leetcode题解之46. 全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
https://www.jianshu.com/p/c6cc3714a9ac
输入: [1,2,3] 输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
📺视频题解

📖文字题解
预备知识
- 回溯法 :一种通过探索所有可能的候选解来找出所有的解的算法。如果候选解被确认不是一个解的话(或者至少不是最后一个解),回溯算法会通过在上一步进行一些变化抛弃该解,即回溯并且再次尝试。
方法一:搜索回溯
思路和算法
这个问题可以看作有 个排列成一行的空格,我们需要从左往右依此填入题目给定的 个数,每个数只能使用一次。那么很直接的可以想到一种穷举的算法,即从左往右每一个位置都依此尝试填入一个数,看能不能填完这 个空格,在程序中我们可以用「回溯法」来模拟这个过程。
我们定义递归函数 backtrack(first, output) 表示从左往右填到第 个位置,当前排列为 。 那么整个递归函数分为两个情况:
- 如果 ,说明我们已经填完了 个位置(注意下标从 开始),找到了一个可行的解,我们将 放入答案数组中,递归结束。
- 如果 ,我们要考虑这第 个位置我们要填哪个数。根据题目要求我们肯定不能填已经填过的数,因此很容易想到的一个处理手段是我们定义一个标记数组 来标记已经填过的数,那么在填第 个数的时候我们遍历题目给定的 个数,如果这个数没有被标记过,我们就尝试填入,并将其标记,继续尝试填下一个位置,即调用函数
backtrack(first + 1, output)。搜索回溯的时候要撤销这一个位置填的数以及标记,并继续尝试其他没被标记过的数。
使用标记数组来处理填过的数是一个很直观的思路,但是可不可以去掉这个标记数组呢?毕竟标记数组也增加了我们算法的空间复杂度。
答案是可以的,我们可以将题目给定的 个数的数组 划分成左右两个部分,左边的表示已经填过的数,右边表示待填的数,我们在递归搜索的时候只要动态维护这个数组即可。
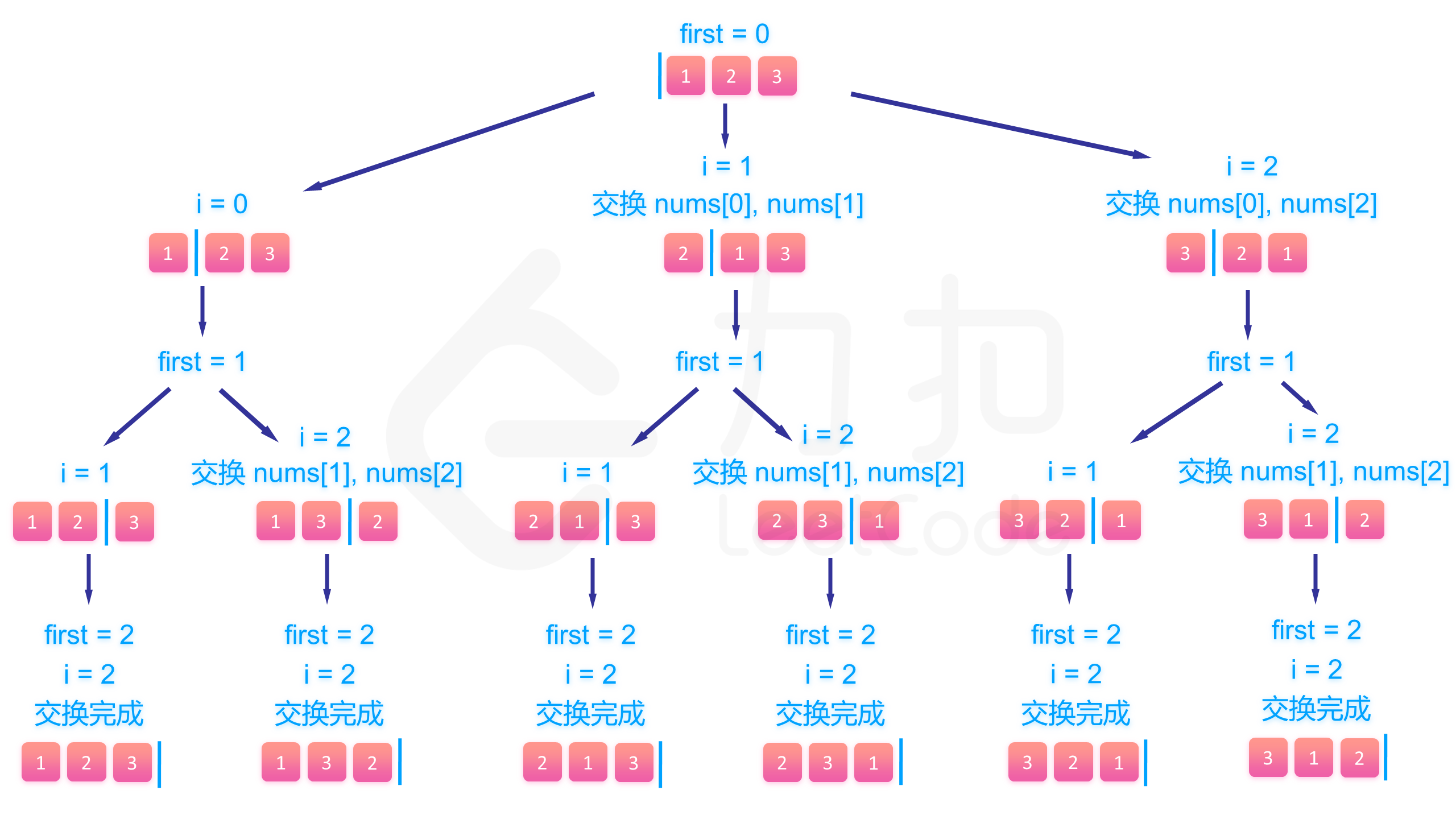
