七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
前文
- 一、CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式
- 二、JAVA API实现HDFS
- 三、MapReduce编程实例
- 四、Zookeeper3.7安装
- 五、Zookeeper的Shell操作
- 六、Java API操作zookeeper节点
Hadoop3.3.1 HA 高可用集群的搭建
(基于Zookeeper,NameNode高可用+Yarn高可用)
QJM 的 NameNode HA
用Quorum Journal Manager或常规共享存储
QJM的NameNode HA
Hadoop HA模式搭建(高可用)
1、集群规划
一共三台虚拟机,分别为master、worker1、worker2;
namenode三台上都有,resourcemanager在worker1,woker2上。
| master | woker1 | worker2 | |
|---|---|---|---|
| NameNode | yes | yes | yes |
| DataNode | no | yes | yes |
| JournalNode | yes | yes | yes |
| NodeManager | no | yes | yes |
| ResourceManager | no | yes | yes |
| Zookeeper | yes | yes | yes |
| ZKFC | yes | yes | yes |
因为没有重新创建虚拟机,是在原本的基础上修改。所以名称还是hadoop1,hadoop2,hadoop3
hadoop1 = master
hadoop2 = worker1
hadoop3 = worker2
2、Zookeeper集群搭建:
3、修改Hadoop集群配置文件
修改 vim core-site.xml
vim core-site.xml
core-site.xml:
<configuration>
<!-- HDFS主入口,mycluster仅是作为集群的逻辑名称,可随意更改但务必与
hdfs-site.xml中dfs.nameservices值保持一致-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 默认的hadoop.tmp.dir指向的是/tmp目录,将导致namenode与datanode>数据全都保存在易失目录中,此处进行修改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/data/hadoop/tmp</value>
</property>
<!--用户角色配置,不配置此项会导致web页面报错-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--zookeeper集群地址,这里可配置单台,如是集群以逗号进行分隔-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!-- hadoop链接zookeeper的超时时长设置 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
上面指定 zookeeper 地址中的Hadoop1,hadoop2,hadoop3换成你自己机器的主机名(要先配置好主机名与 IP 的映射)或者 ip
修改 hadoop-env.sh
vim hadoop-env.sh
hadoop-env.sh
在使用集群管理脚本的时候,由于使用ssh进行远程登录时不会读取/etc/profile文件中的环境变量配置,所以使用ssh的时候java命令不会生效,因此需要在配置文件中显式配置jdk的绝对路径(如果各个节点的jdk路径不一样的话那hadoop-env.sh中应改成本机的JAVA_HOME)。
