日志段信息过滤
在日常的日志解析当中,我们可能需要实现对日志中的某一特殊段进行信息的过滤,
下面介绍一下我的常用方法。
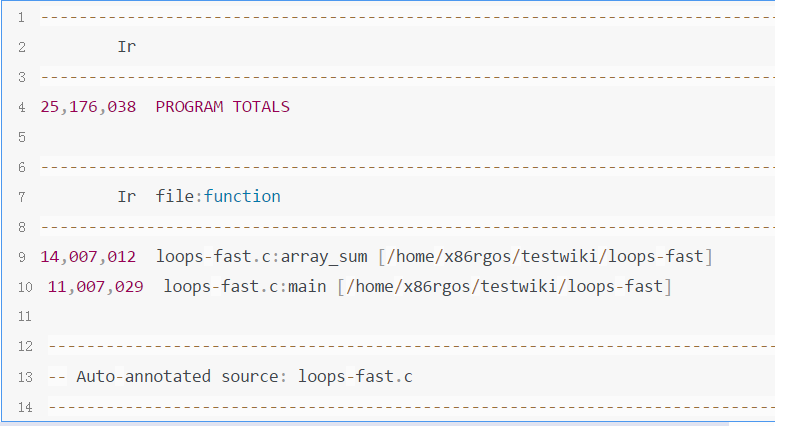
针对这个日志输出信息,其实我主要关注的是下面这个日志段内的信息
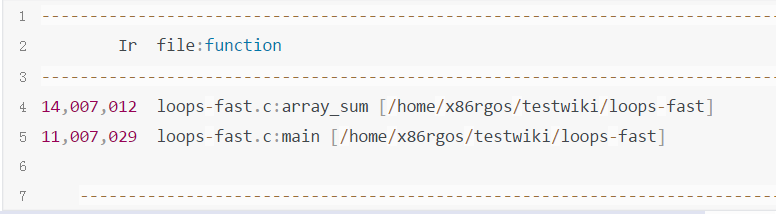
那么其实我就是想获取含有'loops-fast'这个字符串的数据,而过滤掉其他的干扰数据,我分为以下几个步骤实现
- 首先要确定边界值,也就是你要截取的段的开头和结尾的特殊字段,这个很重要
- 接着我们需要设置一个tag值,通过这个tag值我们可以判断当前是不是在需要过滤的日志段内
- 编码的时候主要是通过tag值和关键字一起进行判断
- 考虑到性能可以适当调整判断的顺序,也就是将需要大部分可能出现的判断提前了,并且在判断结束之后及时退出判断
下面是实现的代码
file_data = "" tag = 0 with open(filename, "rb") as file: temp = str(file.read().decode('utf-8','ignore')) list = temp.split('\n') file.close() #主要过滤实现 for line in list: if tag == 0: file_data = file_data + line + '\n' if "Ir file:function" in line: tag = 1 file_data = file_data + '--------------------------------------------------------------------------------\n' if ‘loops-fast’ in line and tag == 1: file_data = file_data + line + '\n' functionIr2dict(line,dire_ir) if "Auto-annotated source" in line and tag == 1: tag = 0 file_data = file_data + '--------------------------------------------------------------------------------\n' file_data = file_data + line + '\n' with open(filename,'w',encoding='utf-8') as file: file.write(file_data) file.close()