具体来说,假设我们已经填到第 个位置,那么 数组中 是已填过的数的集合, 是待填的数的集合。我们肯定是尝试用 里的数去填第 个数,假设待填的数的下标为 ,那么填完以后我们将第 个数和第 个数交换,即能使得在填第 个数的时候 数组的 部分为已填过的数, 为待填的数,回溯的时候交换回来即能完成撤销操作。
举个简单的例子,假设我们有 [2, 5, 8, 9, 10] 这 5 个数要填入,已经填到第 3 个位置,已经填了 [8,9] 两个数,那么这个数组目前为 [8, 9 | 2, 5, 10] 这样的状态,分隔符区分了左右两个部分。假设这个位置我们要填 10 这个数,为了维护数组,我们将 2 和 10 交换,即能使得数组继续保持分隔符左边的数已经填过,右边的待填 [8, 9, 10 | 2, 5] 。
当然善于思考的读者肯定已经发现这样生成的全排列并不是按字典序存储在答案数组中的,如果题目要求按字典序输出,那么请还是用标记数组或者其他方法。
下面的图展示了搜索的整个过程:

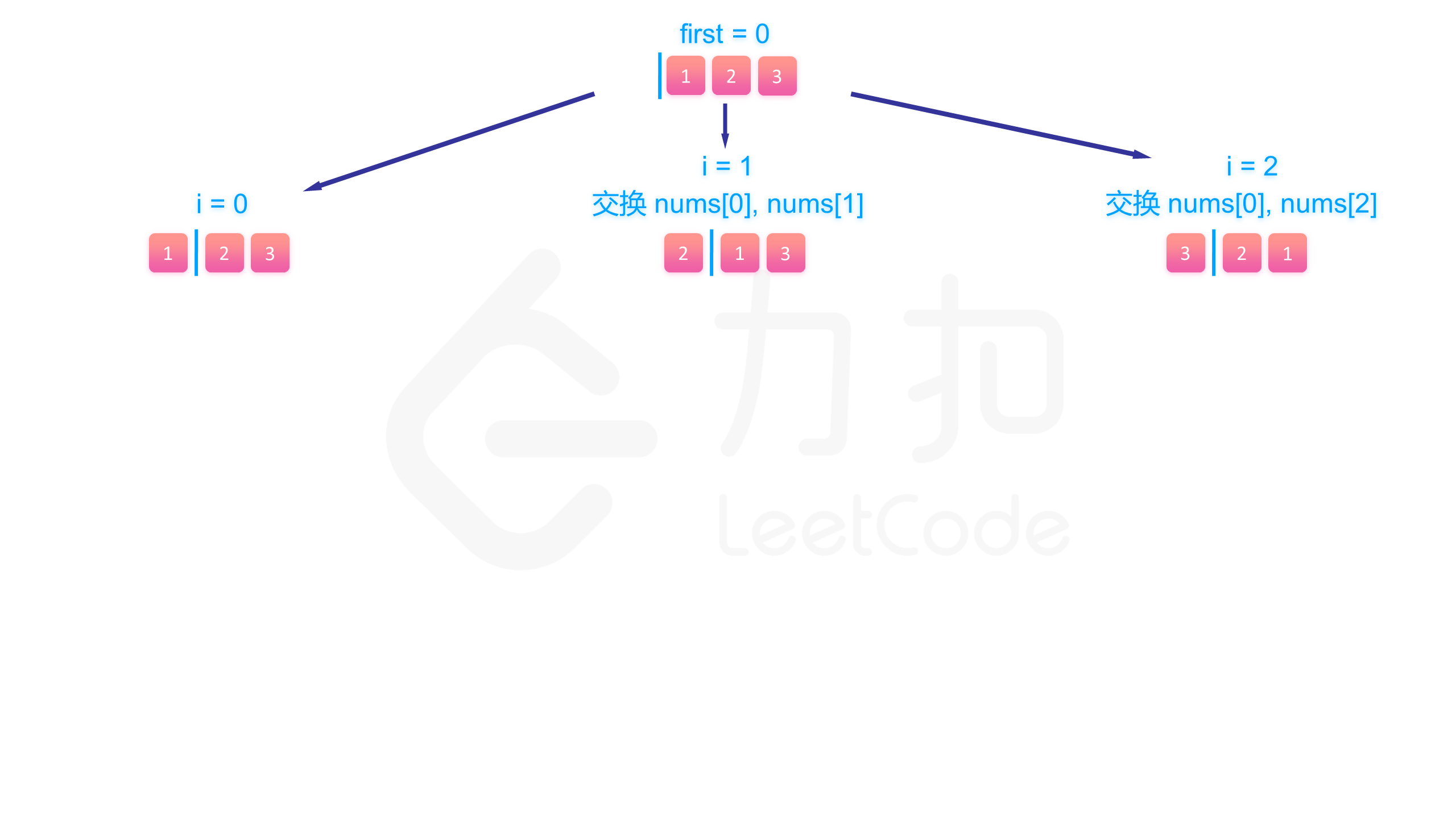
