不行
5. lambda 函数体中,可以使用if 实现的三目运算符.
使用场景:
变量 = lambda ....
一般情况下,因为lambda的局限性,使得他不能实现复杂功能,只能实现一些简单功能
那么在使用时,一般会实现一个简单的,一次性使用的场景
'''
匿名函数
'''
# 定义一个匿名函数
func = lambda: 1 + 1
print(func)
print(func())
func = lambda x: print(x ** 10)
func(2)
# lambda 定义时的注意事项
# 1. lambda 默认返回表达计算结果,不需要return ,如果加了reutrn 反而报错
# func = lambda x, y: return x + y
# 2. 不能使用 循环
# func = lambda x,y: for i in range(x, y): print(i)
# func = lambda x,y: i = x while i < y: print(i) i +=1
# 3. 不能使用if的正常格式
# func = lambda n: if n % 2 == 0: print('偶数')
# 4. 但是可以使用 if实现的三目运算符
func = lambda m, n: m if m > n else n
print(func(11, 2))
2. 高阶函数
map() 关系映射
functools.reduce()
filter()
'''
map 函数
作用:是对参数列表中的元素做一个映射
'''
my_list = [1, 2, 3, 4, 5]
# 这个函数是为了给map的参数一进行传参
# 因为map函数需要使用这个函数来计算每一个元素的映射值 ,
# 所以该函数有且必须只能有一个参数
def f(x):
return x ** 3
# result_list = map(f, my_list)
# 利用lambda 来替代函数进行传参
result_list = map(lambda n: n ** 4, my_list)
for i in result_list:
print(i)
print(type(result_list))
# map实现原理
def my_map(func, c_list):
# 定义一个新空列表 ,保存映射结果
new_list = []
# 遍历源列表 中的数据
for i in c_list:
# 调用函数计算映射值 ,并保到新列表中
# new_list.append(func(i))
n = func(i)
new_list.append(n)
return new_list
print('*' * 10)
result_list = my_map(lambda n: n ** 4, my_list)
for i in result_list:
print(i)
'''
高阶函数-reduce
'''
# 注意:reduce 不能直接使用,需要导入一个模块 functools
# reduce 作用是根据传入的参数一对参数二中的数据进行累计
import functools
# my_list = ['h','e','l','l','o']
my_list = list('hello')
result = functools.reduce(lambda s1, s2: s1 + s2, my_list)
# result = functools.reduce(lambda s1,s2: s1.upper() + s2.upper(), my_list)
print(result)
# 练习 :使用 reduce 求阶乘
my_list = [i for i in range(1, 6)]
result = functools.reduce(lambda n1, n2: n1 * n2, my_list)
print(result)
'''
filter 过滤函数
'''
my_list = ['123', '234', 'abc', '@#$', ' ', 'abc234', '132abc']
# 过滤出所有的数字字符串
num_list = filter(lambda s: s.isdigit(), my_list)
print(num_list)
for s in list(num_list):
print(s)
'''
函数sort
'''
my_list = [7, 2, 4, 1, 5, 8, 9, 3, 6, 0]
my_list.sort()
print(my_list)
my_list = [{'id': 1, 'name': 'tom', 'age': 12}, {'id': 3, 'name': 'rose', 'age': 32},
{'id': 2, 'name': 'Jack', 'age': 22}]
# 默认sort方法是不能对字典进行比较排序的 ,TypeError: '<' not supported between instances of 'dict' and 'dict'
# 按id的升序排序
# my_list.sort(key=lambda d: d['id'])
# 按年龄降序排序
my_list.sort(key=lambda x: x['age'], reverse=True)
print(my_list)
'''
1 ,3 ,2 ,5
1, 3 ,2 ,5
1 2, 3, 5
'''
3. 文件操作概述及操作过程
文件作用:进行持久化存储数据
操作过程:
双击打开
点叉关闭
程序操作文件的过程:
打开-> 设置打开的模式,(读写) open(打开文件路径,打开模式)
操作文件(读取)
关闭-> close()
4. 文件的访问模式
读取:
文本形式
程序文件
.txt 文件
.rtf 文件
二进制形式
音频文件
视频文件
图片文件
写入:
文本形式
程序文件
.txt 文件
.rtf 文件
二进制形式
音频文件
视频文件
图片文件
以文本方式打开方式的模式
r -> rt -> read text 以文本方式打开文件读,文件存在,打开成功,文件不存在,打开失败
w -> wt -> write text 以文本方式打开文件写,不管文件是否存在,都会新创建一个新文件
a -> at -> append text 以文件方式打开文件追加,文件不存在,创建文件,文件存在,那么打开文件然后将光标移动到文件的最后
以二进制形式打开文件的模式
rb 以二进制形式打开文件读取
wb 以二进制形式打开文件写入
ab 以二进制形式打开文件追加
(了解)
r+ 这三种模式都具有读取写入功能
w+
a+
'''
文件操作
'''
# 打开文件,以写模式
# file = open('a.txt','w')
# file = open('a.txt','r')
file = open('a.txt', 'rt')
print(file)
# 关闭文件
file.close()
5. 文件的读取
read()
'''
文件读取
'''
# 打开文件,以读取模式
file = open('a.txt', 'rt')
# 读取文件内容
# 默认读取全部文件内容
# 但是这种方式 只适用于文件比较小的情况
# 如果文件比较大,不建议这样读取
# content = file.read()
# # 在读取数据时,指定读取一部分
# content = file.read(6)
#
# # 显示读取的文件内容
# print(content)
# 读取多行文件的方式
while True:
# 读取
content = file.read(4096)
