
Matplotlib模块扩展
主体:matplotlib扩展
-
水平条形图
-
交叉条形图
-
直方图
-
箱线图
-
折线图
-
散点图
-
气泡图
-
热力图
-
可视化相关模块
-
绘制组合图
-
其它种类的统计图表

详情
-
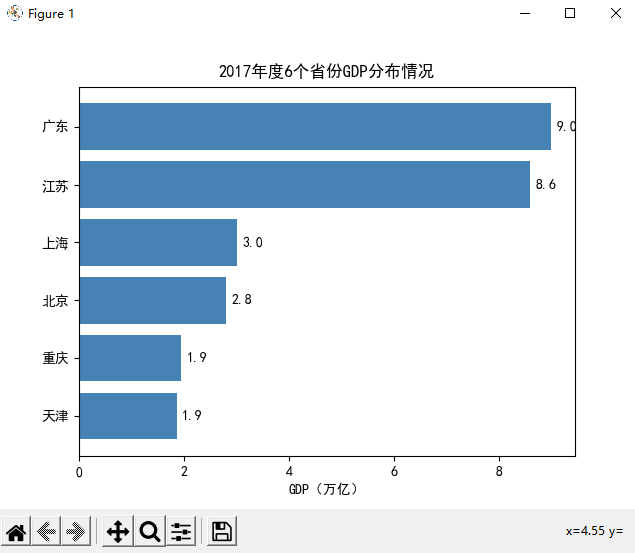
水平条形图
水平条形图一般用于展示排序后的数据。
import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读入数据 GDP = pd.read_excel(r'Province GDP 2017.xlsx') # 对读入的数据做升序排序 GDP.sort_values(by = 'GDP', inplace = True) # 绘制水平条形图 bar之后的h表示horizon plt.barh( y = range(GDP.shape[0]), # y轴刻度 width = GDP.GDP, # x轴数值 tick_label = GDP.Province, # y轴刻度标签 color = 'steelblue' # 条形填充色 ) # x轴标签 plt.xlabel('GDP(万亿)') # 标题 plt.title('2017年度6个省份GDP分布情况') # 在每个条形末端添加数值 枚举 for y,x in enumerate(GDP.GDP): plt.text(x+0.1, y, '%s' %round(x,1), va='center') # 显示图形 plt.show()
-
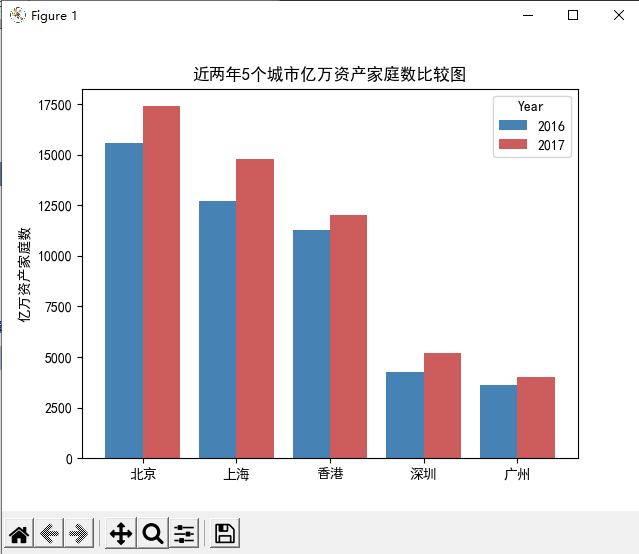
交叉条形图
交叉条形图一般用于比较多组离散型变量的大小。
import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 HuRun = pd.read_excel('HuRun.xlsx') # 制作透视表 HuRun_reshape = HuRun.pivot_table( index = 'City', columns = 'Year', values = 'Counts' ).reset_index() # 降序排列 HuRun_reshape.sort_values( by = 2016, ascending = False, inplace = True ) # 绘图,类型指定为条形 HuRun_reshape.plot( x = 'City', y = [2016,2017], # x轴一项对应多个值 kind = 'bar', color = ['steelblue', 'indianred'], rot = 0, # 标签旋转角度,默认0-水平 width = 0.8, title = '近两年5个城市亿万资产家庭数比较图' ) # y轴标签 plt.ylabel('亿万资产家庭数') # 这里x不需要标签,置空 plt.xlabel('') # 显示图形 plt.show()
-
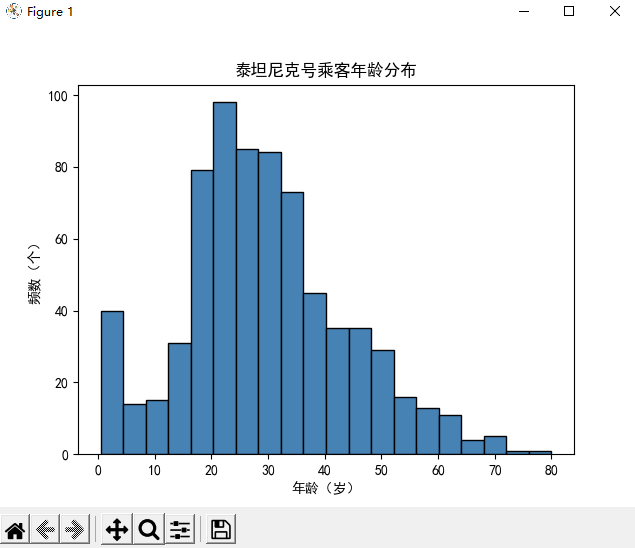
直方图
直方图一般用于观察数据的分布形态,和核密度图搭配使用,能更加清洗地掌握数据分布特征。
横坐标——数值均匀分段;纵坐标——每段内的数量