hadoop 3.x中对角色权限进行了严格限制,相比于hadoop 2.x要额外对角色的所属用户进行规定。
此处仅为搭建HDFS集群,如果涉及到YARN等内容的话应一并修改对应yarn-env.sh等文件中的配置
在脚本末尾添加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_241
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_ZKFC_USER="root"
export HDFS_JOURNALNODE_USER="root"
修改 hdfs-site.xml
vim hdfs-site.xml
hdfs-site.xml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/export/servers/data/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/servers/data/hadoop/tmp/dfs/data</value>
</property>
<!-- 启用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致
dfs.ha.namenodes.[nameservice id]为在nameservice中的每一个NameNode设置唯一标示符。
配置一个逗号分隔的NameNode ID列表。这将是被DataNode识别为所有的NameNode。
例如,如果使用"cluster1"作为nameservice ID,并且使用"nn1"和"nn2"作为NameNodes标示符
-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- cluster下面有3个NameNode,分别是nn1,nn2,nn3-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:9870</value>
</property>
<!-- nn3的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop3:9000</value>
</property>
<!-- nn3的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop3:9870</value>
</property>
<!-- 指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表
该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推荐使用nameservice,默认端口号是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁H的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/servers/data/hadoop/tmp/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!--指定辅助名称节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:9868</value>
</property>
</configuration>
要创建journaldata文件夹
workers
在hadoop 2.x中这个文件叫slaves,配置所有datanode的主机地址,只需要把所有的datanode主机名填进去就好了
hadoop1
hadoop2
hadoop3
Yarn高可用
vim mapred-site.xml
修改 mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
