6.Hadoop MapReduce
6.1编辑WordCount.java
创建wordcount测试目录

编辑WordCount.java

输入下面代码:
可以访问https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html查看
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
可以看到创建的java文件
6.2编译WordCount.java文件
编辑~/.bashrc文件:sudo gedit ~/.bashrc
输入:
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar

让文件生效:source ~/.bashrc
编译程序:hadoop com.sun.tools.javac.Main WordCount.java -Xlint:deprecation
打包成wc.jar:jar cf wc.jar WordCount*.class
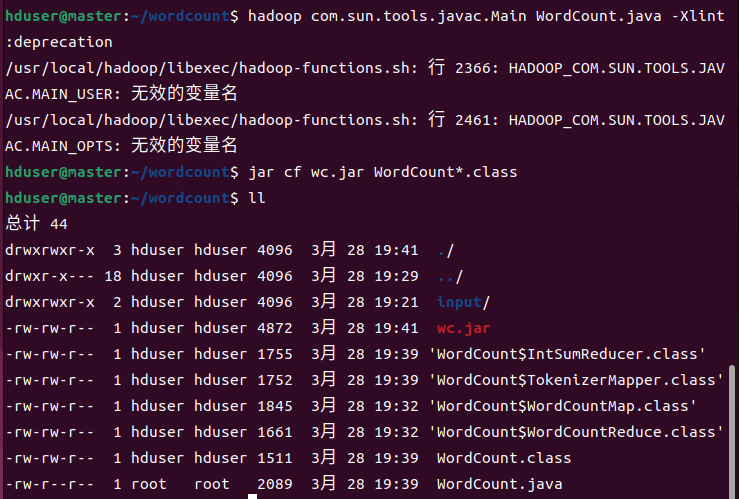
6.3创建测试文本文件
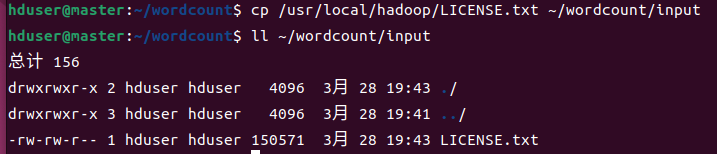
启动所有虚拟机,启动Hadoop Multi-Node Cluster
在HDFS创建目录:hadoop fs -mkdir -p /user/hduser/wordcount/input
cd ~/wordcount/input
上传文件:hadoop fs -copyFromLocal LICENSE.txt /user/hduser/wordcount/input
查看:

6.4运行WordCount.java
切换目录:cd ~/wordcount
运行WordCount程序:
hadoop jar wc.jar WordCount /user/hduser/wordcount/input/LICENSE.txt /user/hduser/wordcount/output
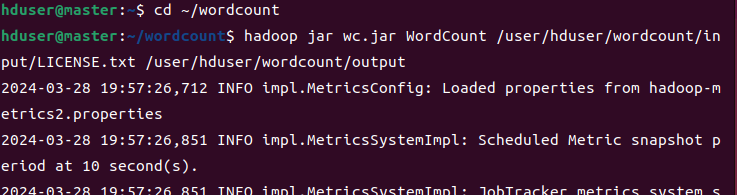
查看运行结果
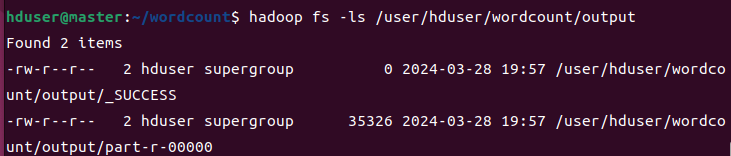
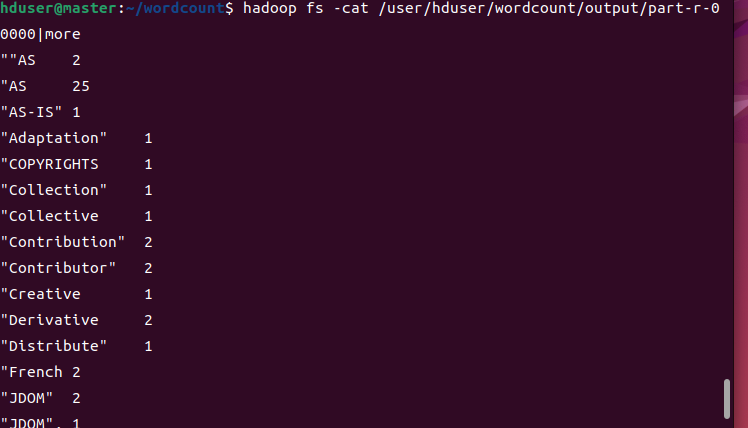
hadoop fs -cat /user/hduser/wordcount/output/part-r-00000|more
删除输出目录


 浙公网安备 33010602011771号
浙公网安备 33010602011771号