plt.hist( x, bins=10, normed=False, orientation='vertical', color=None, label=None ) # 参数说明 1.x:需要绘图的数据 2.bins:直方图条形个数 3.normed:是否将直方图的频数转换成频率 4.orientation:直方图方向,默认vertical——垂直 5.color:填充色 6.edgecolor:边框色 7.label:标签,通过legend()展示图例 '''案例''' import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 Titanic = pd.read_csv('titanic_train.csv') # 校验年龄是否存在缺失值(直方图是连续的,不能使用缺失数据) any(Titanic.Age.isnull()) # 绘图 plt.hist( x = Titanic.Age # 绘图数据 bins = 20, # 条形个数 color = 'steelblue' # 填充色 edgecolor = 'black' # 边框色 ) # x,y轴标签 plt.xlabel('年龄') plt.ylabel('频数') # 标题 plt.tilte('泰坦尼克号乘客年龄分布') # 显示图形 plt.show()
-
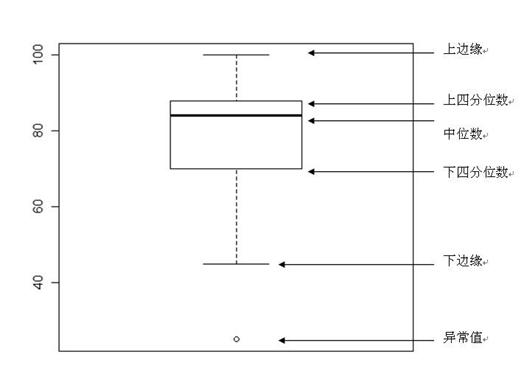
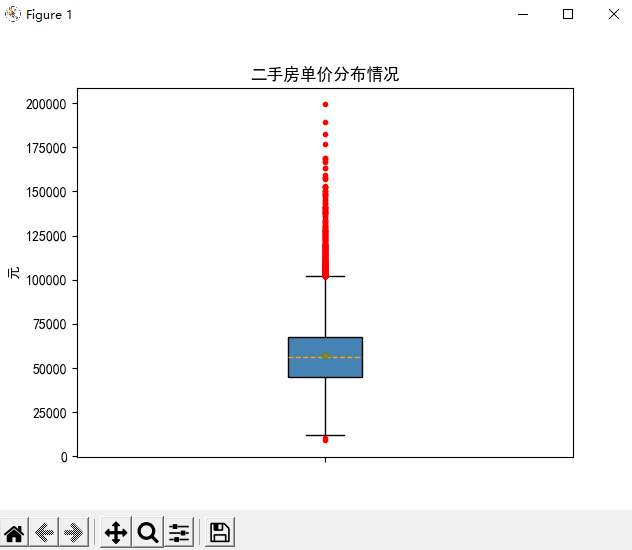
箱线图
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR)。
四分位距:IQR = Q3 − Q1
更重要的是,箱线图还可以发现数据中的异常点。
import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 Sec_Buildings = pd.read_excel('sec_buildings.xlsx') plt.boxplot( x=Sec_Buildings.price_unit, # 绘图数据 patch_artist=True, # 用自定义颜色填充箱体,默认 False-白色 showmeans=True, # 显示均值 boxprops={ 'color': 'black', # 箱体边框色 'facecolor': 'steelblue' # 箱体填充色 }, flierprops={ 'marker': 'o', # 异常点的形状 'markerfacecolor': 'red', # 异常点填充色 'markersize': 3, # 异常点大小 'markeredgecolor': 'red', # 异常点边框色 }, meanprops={ 'marker': 'D', # 均值点的形状 'markerfacecolor': 'indianred', # 均值点填充色 'markersize': 4, # 均值点大小 }, medianprops={ 'linestyle': '--', # 中位数线类型 默认实线 'color': 'orange' # 中位数线颜色 }, labels=[''] # 删除x轴刻度标签,默认显示1 ) plt.ylabel('元') # 标题 plt.title('二手房单价分布情况') # 显示图形 plt.show()
