
Codeforces Round #854 by cybercats (Div. 1+2) 1799 A~G 题解
A. Recent Actions
注意到只有编号大于n的博客会被更新,所以每当有一个之前没被更新的过的博客被更新时,当前列表中最下面的就会被挤掉。如果这次更新的博客之前已经被更新过,那么此时仍在列表中的编号为1-n的博客的顺序不会被改变。所以直接模拟即可。
时间复杂度。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; int t,n,m,p[50010],in[100010],ans[50010]; int main() { fileio(); cin>>t; rep(tn,t) { cin>>n>>m; repn(i,m) scanf("%d",&p[i]); rep(i,n+3) ans[i]=-1; rep(i,n+m+3) in[i]=0; LL cc=0; repn(i,m) { if(in[p[i]]) continue; in[p[i]]=1; ++cc; if(n-cc+1>=0) ans[n-cc+1]=i; } repn(i,n) printf("%d ",ans[i]); puts(""); } termin(); }
B. Equalize by Divide
首先特判所有元素已经相等的情况。其余情况,如果初始最小的数是1,那就是无解,因为你考虑最后一步操作需要把一个不是1的数变成1,但是除以1只能得到本身,是不能变成1的。其余情况,发现只要在数组中还有不相同的元素时任意拿出两个不相同的,并把大的除以小的(保证不会得到1),不断进行下去,总能使得所有元素相等。所以还是直接模拟。
时间复杂度。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define pii pair <int,int> #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; int t,n,a[110]; int main() { fileio(); cin>>t; rep(tn,t) { cin>>n; rep(i,n) cin>>a[i]; if(n==1) { cout<<0<<endl; continue; } int mx=-2e9,mn=2e9; rep(i,n) mx=max(mx,a[i]),mn=min(mn,a[i]); if(mn==1&&mx>1) { puts("-1"); continue; } vector <pii> ans; while(true) { pii mnv=mpr(2e9,2e9),mxv=mpr(-2e9,-2e9); rep(i,n) mnv=min(mnv,mpr(a[i],i)),mxv=max(mxv,mpr(a[i],i)); if(mxv.fi==mnv.fi) break; ans.pb(mpr(mxv.se,mnv.se)); a[mxv.se]=(a[mxv.se]+a[mnv.se]-1)/a[mnv.se]; } cout<<ans.size()<<endl; rep(i,ans.size()) cout<<ans[i].fi+1<<' '<<ans[i].se+1<<endl; } termin(); }
C. Double Lexicographically Minimum
现在的cf,真的是,很多东西只能靠猜。
我们发现构造字符串的策略肯定是,从两边贪心地往中间填,每次尽量填最小的字母。如果某一次填的两个字母不同,就把大的放左边、小的放右边,然后把剩下所有没填的字母从小到大排序放中间,这时就已经得到了答案,可以结束贪心的过程了。
然后来细说怎么贪心。如果当前剩余的最小的字母还剩不止1个,那就前后各填一个这种字母;否则看第二小的字母,如果它也只剩一个,那就填上这两个字母,然后按照上面的方式结束贪心。剩下一种情况,最小的字母只有1个,但第二小的不止一个,这种我们可以观察一下猜个结论:如果剩下的字母除了这两种没有别的,那就前后各填一个第二小的字母然后继续贪心;否则就就填上这两种字母然后按照上面的方式结束贪心。我也不知道这个怎么证明,反正手画了几组没有问题,交上去也是对的。