七、BatchNormalization使用技巧
@
前文
- 一、Windows系统下安装Tensorflow2.x(2.6)
- 二、深度学习-读取数据
- 三、Tensorflow图像处理预算
- 四、线性回归模型的tensorflow实现
- 五、深度学习-逻辑回归模型
- 六、AlexNet实现中文字体识别——隶书和行楷
- 七、VGG16实现鸟类数据库分类
- 七、VGG16+BN(Batch Normalization)实现鸟类数据库分类
BatchNormalization的核心思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
数据生成器+数据部分展示
#数据生成训练集与测试集
#猫狗数据
from keras.preprocessing.image import ImageDataGenerator
IMSIZE = 224
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'../../data/dogs-vs-cats/smallData/train',
target_size=(IMSIZE, IMSIZE),
batch_size=10,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'../../data/dogs-vs-cats/smallData/validation',
target_size=(IMSIZE, IMSIZE),
batch_size=10,
class_mode='categorical'
)

数据来源kaggle的猫狗数据
#展示X(图像)与Y(因变量)
import numpy as np
X, Y = next(validation_generator)
print(X.shape)
print(Y.shape)
Y[:, 0]

#展示图像
from matplotlib import pyplot as plt
plt.figure()
fig, ax = plt.subplots(2, 5)
fig.set_figheight(6)
fig.set_figwidth(15)
ax = ax.flatten()
X, Y = next(validation_generator)
for i in range(10): ax[i].imshow(X[i, :, :, ])

带有BN的逻辑回归
#带有BN的逻辑回归模型
from keras.layers import Flatten, Input, BatchNormalization, Dense
from keras import Model
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
x = BatchNormalization()(x)
x = Flatten()(x)
x = Dense(2, activation='softmax')(x)
output_layer = x
model1 = Model(input_layer, output_layer)
model1.summary()
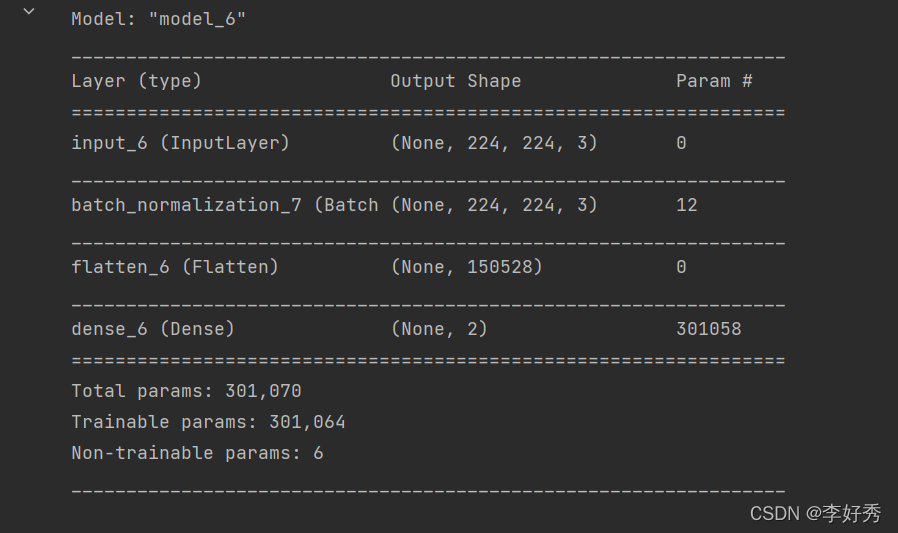
#带有BN的逻辑回归模型与拟合
from keras.optimizers import Adam
model1.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.01),
metrics=['accuracy'])
model1.fit_generator(train_generator,