-
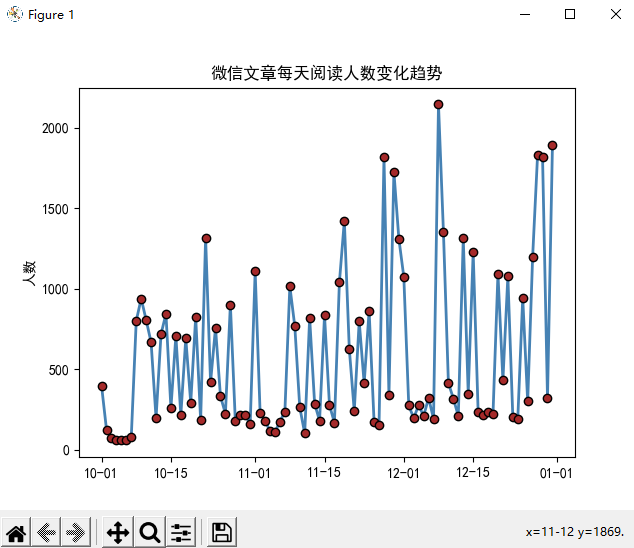
折线图
折线图一般用于反映数据随时间变化的趋势,也可以使用第三个离散型变量对折线进行分组。
横坐标——日期;纵坐标——某数值变量
import matplotlib.pyplot as plt import matplotlib as mpl import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 wechat = pd.read_excel(r'wechat.xlsx') # 绘图 plt.plot( wechat.Date, # x轴数据 wechat.Counts, # y轴数据 linestyle = '-', # 折线类型 linewidth = 2, # 折线宽度 color = 'steelblue', # 折线颜色 marker = 'o', # 折线图添加圆点 markersize = 6, # 点的大小 markeredgecolor = 'black', # 点的边框色 markerfacecolor = 'brown', # 点的填充色 ) # 获取图的坐标 ax = plt.gca() # 设置日期显示格式 date_format = mpl.dates.DateFormatter('%m-%d') ax.xaxis.set_major_formatter(date_format) # y轴标签 plt.ylabel('人数') # 图形标题 plt.title('微信文章每天阅读人数变化趋势') # 显示图形 plt.show()
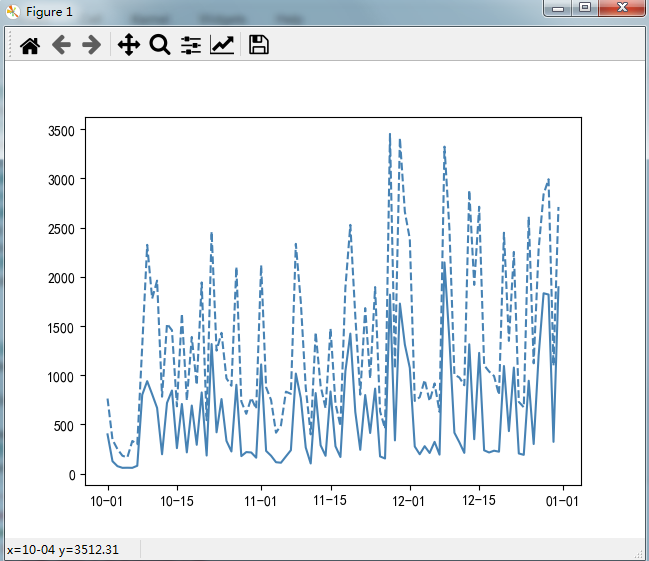
双折线
import matplotlib.pyplot as plt import matplotlib as mpl import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 wechat = pd.read_excel(r'wechat.xlsx') '''阅读人数''' plt.plot( wechat.Date, # x轴数据 wechat.Counts, # y轴数据 linestyle = '-', # 折线类型,实线 color = 'steelblue', # 折线颜色 label = '阅读人数' ) '''阅读人次''' plt.plot( wechat.Date, # x轴数据 wechat.Times, # y轴数据 linestyle = '--', # 折线类型,虚线,与上图区分 color = 'steelblue', # 折线颜色 label = '阅读人次' ) # 获取图的坐标 ax = plt.gca() # 设置日期显示格式 date_format = mpl.dates.DateFormatter('%m-%d') ax.xaxis.set_major_formatter(date_format) # 设置x轴显示日期刻度数量 # xlocator = plt.ticker.LinearLocator(10) # 设置x轴每个刻度的间隔天数 xlocator = mpl.ticker.Multiplelocator(7) ax.xaxis.set_major_locator(xlocator) # 将x刻度标签旋转便于展示 plt.xticks(rotation=45) # y轴标签 plt.ylabel('人数') # 标题 plt.title('微信文章每天阅读人数与人次的变化趋势') # 图例 plt.legend() # 显示图形 plt.show()