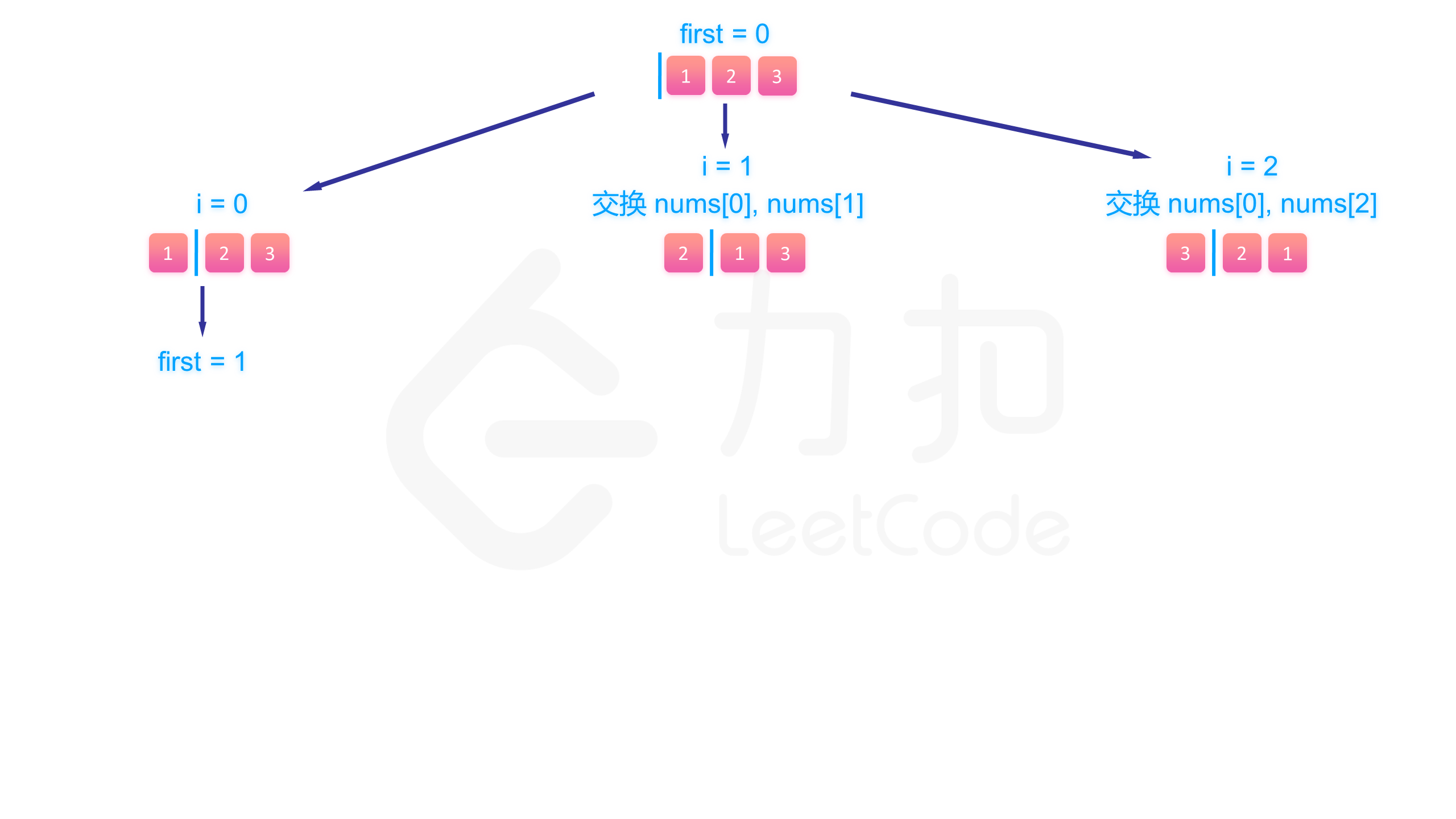
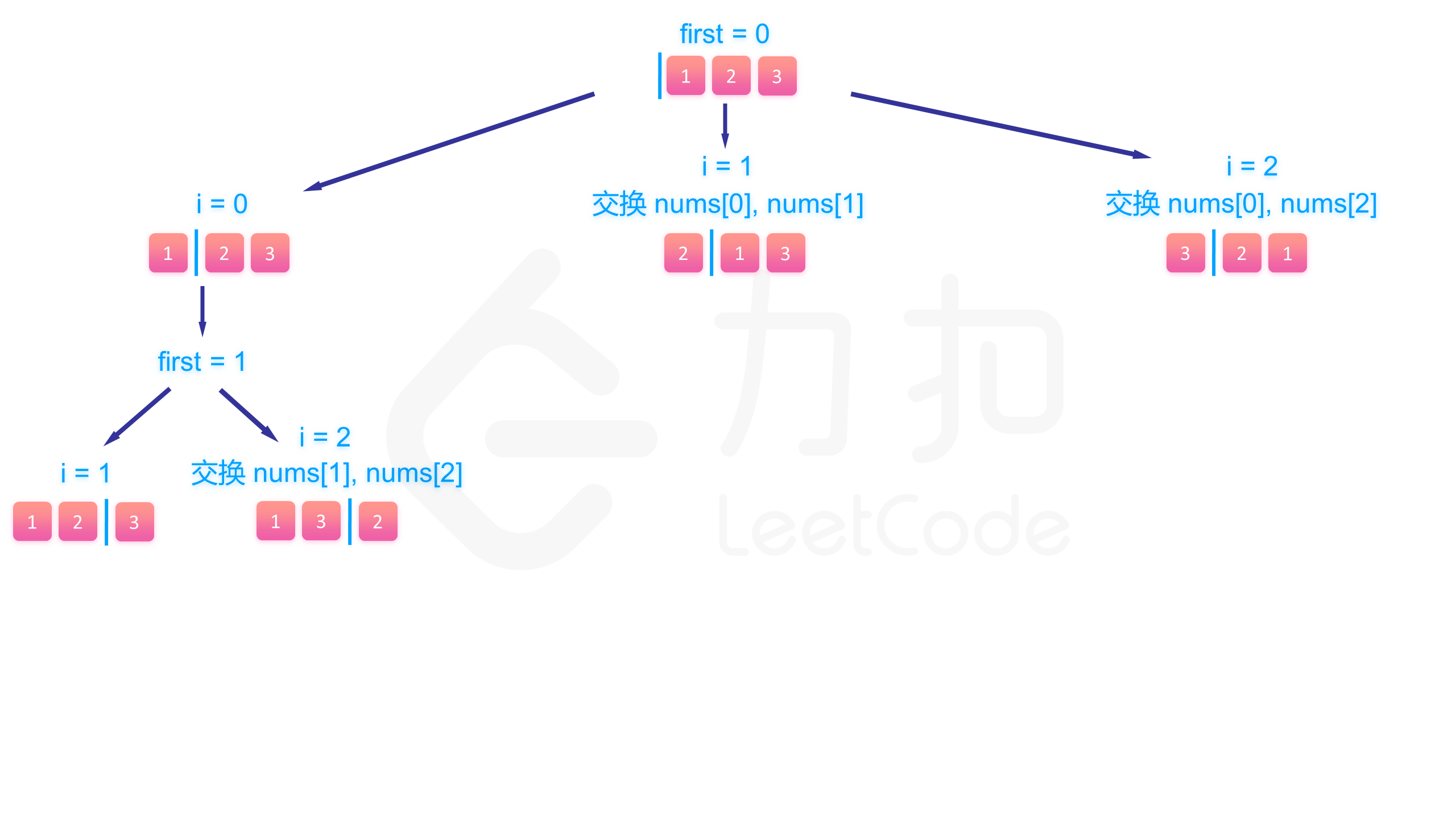
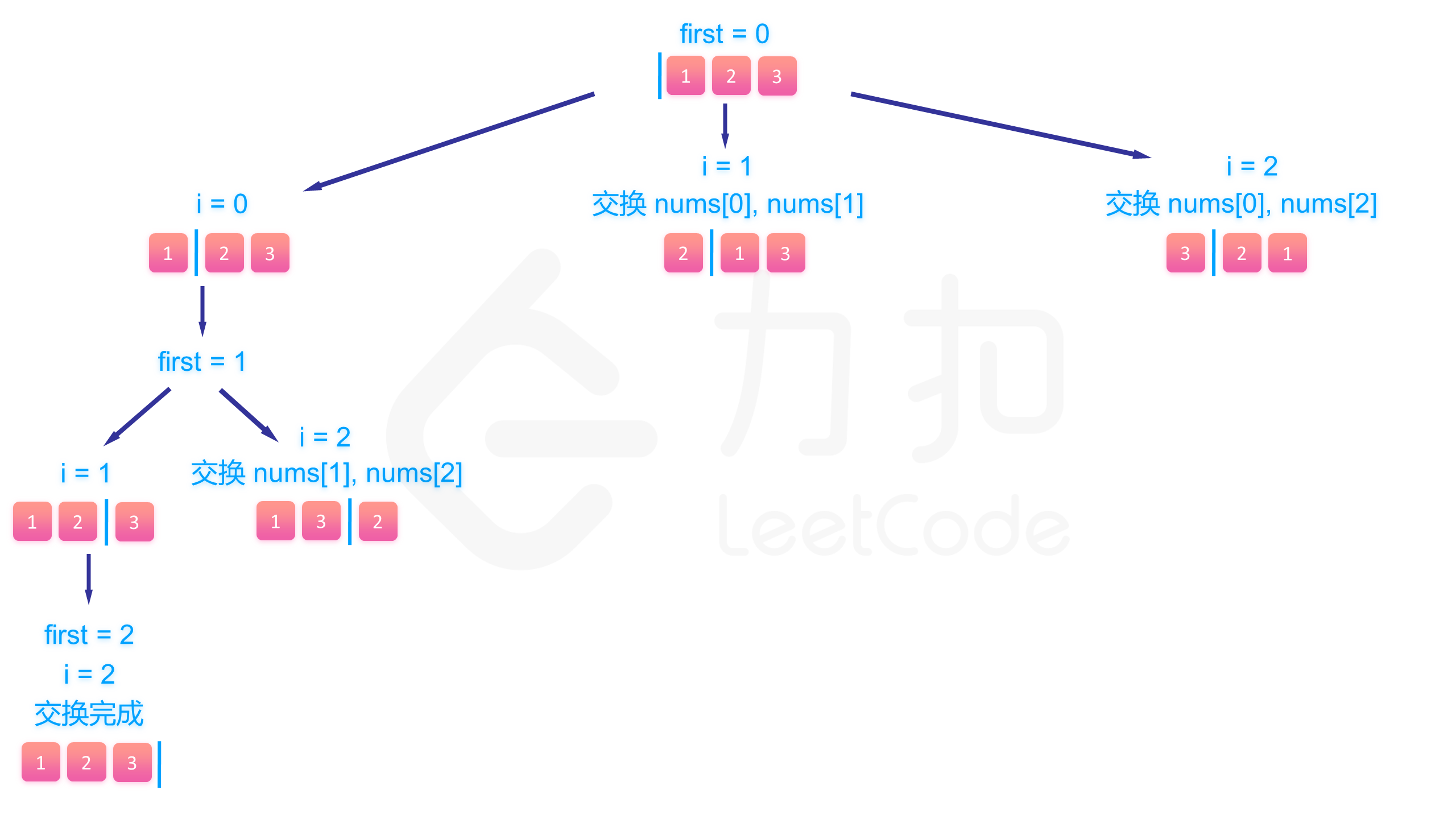
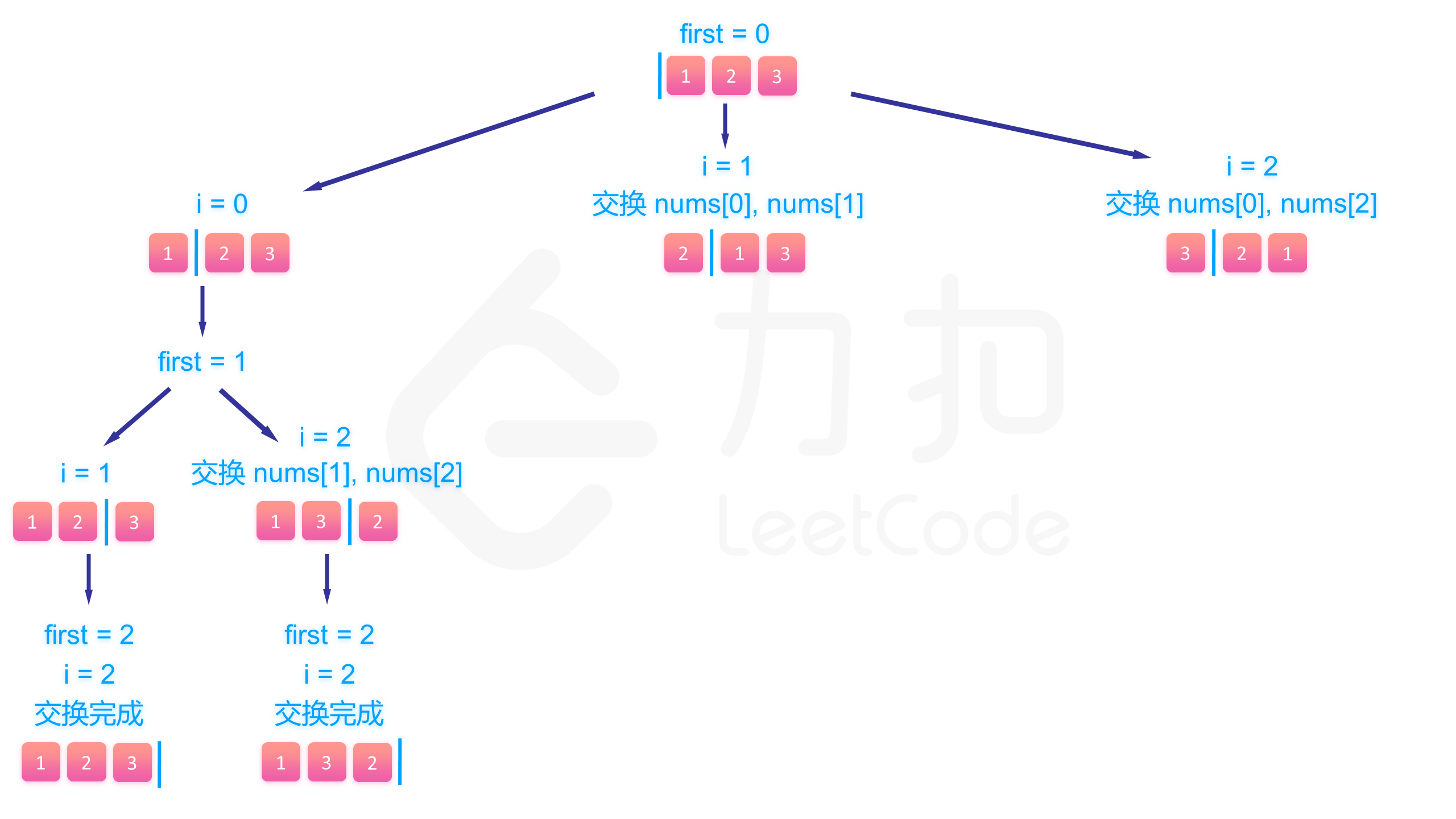
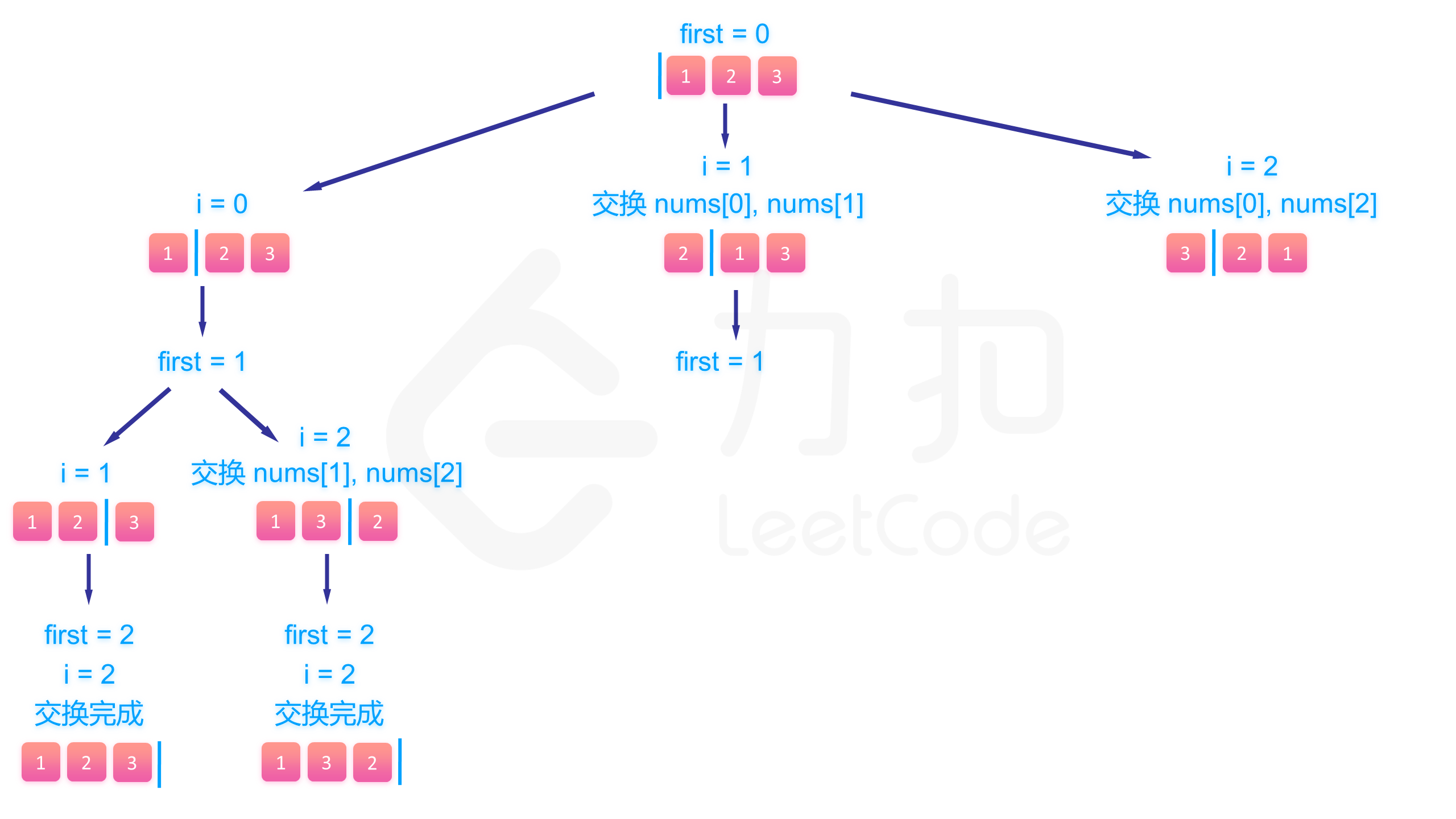
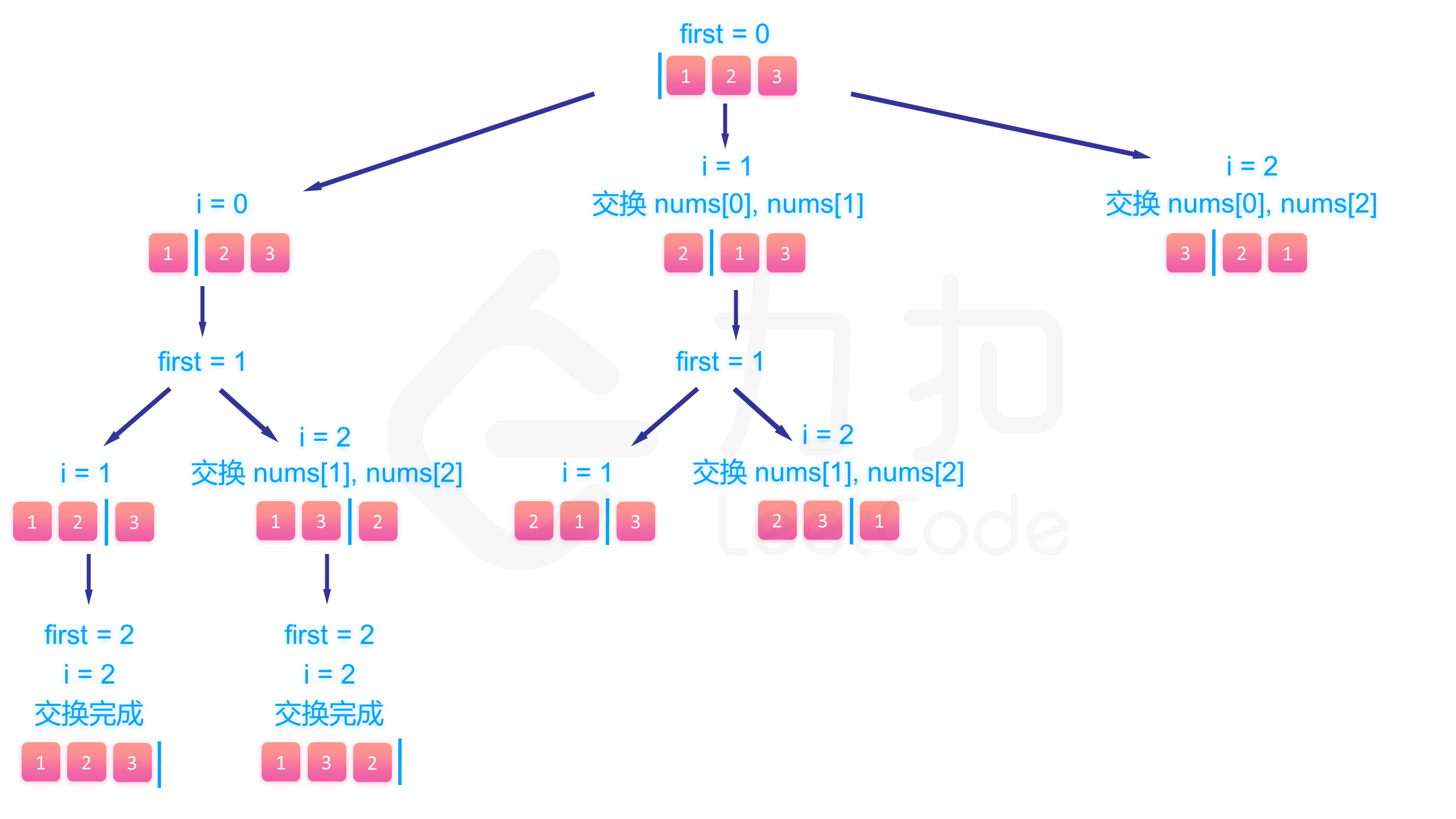
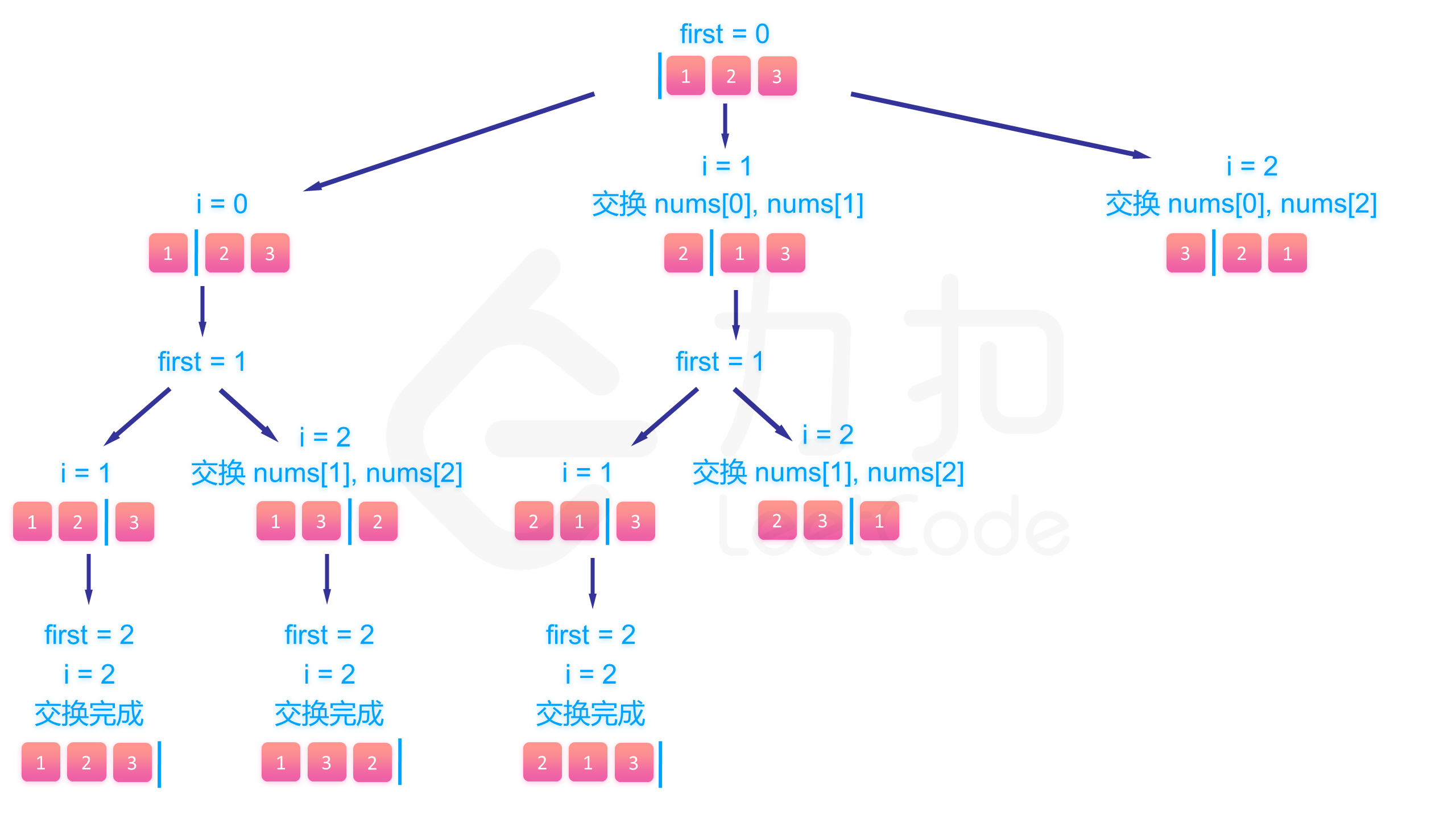
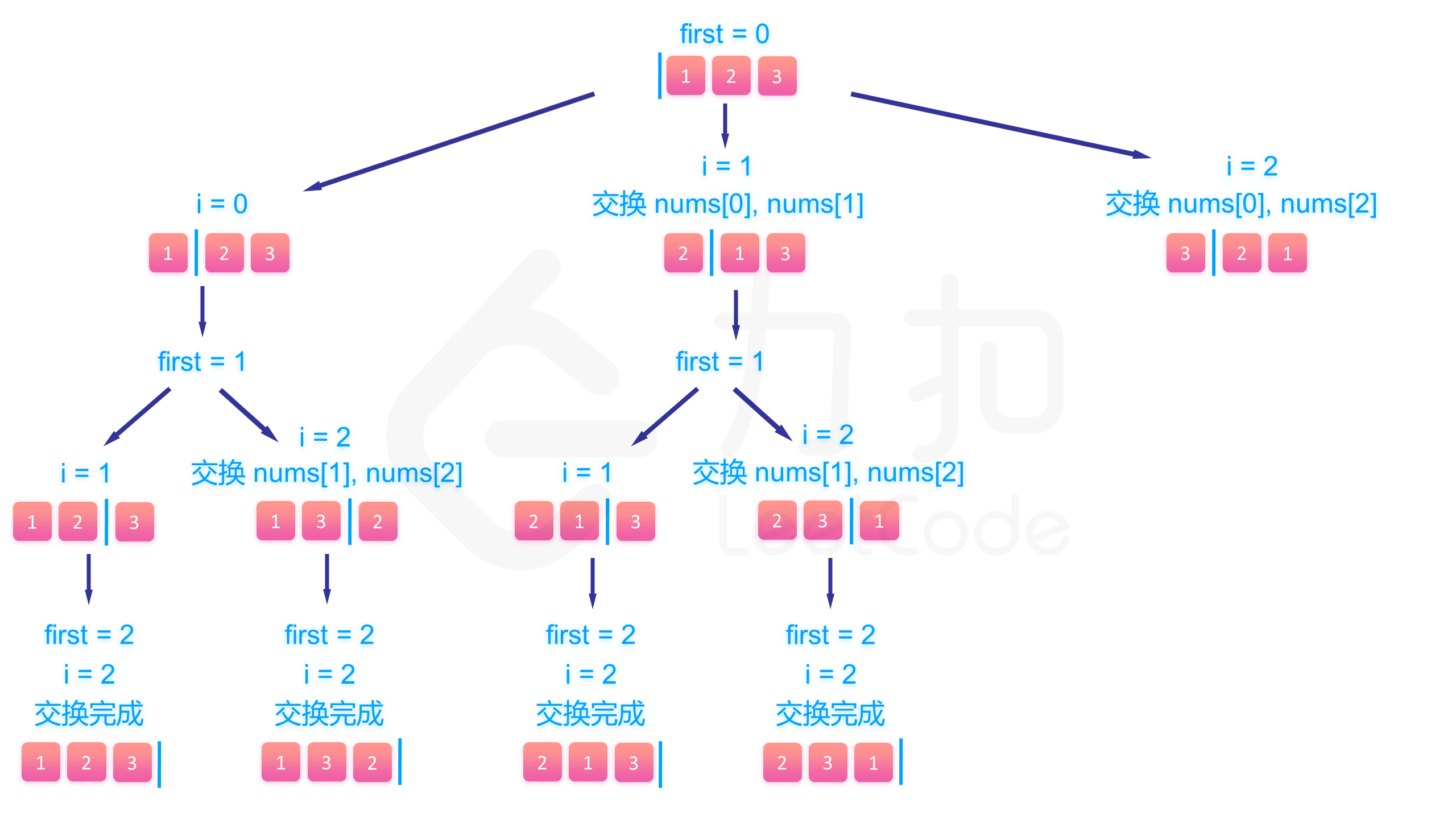
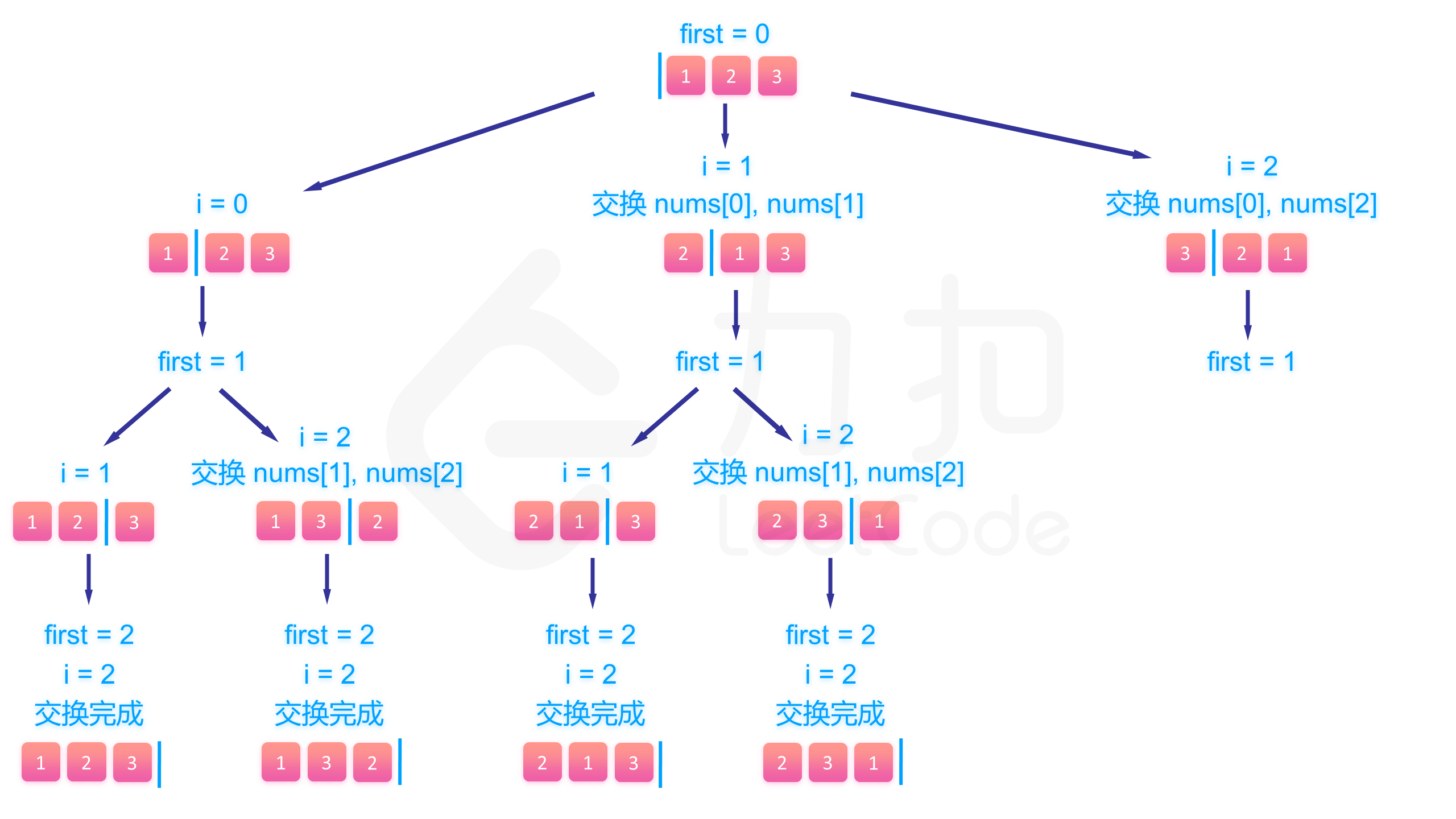
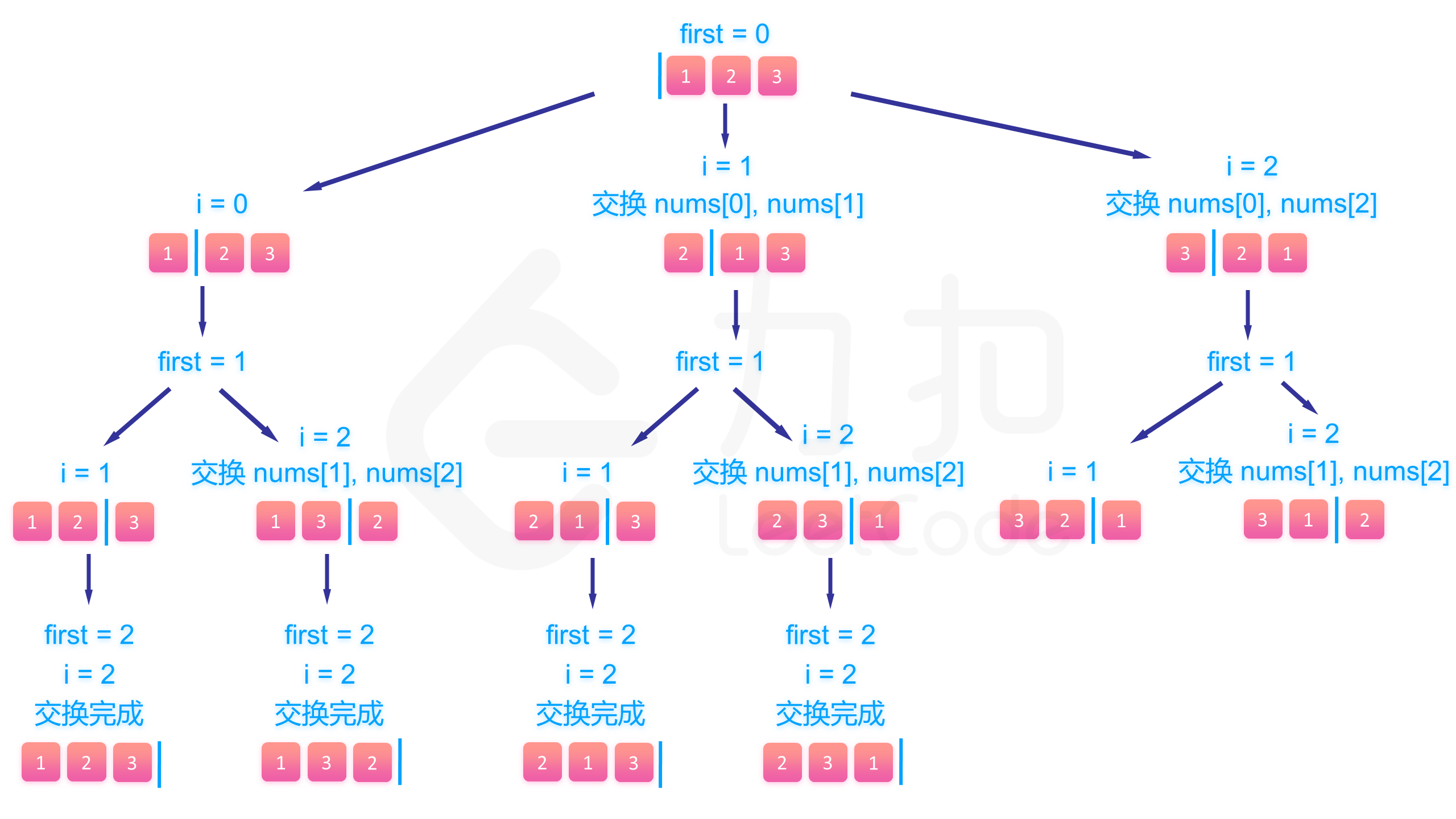
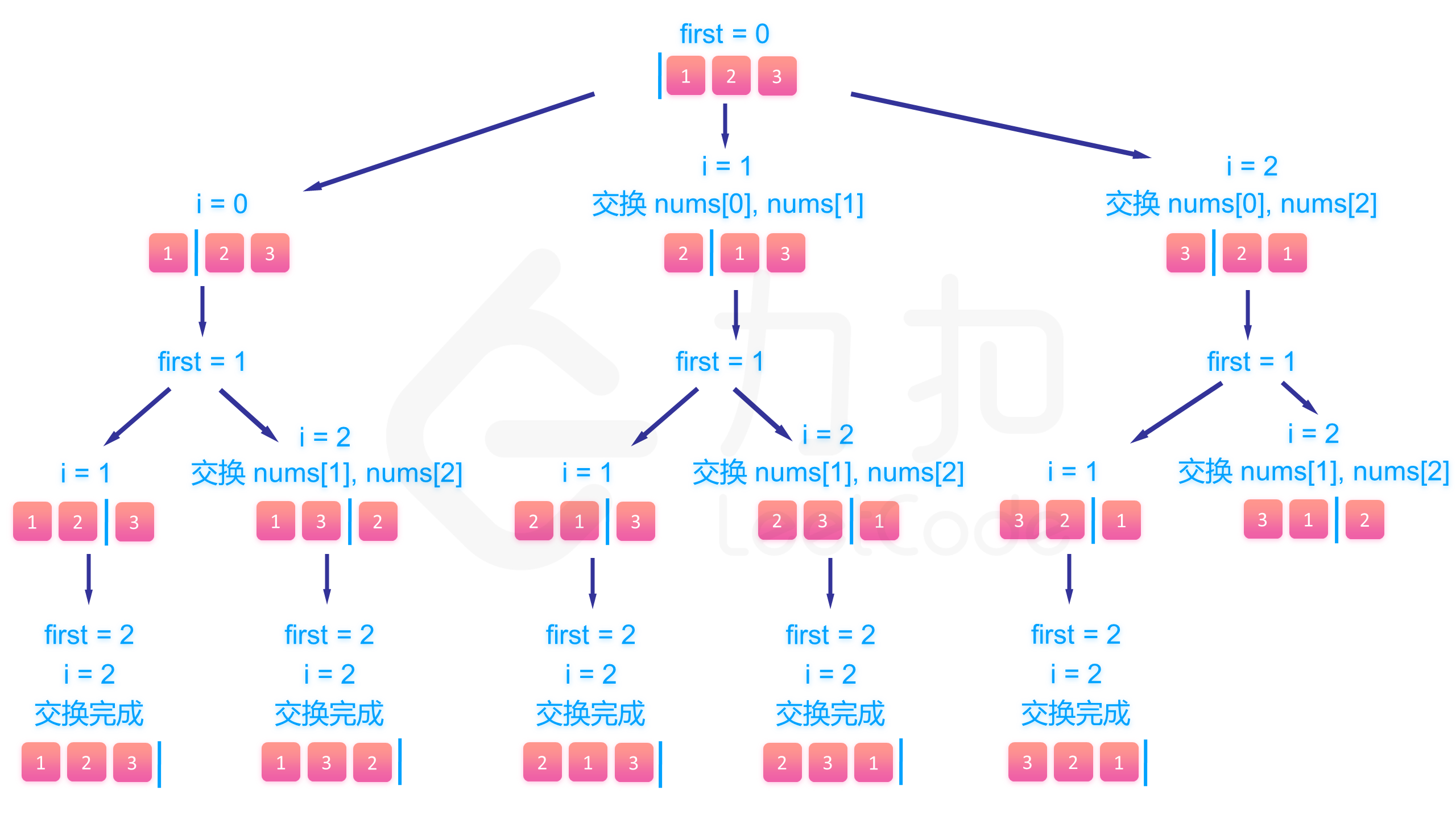
class Solution {
public void backtrack(int n,
