源代码、目标代码、可执行代码、本地代码的区别
Source Code 源代码
源代码,顾名思义,是由程序员编写的原始文件。如果你想知道源代码的定义,上述描述已经足够了,但下面的描述会更好的帮助你理解这个主题。
源代码指的是由程序员编写的文本文件。程序员为了执行某些任务以人类可读的语言编写这些代码,绝大部分都是英文。然后以某种特定的格式保存这些文件,像Java语言的.java,C#语言的.cs等等。这些文件可以是按照某种特定语言的惯例和规则编写的,而这种语言可以是程序员选择的任何高级语言,并相应的被保存为正确的扩展名。这些源码对人类来说是可读的,但机器不能直接理解这种以英文或者其他人类语言指定的指令。所以这些代码对机器是没有用的,只有将其编译成机器可执行的代码。
源代码作为这种语言的编译器的输入。
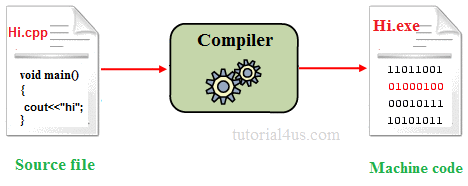
Object Code 目标代码
目标代码是机器可执行的的文件,其中包含了编译器产生的二进制形式的机器指令。
这种定义是不言自明的,但加上如下解释可能会更好理解。
首先,目标代码是编译器的输出,是二进制文件,包含了程序员在源码中指定的指令。这些指令会以二进制的形式进行编码,目标代码是机器可读的,或者说是机器可执行的,但对于人类来说不可读,除非你是二进制形式的代码的专家。
目标代码是由成为编译的过程产生的,这个过程是由编译器执行的,将源代码转换成机器可执行的代码。
目标代码是基于某种特定的系统体系的。由一种机器上的编译器编译出来的文件可能不能在另一种不同体系的机器上执行。尽管,这个问题已经由“中间代码”和“即时编译器”解决,但仍然有许多语言,像Java,遵循目标代码生成的传统方式。
关于目标代码的最后一点是反映更改的。修改源码后,每次需要编译源代码以反映目标代码中的更改。
下面是两种类型代码的总结。
| Source Code | Object Code |
| 程序员编写 | 编译器产生 |
| 文本丰富的文档 | 二进制数字组成目标代码 |
| 人类可读 | 机器可读 |
| 可以随时间改变 | 每次改变都要进行编译 |
| 不是系统特定的 | 系统特定 |
| 用作编译器的输入 | 编译器的输出 |
| 使用英文单词并根据语言语法编写的指令 | 二进制形式的指令 |
以上部分翻译自: https://www.thecrazyprogrammer.com/2018/05/source-code-and-object-code.html
可执行代码
由编译程序生成的目标代码并不能立即执行,其中还有许多没有解决的问题。例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要链接程序的处理方能得以解决。
链接程序
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
根据开发人员指定的同库函数的连接方式的不同,链接处理可分为两种:
(1)静态链接
在这种链接方式下,函数的代码将从其所在静态链接库中被拷贝到最终的可执行程序中。这样该程序在执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或一组相关函数的代码。即是说,静态链接将链接库的代码复制到可执行程序中,使得可执行程序的体积变大。
(2)动态链接
在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其他少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间中。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。即是说,动态链接指的是需要链接的代码放到一个共享对象中,共享对象映射到进程虚地址空间,链接程序记录可执行程序将来需要用的代码信息,根据这些信息迅速定位相应的代码片段。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比静态链接要优越。在某些情况下动态链接可能带来一些性能上的损害。
以上部分来自: https://blog.csdn.net/yxc135/article/details/7564060
Native Method 本地方法
Java方法是Java语言编写的,编译成字节码,存储在class文件中。本地方法是由其他语言编写的,编译程和处理器相关的机器代码。本地方法保存在动态链接库中。即.dll(windos)文件中,格式是各个平台专有的。Java方法是与平台无关的,但本地方法不是。
(1)什么是本地方法
一个Native Method就是一个java方法调用非java代码的接口。一个Native Method是这样一个java的方法:该方法的实现由非java语言实现,比如C。这个特征非java所特有,很多其他的编程语言都有这一机制。
在定义一个native method时,并不提供实现体,因为其实现体是由非java语言在外面实现的。例如:
pubic class IHaveNatives {
native public void Native1(int x);
native static public long Native2();
native synchronized private float Native3(Object o);
native void Native4(int[] array) throws Exception;
}
标识符native可以与所有其他的java标识符连用,但是abstract除外。这是合理的,因为native暗示这些方法是有实现体的,只不过这些实现体是非java的,但是abstract却显然的指明这些方法无实现体.
一个native method可以返回任何java类型,包括非基本类型,而且同样可以进行异常控制。native method的存在并不会对其他类调用这些本地方法产生任何影响,实际上调用这些方法的其他类甚至不知道它所调用的是一个本地方法。本地方法非常有用,因为它有效地扩充了jvm.事实上,我们所写地java代码已经用到了本地方法,在sun的java的并发(多线程)的机制实现中,许多与操作系统的接触点都用到了本地方法。这使得java程序能够超越java运行时的界限。有了本地方法,java程序可以在做任何应用层次的任务。
(2)为什么要用Native Method
java使用起来非常方便,然而有些层次的任务用java实现起来不容易,或者我们对程序的效率很在意时,问题就来了。
与java环境外交互:
有时java应用需要与java外面的环境交互。这是本地方法存在的主要原因,你可以想想java需要与一些底层系统如操作系统或某些硬件交换信息时的情况。本地方法正是这样一种交流机制:它为我们提供了一个非常简洁的接口,而且我们无需去了解java应用之外的繁琐细节。
与操作系统交互:
JVM支持着java语言本身和运行时库,它是java程序赖以生存的平台,它由一个解释器(解释字节码)和一些连接到本地代码的库组成。然而不管怎样,它毕竟不是一个完成的系统,它经常依赖于一些底层系统的支持。这些底层系统常常是非常强大的操作系统。通过使用本地方法,我们得以用java实现了jre的与底层系统的交互,甚至jvm的一些部分就是用C写的,还有,如果我们要使用一些java语言本身没有提供封装的操作系统的特性时,我们也需要使用本地方法。
Sun's Java
Sun的解释器是用C实现的,这使得它能像一些普通的C一样与外部交互。jre大部分是用java实现的,它也通过一些本地方法与外界交互。例如:类java.lang.Thread的setPriority()方法是用java实现的,但是它实现调用的是该类里的本地方法setPriority0()。这个方法是用C实现的,并被植入JVM内部,外Windows 95 平台上,这个本地方法最终调用Win32 SetPriority() API。这是一个本地方法的具体实现由JVM直接提供,更多的情况是本地方法由外部的动态链接库(external dynamic link library)提供。然后被JVM调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号