-
散点图
散点图一般用于展示两个数值型变量之间是否存在关系,如正或负向线性、趋势性的非线性等。
import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 iris = pd.read_csv(r'iris.csv') # 绘图 plt.scatter( x=iris.Petal_Width, # x轴数据 y=iris.Petal_Length, # 指定散点图的y轴数据 color='steelblue' # 指定散点图中点的颜色 ) # 添加x轴和y轴标签 plt.xlabel('花瓣宽度') plt.ylabel('花瓣长度') # 添加标题 plt.title('鸢尾花的花瓣宽度与长度关系') # 显示图形 plt.show()

-
气泡图
气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然。
绘制气泡图仍然使用scatter函数,区别在于函数的s参数被赋予了具体的数值型变量

import matplotlib.pyplot as plt import pandas as pd # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 iris = pd.read_csv(r'iris.csv') # 绘图 plt.scatter( x=iris.Petal_Width, # x轴数据 y=iris.Petal_Length, # 指定散点图的y轴数据 color='steelblue', # 指定散点图中点的颜色 s=iris.Petal_Length**2 # 点的大小 ) # 添加x轴和y轴标签 plt.xlabel('花瓣宽度') plt.ylabel('花瓣长度') # 添加标题 plt.title('鸢尾花的花瓣宽度与长度关系') # 显示图形 plt.show()

-
热力图
热力图也称为交叉填充表,图形最典型的用法就是实现列联表的可视化,即通过图形的方式展现两个离散变量之间的组合关系。
# 使用matplotlib模块绘制热力图不太方便需要借助于seaborn模块 sns.heatmap(data, cmap=None, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white') # 参数说明 1.data:需要绘图的数据 2.cmap:colormap对象,用于热力图的填充色 3.annot:bool类型或data参数形状一样的数组,True——在热力图的每个单元显示数值 4.fmt:单元格数据的显示格式 5.annot_kws:单元格中数值标签的属性,如颜色、大小等 6.linewidths:每个单元格的边框宽度 7.linecolor:每个单元格的边框颜色 '''案例''' import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 Sales = pd.read_excel(r'Sales.xlsx') # 根据交易日期,提取年和月 Sales['year'] = Sales.Date.dt.year Sales['month'] = Sales.Date.dt.month # 统计每年各月份的销售总额(绘制热力图之前,必须将数据转换为交叉表) Summary = Sales.pivot_table( index = 'month', columns = 'year', values = 'Sales', aggfunc = np.sum # 求和 ) # 绘图 sns.heatmap( data = Summary, # 需要绘图的数据 cmap = 'PuBuGn', # 填充色 linewidths = 0.1, # 单元格边框宽度 annot = True, # 显示数值 fmt = '.1e' # 以科学计数法显示 ) # 标题 plt.title('每年各月份销售总额[热力图]') # 显示图形 plt.show()

-
可视化相关模块
1.matplotlib: 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。 2.seaborn: 是一个基于matplotlib的数据可视化模块。 3.highcharts: 是一个用纯JavaScript编写的一个图表库,能够很简单便捷的在web网站或是web应用程序添加有交互性的图表。 4.echarts: 是一个使用 JavaScript 实现的开源可视化库,涵盖各行业图表,满足各种需求,遵循 Apache-2.0 开源协议,免费商用。 # 下载pyecharts模块可以通过python代码调用 5.d3.js: 是最流行的可视化库之一,它被很多其他的表格插件所使用,允许绑定任意数据到DOM,然后将数据驱动转换应用到Document中。你可以使用它用一个数组创建基本的HTML表格。


工作中往往会根据业务需求,将绘制的多个图形组合到一个大图框内,形成类似仪表板的效果。
plt.subplot2grid(shape, loc, rowspan=1, colspan=1, **kwargs) # 参数说明 1.shape:元组类型,组合图框架形状,如2x3矩阵——(2,3) 2.loc:子图位置,第一行第一列——(0,0) 3.rowspan:某个子图所占行数 4.colspan:某个子图所占列数 '''更改组合图布局''' # 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0)) # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (2,3), loc = (0,1)) # 设置第三个子图的布局 ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2) # 设置第四个子图的布局 ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2)
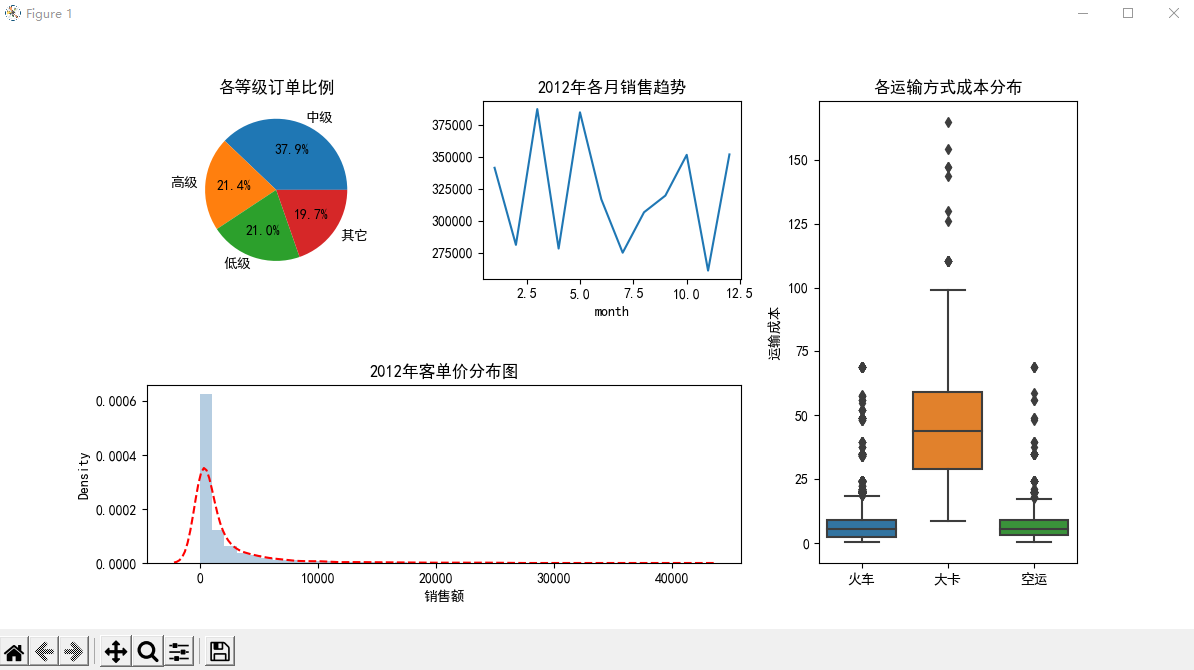
组合图案例