epochs=200,
validation_data=validation_generator)
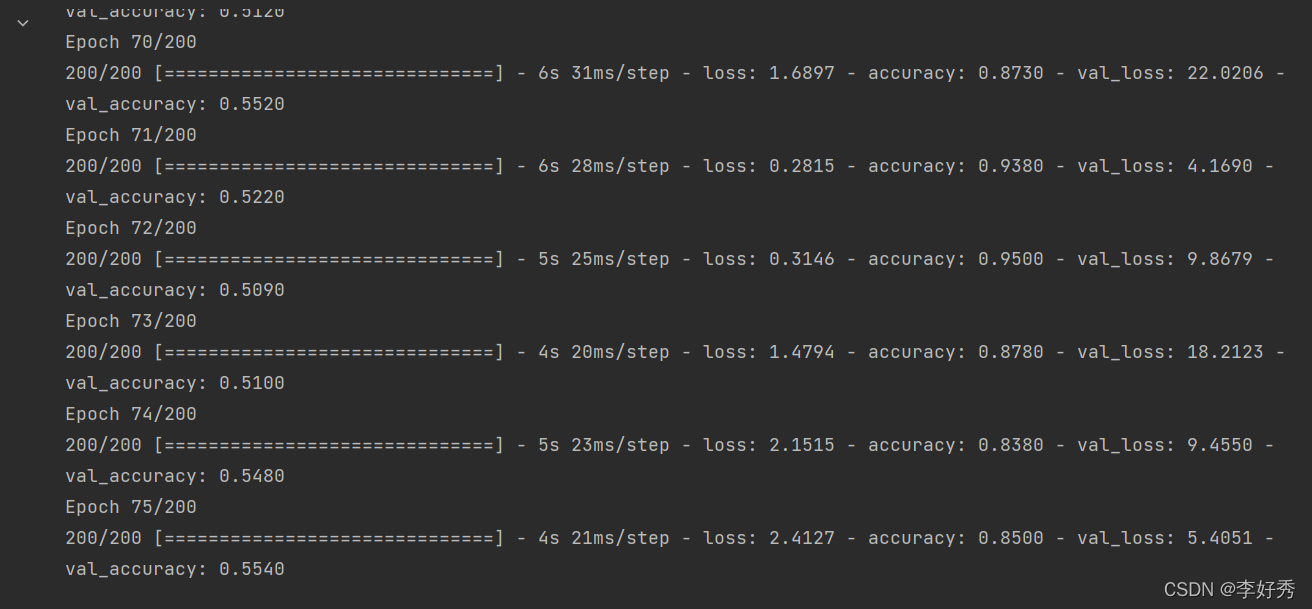
Batch Normalization 在特定的模型、特定的数据集是有帮助的
带有BN的宽模型
#扩展,带有BN的宽模型
from keras.layers import Conv2D, MaxPooling2D
n_channel = 100
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
x = BatchNormalization()(x)
x = Conv2D(n_channel, [2, 2], activation='relu')(x)
x = MaxPooling2D([16, 16])(x)
x = Flatten()(x)
x = Dense(2, activation='softmax')(x)
output_layer = x
model2 = Model(input_layer, output_layer)
model2.summary()
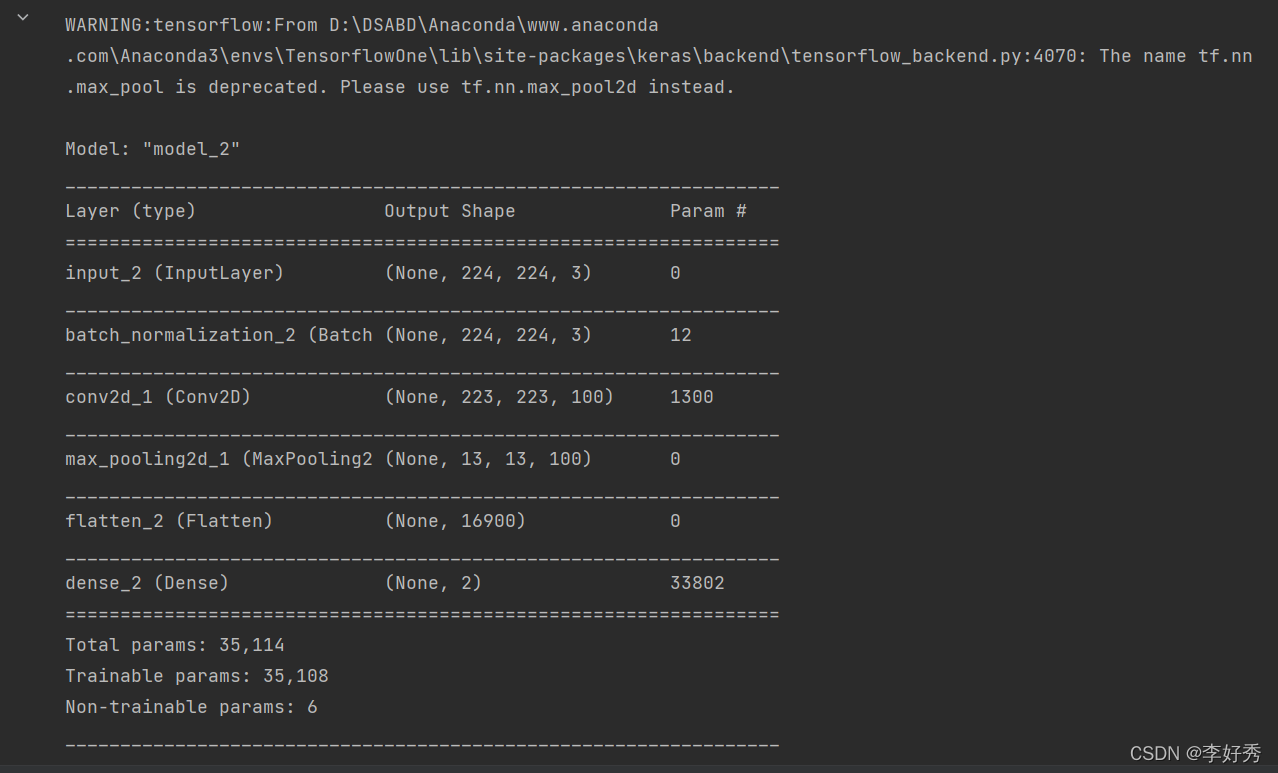
# 带有BN的宽模型的编译与拟合
model2.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.001),
metrics=['accuracy'])
model2.fit_generator(train_generator,
epochs=200,
validation_data=validation_generator)
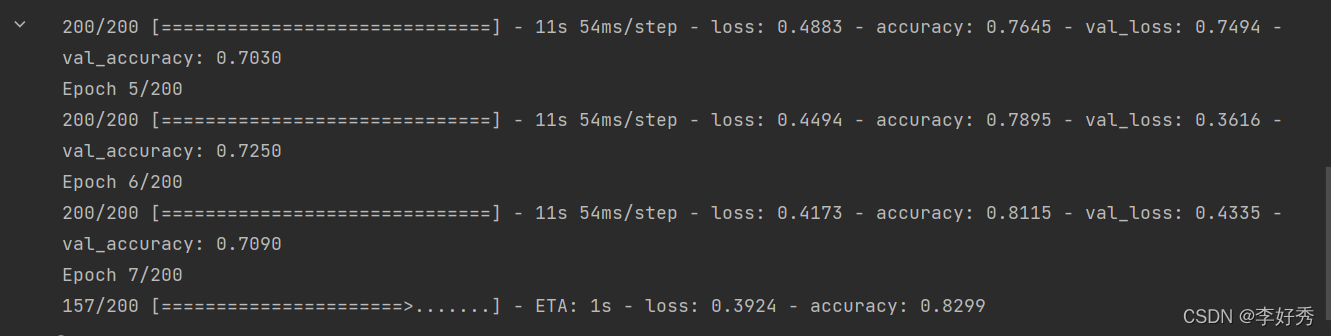
会比逻辑回归带BN的结果好得多
带有BN的深度模型