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; int t,cnt[30]; string s,ff,bb; int main() { fileio(); cin>>t; rep(tn,t) { cin>>s; rep(i,28) cnt[i]=0; rep(i,s.size()) ++cnt[s[i]-'a']; ff=bb=""; while(true) { int c1=-1,c2=-1; rep(i,26) if(cnt[i]) { if(c1>-1){c2=i;break;} if(cnt[i]>1){c1=c2=i;break;} c1=i; } if(c1==-1) break; if(c2==-1) { ff.pb(c1+'a'); break; } if(c1==c2){ff.pb(c1+'a');bb.pb(c1+'a');cnt[c1]-=2;} else { bool ok=(cnt[c2]>1); for(int jj=c2+1;jj<26;++jj) if(cnt[jj]) ok=false; if(ok){ff.pb(c2+'a');bb.pb(c2+'a');cnt[c2]-=2;} else { ff.pb(c2+'a');bb.pb(c1+'a'); --cnt[c1];--cnt[c2]; rep(i,26) rep(j,cnt[i]) ff.pb(i+'a'); break; } } } for(int i=(int)bb.size()-1;i>=0;--i) ff.pb(bb[i]); cout<<ff<<endl; } termin(); }
D2. Hot Start Up (hard version)
如果对于某两个(i,j),且我们想要在某个CPU上连续运行i和j,那就说明都不能用这个CPU了。对于任意(i,j)满足,我们把"i与j连续运行"这件事看成一条线段,覆盖区间,它的权值为,代表能省下这么多时间。我们需要选择一些线段,使得没有任意一个位置被一条以上的线段覆盖,同时最大化所有选出线段的权值和。还有一个事情就是如果,且存在k使得,那选择这条线段一定不好,所以不需要考虑这种情况。因此,我们把所有条线段处理出来,然后做一个简答的dp就行了。
时间复杂度。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define pii pair <LL,LL> #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; LL t,n,k,a[300010],c[300010],h[300010],dp[300010],add[300010]; vector <LL> v[300010]; vector <pii> ques[300010]; int main() { fileio(); cin>>t; rep(tn,t) { cin>>n>>k; rep(i,k+3) v[i].clear(); rep(i,n+3) ques[i].clear(); rep(i,n) { scanf("%lld",&a[i]);--a[i]; v[a[i]].pb(i); } rep(i,k) scanf("%lld",&c[i]);rep(i,k) scanf("%lld",&h[i]); LL radd=0; rep(i,k) if(v[i].size()>1) rep(j,v[i].size()-1) { if(v[i][j]+1==v[i][j+1]) radd+=c[i]-h[i]; else ques[v[i][j]+1].pb(mpr(v[i][j+1]-1,c[i]-h[i])); } rep(i,n+3) dp[i]=-1e18; rep(i,n+3) add[i]=0; LL cur=0; rep(i,n+1) { cur=max(cur,add[i]); if(i==n) break; rep(j,ques[i].size()) add[ques[i][j].fi+1]=max(add[ques[i][j].fi+1],cur+ques[i][j].se); } LL ans=0;rep(i,n) ans+=c[a[i]]; ans-=cur+radd; cout<<ans<<endl; } termin(); }
E. City Union
乍一看好像是个比较弱智的题,其实需要一些思考,程序也挺难写的。
"任意两个黑方块之间的最短距离等于它们的曼哈顿距离"其实等价于"不存在一个白方块,使得它的上下两侧都有黑方块,或者它的左右两侧都有黑方块"。这也是很好理解的。所以我们不断地检查有没有这样的白方块,如果有的话就涂黑,直到找不出这样的白方块位置。这一步怎么实现都行,反正复杂度应该不会高于。这一步做完后先进行一个bfs,如果整张图已经连通,直接输出就行了。否则,此时的图一定是两坨黑色的方块,一个在左上一个在右下,或者一个在右上一个在左下。比如一个左上一个右下的情况是这样的:
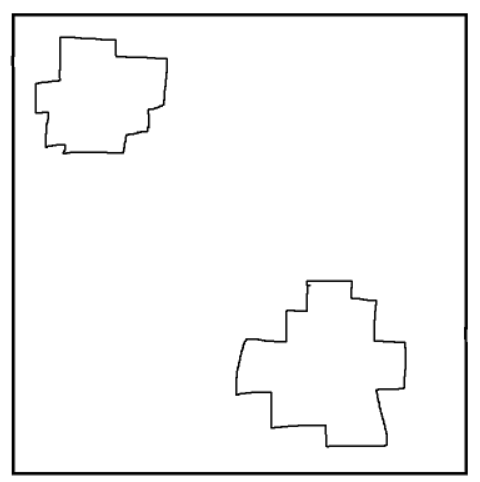
就以这种情况举例。接下来我们要涂黑最少的方块使得两坨东西连通,且不存在上面说的那种白方块。首先涂黑下图中的红色区域,它们是必须被涂黑的。也就是左上一坨的右下角,和右下一坨的左上角:

然后取出左上一坨当前最靠右下的那个位置,以及右下一坨当前最靠左上的那个位置,把它们用任意路径连起来即可。这一步涂黑的方块个数是它们之间的曼哈顿距离-1。可以发现这样构造一定是最优的。
