
查找集合中两个最大的元素
编程之美的中的课后习题:
问题:已知集合S有n个元素x1,x2,….xn,求其中最大的和第二大的元素。
1、朴实的遍历寻找。寻找最大数的比较次数为n-1,第二大为n-2次,总次数2n-3;
2、分治法。
分析:我们要尽可能的减少比较次数,为简单起见,设n为2的幂。
分治:把S分成大小为n/2的两个子集P和Q。如果现在直接进行归纳,则假设已知P和Q中的最大和第二大的元素,分别记为p1,p2和q1,q2,然后查找S中的最大和第二大的元素。很明显,两次比较足以找到S中的这两个元素。第一次比较最大数p1和q1,此时得到一个新的第二大的数,这个数与原来的第二大的数(P或Q中的一个)比较一次,记为所求(比较过程见下图)。用这种方法得出递归关系T(2n)=2T(n)+2及T(2)=1,解得T(n)=3n/2-2。
3、优化:
尽管这要优于直接进行的2n-3次比较,但算法还是可以在改进的。不是每一次找到的最大第二大元素都是有效的,只有到算法的最后我们才能确定最大元素和第二大元素。
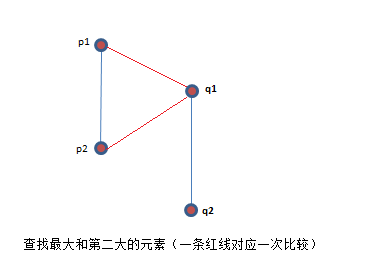
仔细分析上图的比较,可以看出算法不再使用q2,故q2的计算是多余的。如果能精简这样的计算,就可以进一步减少比较次数。然而,在p1和q1比较前,我们并不清楚p2和q2中的哪一个可以不必考虑,如果知道那个子集会“失败”,那么就可以在这个子集上用常规的查找最大数的算法了,这还能省去不少比较。看来我们已经意识到有些比较可以避免,只是不清楚究竟哪些可以忽略,那应该怎么做?
技巧:所以把第二大元素的计算推迟到算法的最后,只保留第二大元素的候选者列表。
归纳(第二次):给定一个小于n的集合,知道如何找到最大的元素以及第二大元素的一个“短短的”候选者列表。
短短的到底有多长尚未定义,但在算法设计过程中,我们会找到一个合适的值。
算法:给定大小为n的集合S,把它分为大小为n/2的字迹P和Q。由归纳假设可知两个集合最大的几个元素是p1和q1,在加上第二大元素的候选者集合Cp和Cq。首先比较p1和q1,取其中大者。例如p1作为S的最大数,然后舍去Cq,因为Cq中的所有元素都小于q1,接着再把q1加入Cp中。最终我们得到了一个最大的元素和一个候选者集合,从中可以直接选出第二大的数。查找最大数所需的比较次数满足递归关系T(n)=2T(n/2)+1及T(2)=1,解得T(n)=n-1。很容易看到,扩大一倍集合的大小时,我们能在候选者集合中再加入一个元素,所以lbn足以满足候选者集合大小的需要。于是查找第二大元素需要lbn-1次额外比较,因而总比较次数为n-1+lbn-1,恰为最可能的次数。n为2的幂时的归纳假设如下:
归纳(第三次):给定一个小于n的集合,知道如何求出最大的元素和第二大的元素的候选者集合,这个集合自多不超过lbn个元素。
代码:
1 vector<int> &get2max(int *a, int len, int &max, vector<int> &can) 2 { 3 if (len==1) 4 { 5 max = a[0]; 6 return can; 7 } 8 else if(len == 2) 9 { 10 if (a[0]>a[1]) 11 { 12 max = a[0]; 13 can.push_back(a[1]); 14 } 15 else 16 { 17 max = a[1]; 18 can.push_back(a[0]); 19 } 20 return can; 21 } 22 23 int pmax, qmax; 24 vector<int> &pcan = *new vector<int>; 25 vector<int> &qcan = *new vector<int>; 26 27 pcan = get2max(a, len/2, pmax, pcan); 28 qcan = get2max(a+len/2, len-len/2, qmax, qcan); 29 30 if (pmax > qmax) 31 { 32 max = pmax; 33 pcan.push_back(qmax); 34 delete &qcan; 35 return pcan; 36 } 37 else if (pmax < qmax) 38 { 39 max = qmax; 40 qcan.push_back(pmax); 41 delete &pcan; 42 return qcan; 43 } 44 else 45 { 46 max = pmax; 47 pcan.clear(); 48 pcan.push_back(pmax); 49 delete &qcan; 50 return pcan; 51 } 52 53 } 54 55 void get2max(int *a, int n) 56 { 57 int max,sec_max; 58 vector<int> can; 59 vector<int>::iterator it; 60 61 if (n<=0 ) 62 { 63 return; 64 } 65 can = get2max(a, n, max, can); 66 67 it = can.begin(); 68 sec_max = *it; 69 for (++it; it!=can.end(); ++it) 70 { 71 if (*it > sec_max) 72 { 73 sec_max = *it; 74 } 75 } 76 77 cout<<"First max:"<<max<<endl; 78 cout<<"Second max:"<<sec_max<<endl; 79 }
其实文章算是转载了:http://blog.csdn.net/lzj509649444/article/details/7074524
有些东西值得学习:
总结:如何改进一个算法,首先要看到这个算法的缺点,有时候在脑子里面运行一遍这个程序,缺点就暴露出来了。所以有必要检查是否存在对最终结果不起作用的部分,这些部分往往可以被删除,即使不能被删除,也可以用更简单、效率更高的运算代替。
分治算法会产生一些中间结果,并不是这些中间结果都对我们的最终结果有所帮助。
毕