import pandas as pd import matplotlib as plt # 读取数据 Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx') # 提取交易日期的年和月 Prod_Trade['year'] = Prod_Trade.Date.dt.year Prod_Trade['month'] = Prod_Trade.Date.dt.month # 设置大图框的大小 plt.figure(figsize = (12,6)) '''设置第一个子图的布局''' ax1 = plt.subplot2grid(shape = (2,3), loc = (0,0)) # 统计2012年个订单等级的数量 Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year==2012].value_counts() # 绘制订单等级饼图 ax1.pie(x = Class_Percent.values, labels = Class_Percent.index,autopct = '%.1f%%') # 添加标题 ax.set_title('各等级订单比例') '''设置第二个子图的布局''' ax2 = plt.subplot2grid(shape=(2,3), loc = (0,1)) # 统计2012年每月销售额 Month_Sales = Prod_Trade[Prod_Trade.year==2012].groupby(by='month').aggregate({'Sales':np.sum}) # 绘制销售额趋势图 Month_Sales.plot(title='2012年各月销售趋势',ax=ax2,legend=False) '''设置第三个子图的布局''' ax3 = plt.subplot2grid(shape = (2,3), loc = (0,2), rowspan = 2) # 绘制各运输方式的成本箱线图 sns.boxplot(x = 'Transport', y = 'Trans_Cost', data = Prod_Trade, ax = ax3) # 添加标题 ax3.set_title('各运输方式成本分布') # 删除x轴标签 ax3.set_xlabel('') # 修改y轴标签 ax3.set_ylabel('运输成本') '''设置第四个子图的布局''' ax4 = plt.subplot2grid(shape = (2,3), loc = (1,0), colspan = 2) # 2012年客单价分布直方图 sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins = 40, norm_hist = True, ax = ax4, hist_kws = {'color':'steelblue'}, kde_kws=({'linestyle':'--', 'color':'red'})) # 添加标题 ax4.set_title('2012年客单价分布图') # 修改x轴标签 ax4.set_xlabel('销售额') # 调整子图之间的水平间距和高度间距 plt.subplots_adjust(hspace=0.6, wspace=0.3) # 图形显示 plt.show()