实现就见仁见智了,可能会有点麻烦(听说有人写了9k的,哈人)。我写了3k多点,还算比较简洁。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define pii pair <int,int> #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; void chmax(int &x,int y){if(x<y) x=y;} void chmin(int &x,int y){if(x>y) x=y;} int dx[4]={1,-1,0,0},dy[4]={0,0,1,-1}; int t,n,m,rMost[60],dMost[60]; string s[60]; char c[60]; vector <vector <pii> > v; vector <pii> tmp; bool vis[60][60]; void print() { rep(i,n) printf("%s\n",s[i].c_str()); } bool out(int x,int y){return x<0||x>=n||y<0||y>=m;} void dfs(int x,int y) { vis[x][y]=true;tmp.pb(mpr(x,y)); rep(i,4) { int xx=x+dx[i],yy=y+dy[i]; if(out(xx,yy)||vis[xx][yy]||s[xx][yy]=='.') continue; dfs(xx,yy); } } pii complete(vector <pii> a,pii to) { map <int,int> rmn,rmx; int mnr=2e9,mxr=-2e9; rep(i,a.size()) { if(rmn.find(a[i].fi)==rmn.end()) rmn[a[i].fi]=rmx[a[i].fi]=a[i].se; else chmin(rmn[a[i].fi],a[i].se),chmax(rmx[a[i].fi],a[i].se); chmin(mnr,a[i].fi);chmax(mxr,a[i].fi); } int lr=(to.se<a[0].se ? 0:1),ud=(to.fi<a[0].fi ? 0:1); pii ret=mpr(0,0); if(lr==0) { pii lmost=mpr(2e9,2e9); for(auto it:rmn) lmost=min(lmost,mpr(it.se,it.fi)); ret=mpr((ud==0 ? mnr:mxr),lmost.fi); for(auto it:rmn) if((ud==0&&it.fi<lmost.se)||(ud==1&&it.fi>lmost.se)) { for(int i=it.se-1;i>=lmost.fi;--i) s[it.fi][i]='#'; } } else { pii rmost=mpr(-2e9,-2e9); for(auto it:rmx) rmost=max(rmost,mpr(it.se,it.fi)); ret=mpr((ud==0 ? mnr:mxr),rmost.fi); for(auto it:rmx) if((ud==0&&it.fi<rmost.se)||(ud==1&&it.fi>rmost.se)) { for(int i=it.se+1;i<=rmost.fi;++i) s[it.fi][i]='#'; } } return ret; } void walk(pii x,pii y) { s[x.fi][x.se]='#'; if(abs(x.fi-y.fi)+abs(x.se-y.se)==1) return; if(y.fi<x.fi) walk(mpr(x.fi-1,x.se),y); else if(y.fi>x.fi) walk(mpr(x.fi+1,x.se),y); else if(y.se<x.se) walk(mpr(x.fi,x.se-1),y); else walk(mpr(x.fi,x.se+1),y); } int main() { fileio(); cin>>t; rep(tn,t) { cin>>n>>m; rep(i,n) { scanf("%s",c); s[i]=c; } while(true) { rep(i,n) rMost[i]=-1;rep(i,m) dMost[i]=-1; rep(i,n) rep(j,m) if(s[i][j]=='#') chmax(rMost[i],j),chmax(dMost[j],i); int