# 如果在文件读取时,读取的结果为 空串,说明文件读取完毕
# 根据这个条件 可以设置读取文件的结束条件
if content == '':
break
print(content, end='')
# 关闭文件
file.close()
6. 文件读取的几种方式
read() # 一次性将整个文件内容读取出来,不适合大文件读取
read(size) # 掌握 读取指定的字节数的文件内容 ,如果文件最后没有内容了,那么read的返回值是空字符串 , "" 一般指定4096
readline() # 读取一行
readlines() # 一次性将整个文件内的内容以行的形式读取出来,放到一个列表中
'''
文件其它 读取方式
'''
# 以行的形式读取文件
# 打开文件
file = open('a.txt', 'r')
# 以行读取 readline()
# while True:
# content = file.readline()
# if content == "":
# break
# print(content)
# 以行的方式 读取整 个文件 readlines
content_list = file.readlines()
print(content_list)
for line in content_list:
print(line)
print(line.upper())
# 关闭文件
file.close()
7. 文件的写入
write(content) 该函数用来向文件中写入数据
前提: 使用该函数时,打开文件时,必须要给定写入权限,要具有写入模式
8. 常用文件和文件夹操作
os 模块
rename()
remove()
mkdir()
getcwd()
chdir()
listdir() 掌握
rmdir()
'''
os 模块
rename()
remove()
mkdir()
getcwd()
chdir()
listdir() 掌握
rmdir()
'''
# 导入 os 模块
# os -> operator system -> 操作系统
import os
# rename 重命名
# os.rename('a.txt','b.txt')
# mkdir 创建目录 make directory
# 如果当前目录 存在,会报错
# os.mkdir('test_dir')
# getcwd 获取当前工作目录 get current work directory
cwd = os.getcwd()
print(cwd)
# listdir () 获取当目录下的文件列表
file_list = os.listdir('.')
print(file_list)
for file in file_list:
print(file)
print('*' * 10)
# chdir() 改变当前目录 到指定 的路径 上去。 change directory
os.chdir('C:\\Users\\KG\\Desktop')
print(os.getcwd())
print(os.listdir('.'))
# remove() 删除一个文件
# os.remove('aaa.txt')
# rmdir() 删除一个文件夹 remove directory
# os.rmdir('PycharmProjects/Day06/test_dir')
# 当目录 不为空,不能删除
os.rmdir('a')
9. 批量修改文件名后复制文件
'''
实现了一个复制命令
'''
def file_copy(src, dst):
# 以读取的方式 打开源文件
file_r = open(src, 'r')
# 以写的方式打开目标文件
file_w = open(dst, 'w')
# 循环
while True:
# 读取文件内容
content = file_r.read(1024)
# 将读取的文件内容 写入到另一个文件中
if content == '':
print('文件拷贝成功')
break
# 写入文件
file_w.write(content)
# 关闭文件
file_r.close()
file_w.close()
file_copy('b.txt', 'b_bak.txt')
重点注意:
翻车点:
当以二进制模式打开文件进行文件操作时.
read 函数最终读取文件内容为空时,返回的结果为 b''
表示是一个二进制的空字符串
在 Python2.7版本中. '' == b'' 结果为True
在 Python3.6版本中. '' == b'' 结果为False
'''
批量读取文件,改名之后去复制
'''
# C:/Users/KG/Desktop/
# 因为要使用文件操作功能 ,所以要导入 os 模块
import os
def muilt_file_copy(src, dst):
# 获取当前工作目录
print(os.getcwd())
# 切换目录 到 源文件目录中
os.chdir(src)
# 从源当中去读取所有的文件信息
file_list = os.listdir(src)
# print(file_list)
# 创建出一个新的目标文件夹
os.mkdir(dst)
# 循环 读取文件次数
# 遍历每一个文件
for file in file_list:
# 对文件改名,遍历的文件就是需要复制的源文件,改名后的文件就是要复制出来的文件
# 先对源文件名进行分割
s_file = file.rpartition('.')
# C:/Users/KG/Desktop/v_bak/v3_bak.mp4
dst_file = dst + '/' + s_file[0] + '_bak' + s_file[1] + s_file[2]
print(dst_file)
# print(dst_file)
# 分别以读写方式打开源和目标文件
file_r = open(file, 'rb')
file_w = open(dst_file, 'wb')
# 读取内容,写入内容
while True:
content = file_r.read(1024)
# 因为打开文件时,使用的是二进制模式打开,所以在判断结束时,
# 需要判断是否是一个二进制空字符串,b''
if content == b'':
print(f'{file} 复制成功。。')
file_r.close()
file_w.close()
break
# 如果读取内容不是空,将读取内容 写入到目标文件
file_w.write(content)
else:
print(f'一共复制了{len(file_list)}个文件')
# 源文件夹
src = 'C:/Users/KG/Desktop/v'
# 目标文件夹
dst = 'C:/Users/KG/Desktop/v_bak'
# muilt_file_copy(src,dst)
a = [1, 2, 3]
b = map(lambda x: x * 10, a)
print(next(b))
print(next(b))
print(next(b))
print(next(b))
# for i in b:
# print(i)
#
# for i in b:
# print(i)
#
#
# a = (i for i in range(3))
# print(a)
#
# print(X(a))
# print(next(a))
# print(next(a))
# print(next(a))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号