vim yarn-site.xml
修改 yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop3</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop2:2181</value>
</property>
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--日志聚集功能开启-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间设置1天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
都修改好了,就分发给其他集群节点
(在hadoop/etc路径下)
scp /export/servers/hadoop-3.3.1/etc/hadoop/* hadoop2:/export/servers/hadoop-3.3.1/etc/hadoop/
scp /export/servers/hadoop-3.3.1/etc/hadoop/* hadoop3:/export/servers/hadoop-3.3.1/etc/hadoop/
启动zookeeper集群
在每台机器上启动:
zkServer.sh start
zkServer.sh status
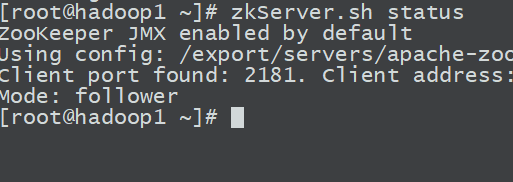
格式化namenode、zkfc
首先,在所有虚拟机上启动journalnode:
hdfs --daemon start journalnode
都启动完毕之后,在master(hadoop1)节点上,格式化namenode
hadoop namenode -format
因为之前搭建过完全分布式,所以格式化一次namenode
但是,集群中的datanode,namenode与/current/VERSION/中的
CuluserID有关所以再次格式化,并启动,其他两个节点同步格式化好的namenode并不冲突
formatZK同理
然后单独启动namenode:
hdfs namenode
然后,在另外两台机器上,同步格式化好的namenode:
hdfs namenode -bootstrapStandby
应该能从master上看到传输信息。
传输完成后,在master节点上,格式化zkfc:
hdfs zkfc -formatZK
启动hdfs
在master节点上,先启动dfs:
start-dfs.sh
然后启动yarn:
start-yarn.sh
启动mapreduce任务历史服务器:
mapred --daemon start historyserver
可以看到各个节点的进程启动情况:
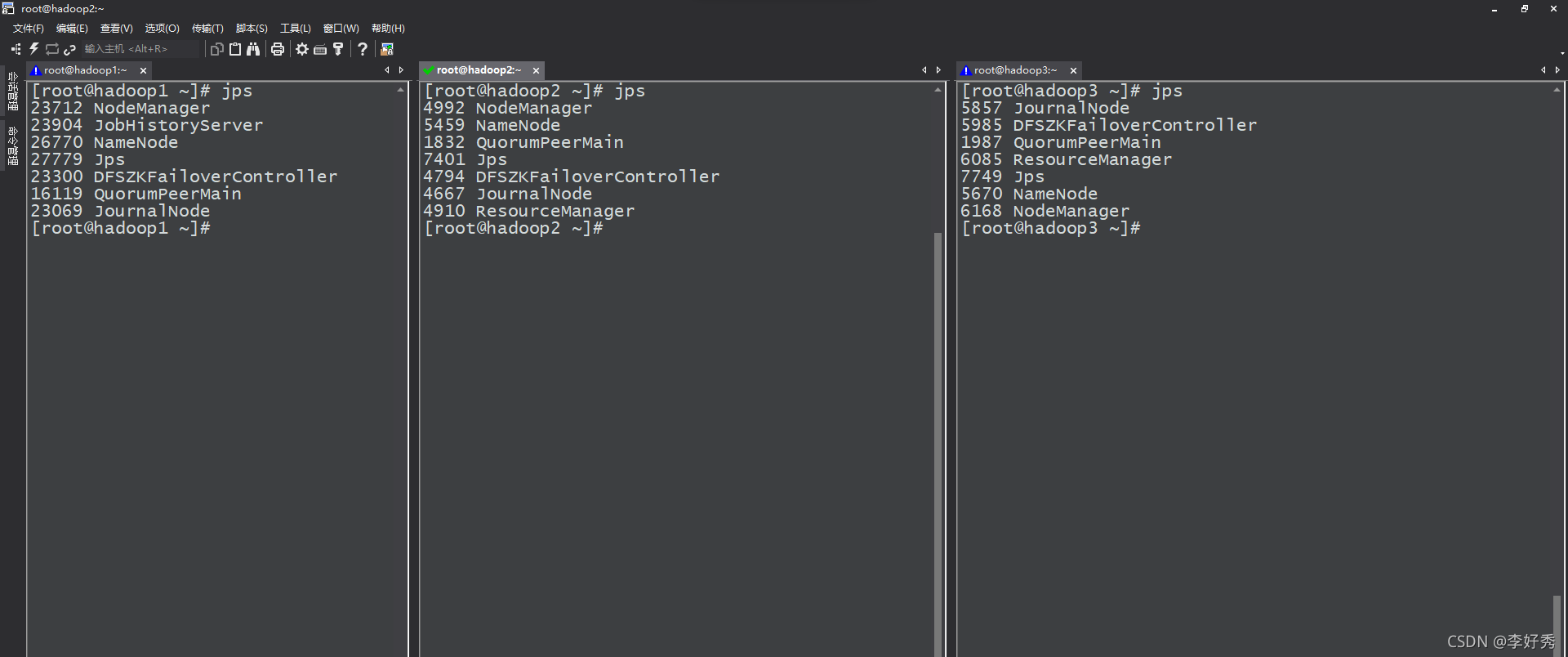
如果datanode未启动
是版本号不一致产生的问题,那么我们就单独解决版本号的问题,将你格式化之后的NameNode的VERSION文件找到,然后将里面的clusterID进行复制,再找到DataNode的VERSION文件,将里面的clusterID进行替换,保存之后重启
尝试HA模式
首先看看各个namenode主机状态:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getServiceState nn3
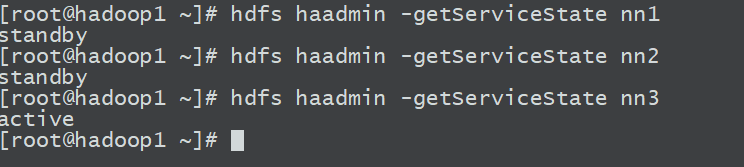
可以看到,有两个standby,一个active。
在active的master节点上,kill掉namenode进程:
此时再次查看节点
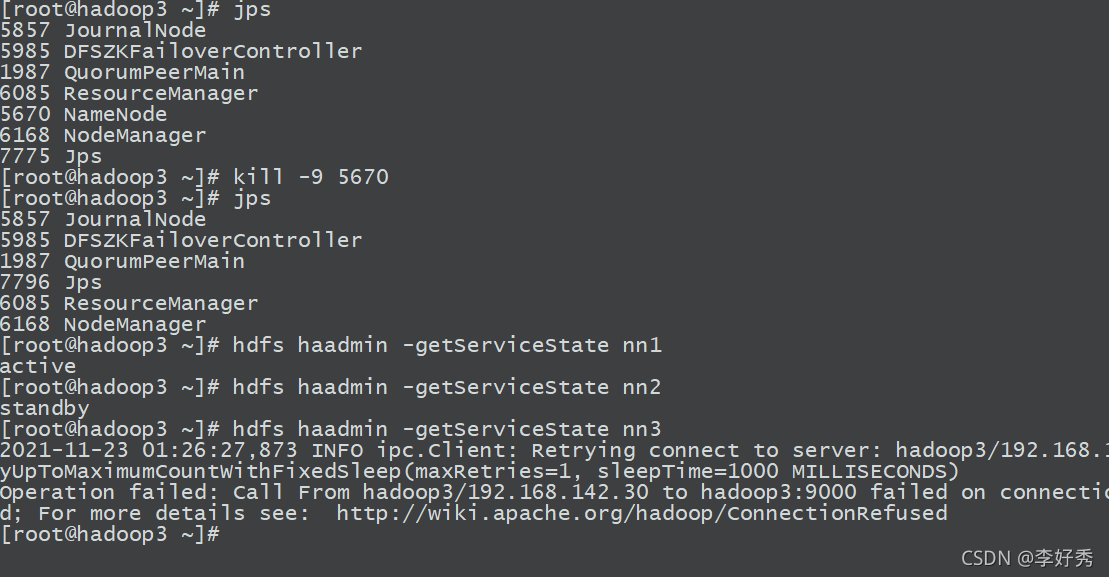
可以看到,nn1已经切换为active,Hadoop 高可用集群基本搭建完成。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!