ok=0; rep(i,n) rep(j,m) if(s[i][j]=='#') { if(j+1<m&&rMost[i]>j&&s[i][j+1]=='.') s[i][j+1]='#',ok=1; if(i+1<n&&dMost[j]>i&&s[i+1][j]=='.') s[i+1][j]='#',ok=1; } if(ok==0) break; } v.clear(); rep(i,n+3) rep(j,m+3) vis[i][j]=false; rep(i,n) rep(j,m) if(s[i][j]=='#'&& !vis[i][j]) { tmp.clear(); dfs(i,j); v.pb(tmp); } if(v.size()==1) { print(); continue; } pii p1=complete(v[0],v[1][0]),p2=complete(v[1],v[0][0]); walk(p1,p2); print(); } termin(); }
F. Halve or Subtract
先把原序列中的所有数分成三类:的为A类,的为B类,的为C类。一个数如果我们要给它做两次操作,那肯定是先1操作再2操作比较划算。我们希望合理地分配这k1+k2次操作,使得它们把原序列减掉的数值尽可能大。
首先对于A类数,把操作施加给它们是很划算的。A类中的每个数不管施加几次操作,其中的2类操作一定能够吃满,也就是产生b的贡献;1类操作也能产生尽量大的贡献。所以我们把A类数从大到小排序,然后给每个数都尽量地施加两种操作,直到k1或k2不够了为止。
令k1和k2分别为处理完A类后剩余的两类操作数。现在就只剩B类和C类的数需要处理了。由于,我们可以枚举给B类施加的1操作次数B1和给B类施加的2操作次数B2,剩下的操作全给C类。
先观察B类。发现被施加1操作的一定是B类中最大的B1个数,因为B类中不被施加1操作的数最多只能产生b的贡献(通过施加一次2操作),而B类中所有数都,所以对于单独的一次2操作来说所有B类数都是一样的。被施加2类操作的数则是所有没被施加1操作的数以及被施加过1操作后剩余的数中最大的B2个。
然后是C类。C类中的数只要被施加了2操作就会变成0,所以对C类中的数施加两种操作完全是浪费。依此可以得出,2操作应施加给C类中最大的C2个数,1操作则施加给剩下的数中最大的C1个(如果C1+C2>|C|也没事,浪费几个1操作好了)。
根据上面的策略模拟就行了。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; LL t,n,b,k1,k2,bpresum[5010],cbig[5010],csmall[5010]; vector <LL> A,B,C; int main() { fileio(); cin>>t; rep(tn,t) { cin>>n>>b>>k1>>k2; LL tot=0,x; A.clear();B.clear();C.clear(); rep(i,n) { scanf("%lld",&x); tot+=x; if(x>=b+b) A.pb(x); else if(x>=b) B.pb(x); else C.pb(x); } sort(A.begin(),A.end());reverse(A.begin(),A.end()); LL ans=0; rep(i,A.size()) { if(k1) { --k1; LL nn=(A[i]+1)/2; ans+=A[i]-nn; A[i]=nn; } if(k2) { --k2; ans+=b; } } sort(B.begin(),B.end());reverse(B.begin(),B.end()); sort(C.begin(),C.end()); rep(i,C.size()) csmall[i+1]=csmall[i]+C[i]/2; reverse(C.begin(),C.end()); rep(i,C.size()) cbig[i+1]=cbig[i]+C[i]; LL opt=0,addi=0; rep(B1,min(k1+1,(LL)B.size()+1)) { rep(B2,min(k2+1,(LL)B.size()+1)) { LL add=addi+b*min((LL)B2,(LL)B.size()-B1); if(B1+B2>B.size()) add+=bpresum[B1+B2-B.size()]; LL C1=min((LL)C.size(),k1-B1),C2=min((LL)C.size(),k2-B2); add+=cbig[C2]; if(C1+C2>=C.size()) add+=csmall[C.size()-C2]; else add+=csmall[C.size()-C2]-csmall[C.size()-C2-C1]; opt=max(opt,add); } if(B1==B.size()) break; bpresum[B1+1]=bpresum[B1]+(B[B1]+1)/2;addi+=B[B1]/2; } ans+=opt; cout<<tot-ans<<endl; } termin(); }
