
python获取doc文件中超链接和文本
代码
from docx import Document
from docx.opc.constants import RELATIONSHIP_TYPE as RT
import re
#存放超链接
target = {}
#存放超链接文本
text = []
d = Document("material/测试.docx")
#获取超链接
rels = d.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
id = rels[rel]._rId
id = int(id[3:])
target[id] = rels[rel]._target
#通过rid进行排序
target = [(k, target[k]) for k in sorted(target.keys())]
#获取超链接文本
for p in d.paragraphs:
# 将文档处理为xml,并转为字符串
xml = p.paragraph_format.element.xml
xml_str = str(xml)
#获取文本中由<w:hyperlink>标签包起来的部分
hl_list = re.findall('<w:hyperlink[\S\s]*?</w:hyperlink>', xml_str)
for hyperlink in hl_list:
# 获取文本中由<w:t>标签包起来的部分
wt_list = re.findall('<w:t[\S\s]*?</w:t>', hyperlink)
temp = u''
for wt in wt_list:
# 去掉<w:t>标签
wt_content = re.sub('<[\S\s]*?>', u'', wt)
temp += wt_content
text.append(temp)
# #输出结果
# for i in range(0, len(target)):
# print(text[i] + " " + target[i])
效果
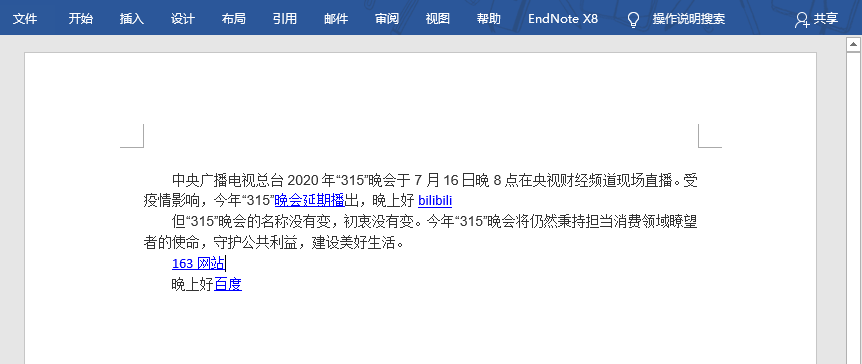
待处理文件
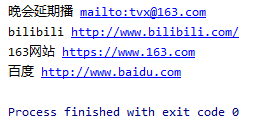
处理结果
了解docx文件结构
①将docx文件后缀名改为zip
②对zip文件进行解压
使用vscode打开改文件夹,查看两个关键文件
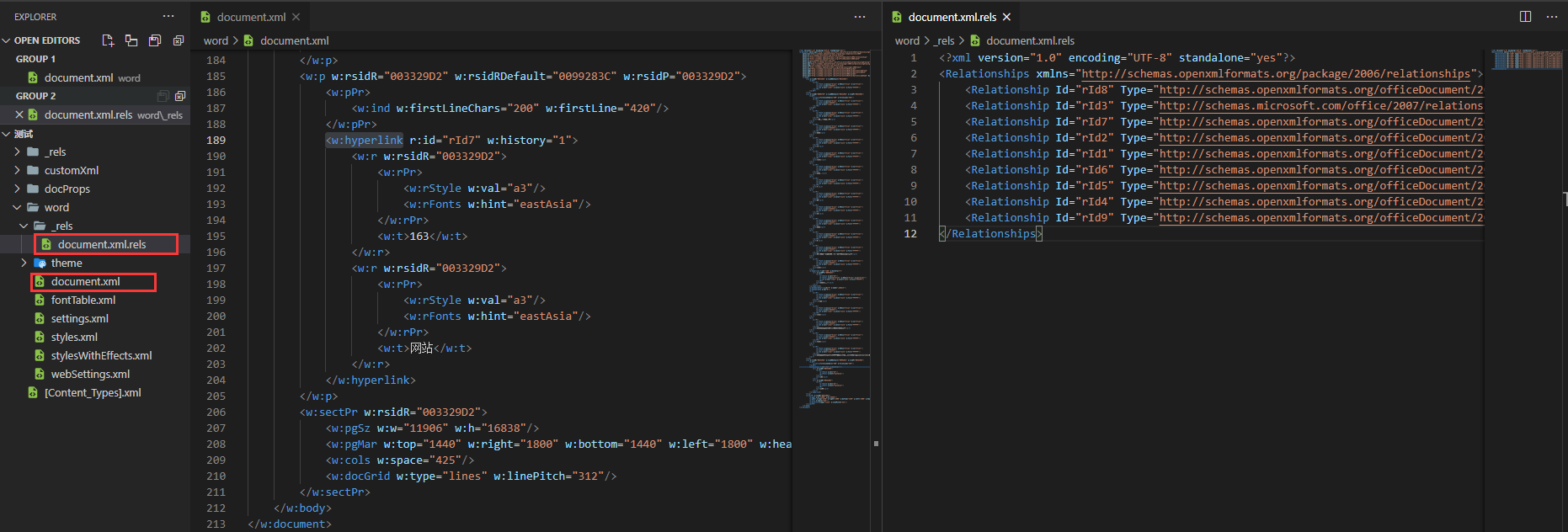
通过阅读发现
超链接的目标网址及其文本通过id属性关联
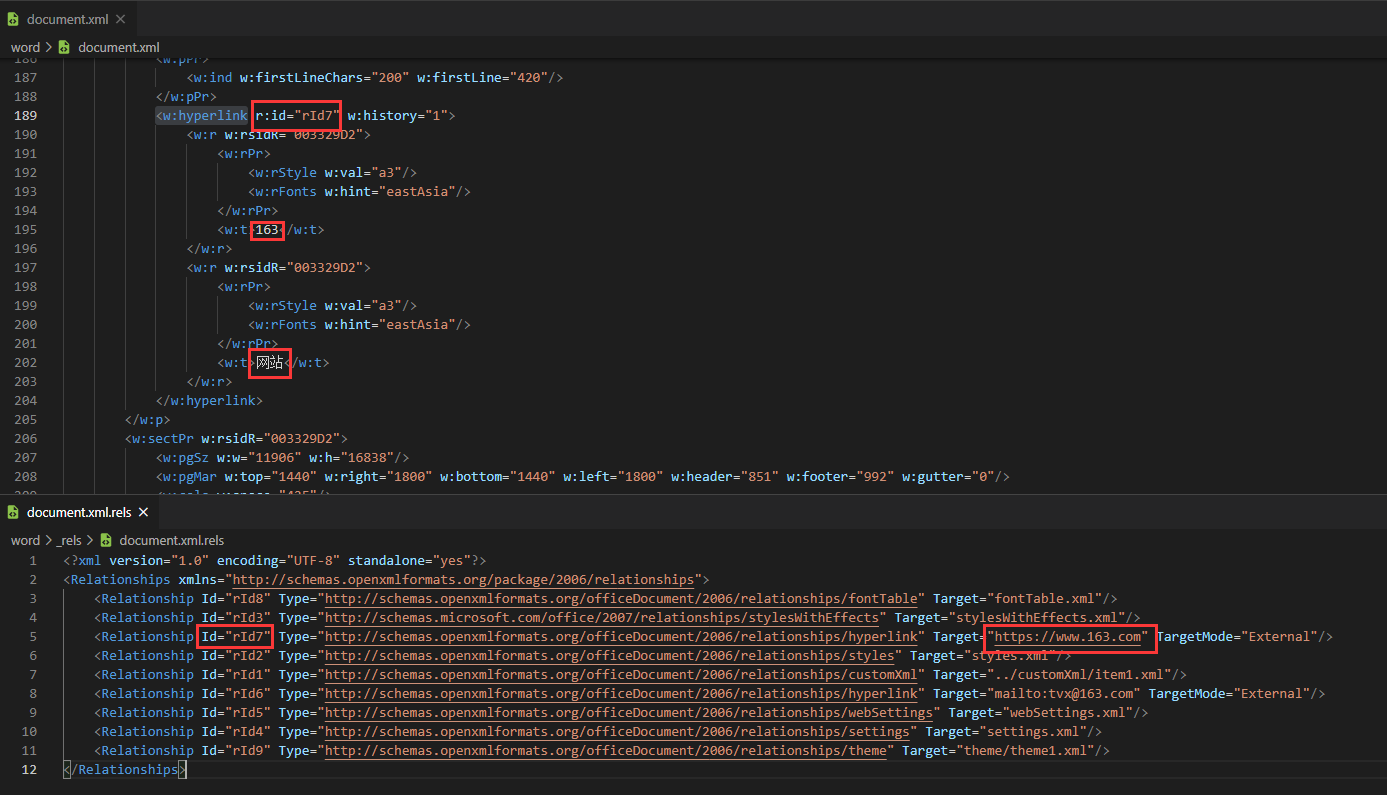
获取超链接
通过以下代码可输出document.xml.rels中超链接的相关属性
from docx import Document
from docx.opc.constants import RELATIONSHIP_TYPE as RT
d = Document("material/测试.docx")
rels = d.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
print('\n'.join(['%s:%s' % item for item in rels[rel].__dict__.items()]))
# print(" 超链接网址为: ", rels[rel]._target)
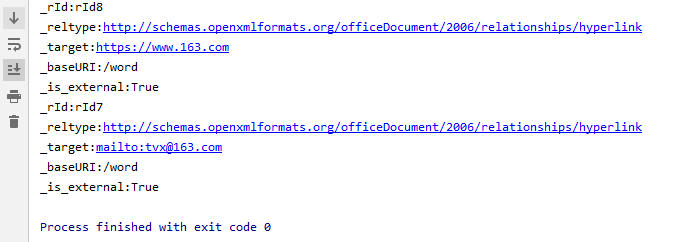
由于rId的顺序不是恰好和文本出现的顺序一样
因此还需要进行排序
#存放超链接
target = {}
#存放超链接文本
text = []
d = Document("material/测试.docx")
#获取超链接
rels = d.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
id = rels[rel]._rId
id = int(id[3:])
target[id] = rels[rel]._target
#通过rid进行排序
target = [(k, target[k]) for k in sorted(target.keys())]