ArrayList<Integer> output,
List<List<Integer>> res,
int first) {
// 所有数都填完了
if (first == n)
res.add(new ArrayList<Integer>(output));
for (int i = first; i < n; i++) {
// 动态维护数组
Collections.swap(output, first, i);
// 继续递归填下一个数
backtrack(n, output, res, first + 1);
// 撤销操作
Collections.swap(output, first, i);
}
}
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> res = new LinkedList();
ArrayList<Integer> output = <span class="hljs-keyword">new</span> ArrayList<Integer>();
<span class="hljs-keyword">for</span> (<span class="hljs-keyword">int</span> num : nums)
output.add(num);
<span class="hljs-keyword">int</span> n = nums.length;
backtrack(n, output, res, <span class="hljs-number">0</span>);
<span class="hljs-keyword">return</span> res;
}
}
class Solution:
def permute(self, nums):
"""
:type nums: List[int]
:rtype: List[List[int]]
"""
def backtrack(first = 0):
# 所有数都填完了
if first == n:
res.append(nums[:])
for i in range(first, n):
# 动态维护数组
nums[first], nums[i] = nums[i], nums[first]
# 继续递归填下一个数
backtrack(first + 1)
# 撤销操作
nums[first], nums[i] = nums[i], nums[first]
n = len(nums)
res = []
backtrack()
<span class="hljs-keyword">return</span> res
class Solution {
public:
void backtrack(vector<vector<int>>& res, vector<int>& output, int first, int len){
// 所有数都填完了
if (first == len) {
res.emplace_back(output);
return;
}
for (int i = first; i < len; ++i) {
// 动态维护数组
swap(output[i], output[first]);
// 继续递归填下一个数
backtrack(res, output, first + 1, len);
// 撤销操作
swap(output[i], output[first]);
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<vector<int> > res;
backtrack(res, nums, 0, (int)nums.size());
return res;
}
};
复杂度分析
- 时间复杂度:,其中 为序列的长度。
算法的复杂度首先受 backtrack 的调用次数制约,backtrack 的调用次数为 次,其中 ,该式被称作 n 的 k - 排列,或者部分排列。
而
这说明 backtrack 的调用次数是 的。
而对于 backtrack 调用的每个叶结点(共 个),我们需要将当前答案使用 的时间复制到答案数组中,相乘得时间复杂度为 。
因此时间复杂度为 。
- 空间复杂度:,其中 为序列的长度。除答案数组以外,递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,这里可知递归调用深度为 。