G. Count Voting
小清新数数题。前面的题搞那么毒瘤,然后G放个水题是我不能李姐的。
先来改编一下题意,有n个人,第i个人有一个写了数字i的球,还有个盒子,编号为。每个人需要把球放到一个不同组的盒子里,使得每个盒子里都有1个球,求方案数。把这个问题的答案乘上就是原问题的答案。接下来我们来求这个问题的答案。
先把所有的人按照组别分类,令一共有m个非空组,第i个组中有个人和个盒子。令表示处理了前i个组,前i个组中有j个球是往后m-i个组放的,此时的方案数。由i和j可以得到,前i个组中还有个盒子没被填满。转移的时候枚举当前组中有几个盒子是被前i组往后放的球填满的,以及当前组中有几个球是要用来填前i组中的空盒子的。两次枚举的方案数都是两个组合数相乘,再乘上盒子与球配对的一个阶乘。这样其实就做完了,看似四重循环,其实发现时间复杂度是的。
点击查看代码
#include <bits/stdc++.h> #define rep(i,n) for(int i=0;i<n;++i) #define repn(i,n) for(int i=1;i<=n;++i) #define LL long long #define pii pair <LL,LL> #define fi first #define se second #define pb push_back #define mpr make_pair void fileio() { #ifdef LGS freopen("in.txt","r",stdin); freopen("out.txt","w",stdout); #endif } void termin() { #ifdef LGS std::cout<<"\n\nEXECUTION TERMINATED"; #endif exit(0); } using namespace std; const LL MOD=998244353; LL qpow(LL x,LL a) { LL res=x,ret=1; while(a>0) { if(a&1) (ret*=res)%=MOD; a>>=1; (res*=res)%=MOD; } return ret; } LL n,c[210],t[210],cnt[210],valtot[210],fac[210],inv[210],dp[210][210];//dp[位置][向后投票数] LL cc[210][210]; vector <pii> v; int main() { fileio(); fac[0]=1;repn(i,205) fac[i]=fac[i-1]*i%MOD; rep(i,203) inv[i]=qpow(fac[i],MOD-2); rep(i,202) rep(j,i+1) cc[i][j]=fac[i]*inv[j]%MOD*inv[i-j]%MOD; cin>>n; rep(i,n) cin>>c[i]; rep(i,n) cin>>t[i],--t[i]; LL mull=1; rep(i,n) if(c[i]) (mull*=inv[c[i]])%=MOD; rep(i,n) ++cnt[t[i]],valtot[t[i]]+=c[i]; rep(i,n) if(cnt[i]) v.pb(mpr(cnt[i],valtot[i])); LL curcnt=0,curtot=0; dp[0][0]=1; rep(i,v.size()) { rep(j,curcnt+1) if(dp[i][j]) { LL need=curtot-(curcnt-j);//前面的缺口数 rep(k,min(need+1,v[i].fi+1))//填补缺口数 { LL mul=cc[v[i].fi][k]*cc[need][k]%MOD*fac[k]%MOD; rep(p,min((LL)j+1,v[i].se+1))//被填补的缺口数 { LL mul2=cc[j][p]*cc[v[i].se][p]%MOD*fac[p]%MOD; (dp[i+1][j+v[i].fi-k-p]+=dp[i][j]*mul%MOD*mul2)%=MOD; } } } curcnt+=v[i].fi;curtot+=v[i].se; } cout<<dp[v.size()][0]*mull%MOD<<endl; termin(); }
最近vp了几场上古的cf,对比一下最近的,有一种世风日下的感觉。实在不理解,这些出题人和验题人真觉得往正式比赛里出各种结论题、猜谜题、模拟题、傻逼构造题是一件很好玩的事情么


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话