-
其它种类的统计图表
1、圆环图
圆环图属于饼图的一种可视化变形,中间可以填写数据,用于观测各类数据大小以及占总数据的比例,显示了各个部分与整体之间的关系。
2、雷达图
雷达图是一种显示多变量数据的图形方法。通常从同一中心点开始等角度间隔地射出三个以上的轴,每个轴代表一个定量变量。可以用来在变量间进行对比,或者查看变量中有没有异常值。

3、矩形树图
矩形树图,是一个由不同大小的嵌套式矩形来显示树状结构数据的统计图表。在矩形树图中,父子层级由矩形的嵌套表示。在同一层级中,所以矩形依次无间隙排布,他们的面积之和代表了整体的大小。
4、面积图
面积图,或称区域图,是一种随有序变量的变化,反映数值变化的统计图表,原理与折线图相似。而面积图的特点在于,折线与自变量坐标轴之间的区域,会由颜色或者纹理填充。
5、漏斗图
用梯形面积表示某个环节业务量与上一个环节之间的差异。适用有固定流程并且环节较多的分析,可以直观地显示转化率和流失率。
-
作业
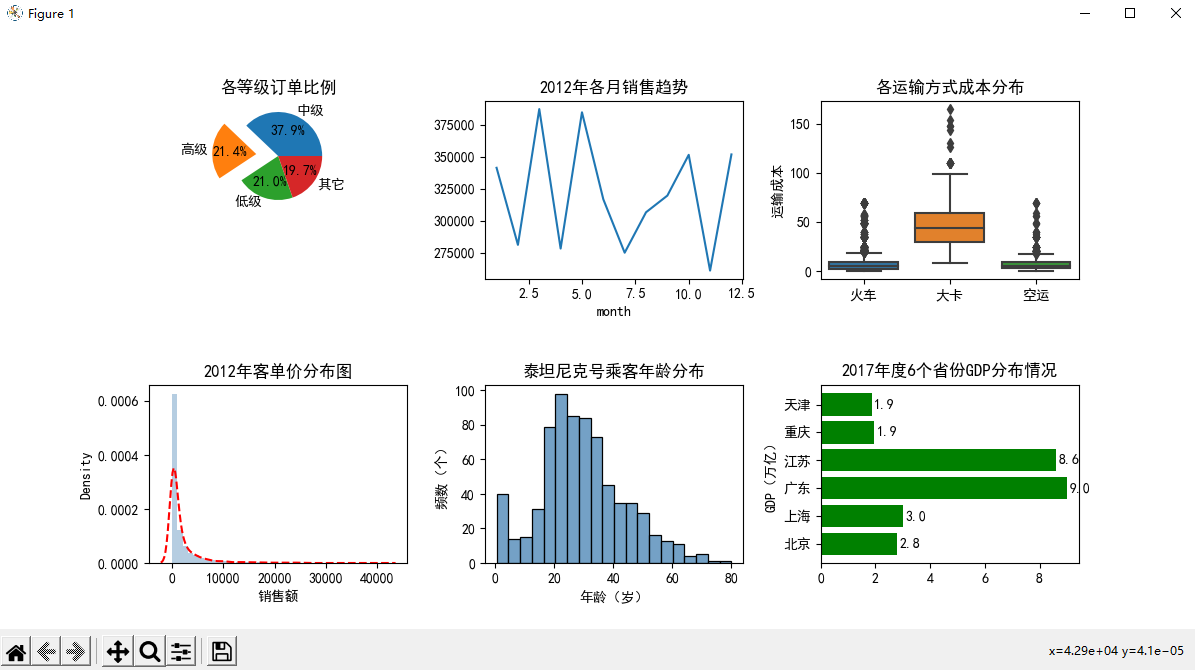
1、多项组合图


import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt # 解决中文乱码 plt.rcParams['font.sans-serif'] = ['SimHei'] # 读取数据 Prod_Trade = pd.read_excel(r'Prod_Trade.xlsx') # 提取交易日期的年和月 Prod_Trade['year'] = Prod_Trade.Date.dt.year Prod_Trade['month'] = Prod_Trade.Date.dt.month # 设置大图框的大小 plt.figure(figsize=(12, 6)) '''设置第一个子图的布局''' ax1 = plt.subplot2grid(shape=(3, 3), loc=(0, 0)) # 统计2012年个订单等级的数量 Class_Counts = Prod_Trade.Order_Class[Prod_Trade.year == 2012].value_counts() Class_Percent = Class_Counts / Class_Counts.sum() # 绘制订单等级饼图 ax1.pie(x=Class_Percent.values, labels=Class_Percent.index, autopct='%.1f%%', explode=[0,0.5,0,0] ) # 添加标题 ax1.set_title('各等级订单比例') '''设置第二个子图的布局''' ax2 = plt.subplot2grid(shape=(2, 3), loc=(0, 1)) # 统计2012年每月销售额 Month_Sales = Prod_Trade[Prod_Trade.year == 2012].groupby(by='month').aggregate({'Sales': np.sum}) # 绘制销售额趋势图 Month_Sales.plot(title='2012年各月销售趋势', ax=ax2, legend=False) '''设置第三个子图的布局''' ax3 = plt.subplot2grid(shape=(2, 