摘要:
CompletableFuture及反应式编程背后的概念 :::info ❏线程、Future以及推动Java支持更丰富的并发API的进化动力 ❏ 异步API ❏ 从“线框与管道”的角度看并发计算 ❏ 使用CompletableFuture结合器动态地连接线框❏ 构成Java 9反应式编程Flow 阅读全文
posted @ 2025-01-15 12:37
李好秀
阅读(199)
评论(0)
推荐(0)
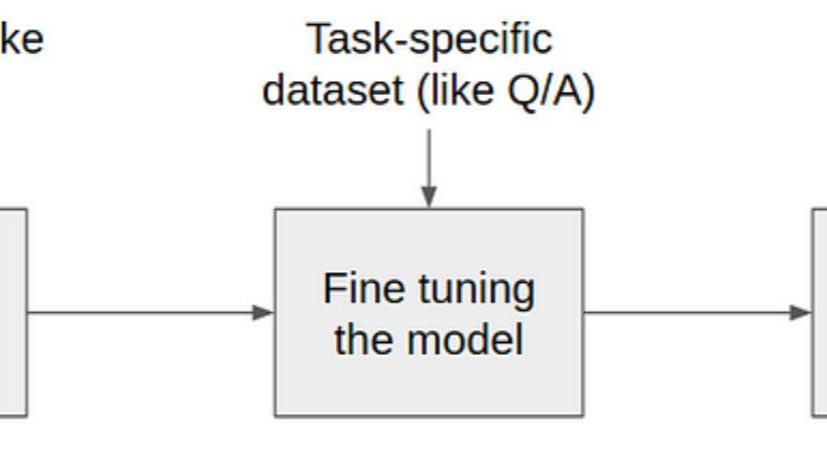 知识点 注意力机制(Attention)的主要用途是什么? 选择重要的信息并忽略不相关的信息 Transformer 模型是基于什么理论构建的? C. 注意力机制(Attention) GPT 和 BERT 的主要区别是什么? C. GPT 使用了单向自注意力,而 BERT 使用了双向自注意力 在注 阅读全文
知识点 注意力机制(Attention)的主要用途是什么? 选择重要的信息并忽略不相关的信息 Transformer 模型是基于什么理论构建的? C. 注意力机制(Attention) GPT 和 BERT 的主要区别是什么? C. GPT 使用了单向自注意力,而 BERT 使用了双向自注意力 在注 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号