#带有BN的深度模型
n_channel = 20
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
x = BatchNormalization()(x)
for _ in range(7):
x = Conv2D(n_channel, [2, 2], padding='same', activation='relu')(x)
x = MaxPooling2D([2, 2])(x)
x = Flatten()(x)
x = Dense(2, activation='softmax')(x)
output_layer = x
model3 = Model(input_layer, output_layer)
model3.summary()
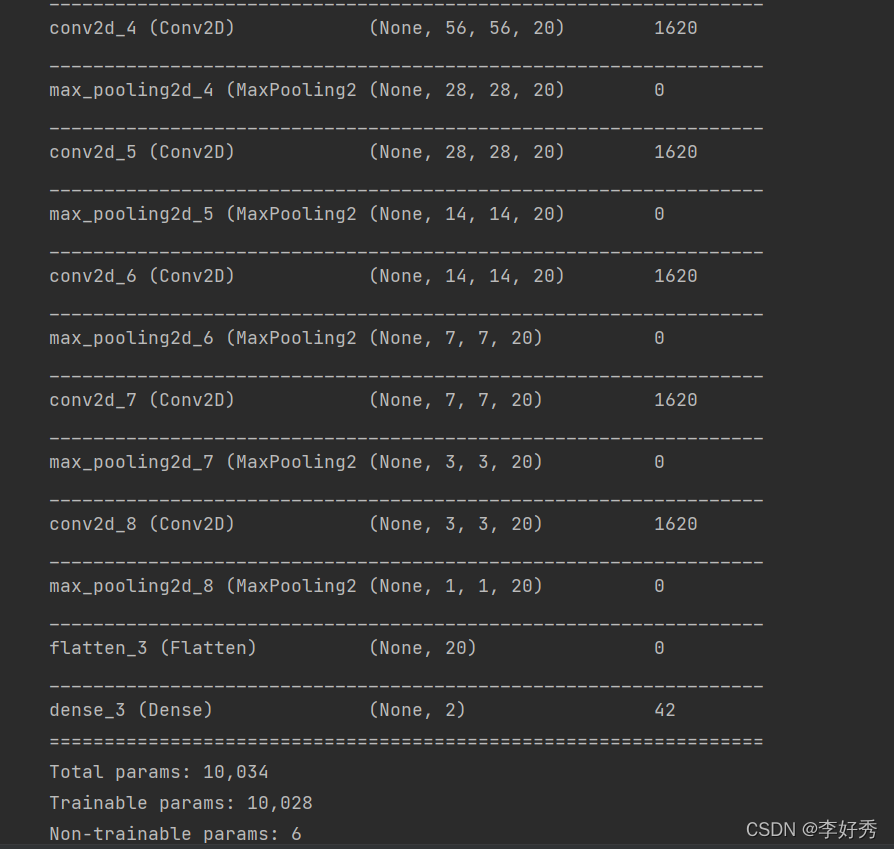
#带有BN的深度模型编译与拟合
from keras.optimizers import Adam
model3.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.01),
metrics=['accuracy'])
model3.fit_generator(train_generator,
epochs=200,
validation_data=validation_generator)
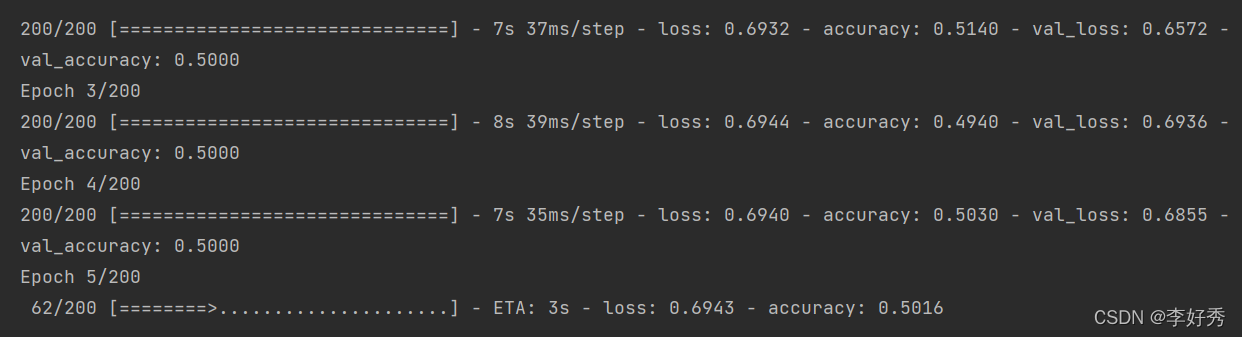
深度模型会更好一点
BatchNormalization在很多情况下确实有帮助巨大的,但并不是所有情况都有帮助。
GitHub下载地址:
本文来自博客园,作者:李好秀,转载请注明原文链接:https://www.cnblogs.com/lehoso/p/15643945.html

