前端编译原理 简述-jison
最近几年的项目技术难点都和编译原理,抽象语法树,代码编辑器 有关系。现在时间有点空,先从基础了解起来,让有些交互和提示能够更智能些。
编译原理-Parser
编译原理 其实就是 让计算机懂的 “437+734” 这样的字符串编程 sum 437, 734 计算机懂得的机器码。实际场景中可能是从一种高级语言编译成一种低级语言。
编译过程份成2个步骤:
1.词法分析
词法分析就是 通过定义的正则表达式,把输入的字符串变成一个个标记(token)。
“437+734” => NUM PLUS NUM
2.语法分析
根据定于的语法,把上边的token通过移进/归约自动机,一步步的移入,规约,变成抽象语法树,最终产生结构。
文法 E => NUM PLUS NUM => sum(437, 734);

这个编译代码的程序我们叫做解析器,分析器,Parser。
解析器生成器 parser generator
在实际情况中,有专门用来生成Parser的程序,解析器生成器。
前端的js语法分析器生成器,还是瞒多的 https://tomassetti.me/parsing-in-javascript/,不同的语法生成器支持的文法也有差别。
JISON介绍
项目中用到的是jison库,这个库支持(lr0, slr, lr1, ll, lalr)文法。一般我们程序中使用的是lalr文法。
可以通过debugger的方式去理解移入规约的过,和jison的使用。http://nolanlawson.github.io/jison-debugger/。
使用起来很简单,官网的文档也比较详细, http://zaa.ch/jison/docs/。定义jison文件,通过 node 命令 "jison 文件"生成Parser的js文件;
jison是bison在js端的实现,但是也不是完全实现了相关的功能。
从http://nolanlawson.github.io/jison-debugger/上就能看到下面的一些文法格式
/* 词法文法 */ %lex /* 选项设置 flex 最长匹配原则 case-insensitive 忽略大小写 */ %options flex case-insensitive %% \s+ /* skip whitespace */ [0-9]+("."[0-9]+)?\b return 'NUMBER' <<EOF>> return 'EOF' /lex /*操作符优先级设置*/ %left '+' '-' %left '*' '/' /*语法开始的非终结符号*/ %start expressions %% /* 词法 */ expressions : e EOF {return $1;} ;
试了下http://dinosaur.compilertools.net/bison/bison_10.html#SEC84,bison文档上面的这个文法不支持,所以使用的时候自己要看着处理

2.jison的输出
jison生成的Parser的输出其实是文法自己定义的,可以是一个结果值,可以是ast树,也可以是用户自己在文法上面定义的结果
3.Parser.js
其实这个可以直接研究下源代码,源代码看起来虽然有些难度,主要是语法分析的逻辑,移入规则逻辑,标示符,终结符,非终结符号等等相关的定义,其他词法的逻辑。
和实际使用中的有的一些变量还是比较容易看懂,或者说debug一下大概就知道有哪些参数了。
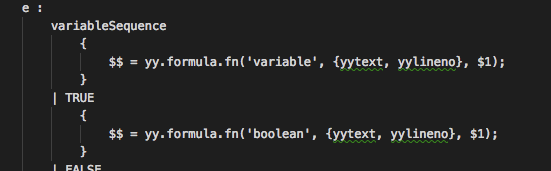
文法定义中的参数
yy: 这个属性是用户自己定义的,在编译期间共享,这样也是代码更加灵活。
4.误区
在使用中,会有一些误区存在,特别是移入规约的顺序,可能和我们平时看代码存在差异。比如说上面的例子。

我们需要在RULE{expr}中的expr内容 有另外一种含义,
但是实际情况的执行顺序其实是先 expr规则规约,才是 RULE{expr}规则规约,所以在进行expr规约的时候并不知道它是在RULE{}里面的,所以我们通过Parser生成ast,再通过ast遍历来解决这个问题可能会更好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号