3), loc=(0, 2)) # 绘制各运输方式的成本箱线图 sns.boxplot(x='Transport', y='Trans_Cost', data=Prod_Trade, ax=ax3) # 添加标题 ax3.set_title('各运输方式成本分布') # 删除x轴标签 ax3.set_xlabel('') # 修改y轴标签 ax3.set_ylabel('运输成本') '''设置第四个子图的布局''' ax4 = plt.subplot2grid(shape=(2, 3), loc=(1, 0)) # 2012年客单价分布直方图 sns.distplot(Prod_Trade.Sales[Prod_Trade.year == 2012], bins=40, norm_hist=True, ax=ax4, hist_kws={'color': 'steelblue'}, kde_kws=({'linestyle': '--', 'color': 'red'})) # 添加标题 ax4.set_title('2012年客单价分布图') # 修改x轴标签 ax4.set_xlabel('销售额') '''设置第五个子图的布局''' ax5 = plt.subplot2grid(shape=(2, 3), loc=(1, 1)) # 读取数据 Titanic = pd.read_csv('titanic_train.csv') # 校验年龄是否存在缺失值(直方图是连续的,不能使用缺失数据) any(Titanic.Age.isnull()) sns.histplot(Titanic.Age, bins=20, # 条形个数 color='steelblue', # 填充色 edgecolor='black' # 边框色 ) # x,y轴标签 plt.xlabel('年龄(岁)') plt.ylabel('频数(个)') # 标题 plt.title('泰坦尼克号乘客年龄分布') '''设置第六个子图的布局''' ax6 = plt.subplot2grid(shape=(2, 3), loc=(1, 2)) # 读入数据 GDP = pd.read_excel(r'Province GDP 2017.xlsx') # GDP.sort_values(by = 'GDP',inplace = True) # 绘制条形图 plt.barh( y=range(GDP.shape[0]), # y轴刻度 width=GDP.GDP, # x轴数值 tick_label=GDP.Province, # y轴标签 color='green' # 条形填充色 ) # x轴标签 plt.ylabel('GDP(万亿)') # 标题 plt.title('2017年度6个省份GDP分布情况') # 在每个条形末端添加数值 枚举 for y, x in enumerate(GDP.GDP): plt.text(x + 0.1, y, '%s' % round(x, 1), va='center') # 调整子图之间的水平间距和高度间距 plt.subplots_adjust(hspace=0.6, wspace=0.3) # 图形显示 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号