获取超链接的文本
虽然知道了超链接的目标和文本是通过id关联的
但是奈何没能找到相关的操作,于是使用了下面的方法来处理
即将document.xml处理为字符串,并获取hyperlink标签中的文本
from docx import Document
from docx.opc.constants import RELATIONSHIP_TYPE as RT
import re
#存放超链接
target = {}
#存放超链接文本
text = []
d = Document("material/测试.docx")
#获取超链接文本
for p in d.paragraphs:
# 将文档处理为xml,并转为字符串
xml = p.paragraph_format.element.xml
xml_str = str(xml)
#获取文本中由<w:hyperlink>标签包起来的部分
hl_list = re.findall('<w:hyperlink[\S\s]*?</w:hyperlink>', xml_str)
for hyperlink in hl_list:
# 获取文本中由<w:t>标签包起来的部分
wt_list = re.findall('<w:t[\S\s]*?</w:t>', hyperlink)
temp = u''
for wt in wt_list:
# 去掉<w:t>标签
wt_content = re.sub('<[\S\s]*?>', u'', wt)
temp += wt_content
text.append(temp)
参考资料:
Python如何提取docx中的超链接——https://blog.csdn.net/s1162276945/article/details/102919305
python:对dict排序——https://blog.csdn.net/sinat_20177327/article/details/82319473

 浙公网安备 33010602011771号
浙公网安备 33010602011771号