一文聊透Apache Hudi的索引设计与应用
Hudi索引在数据读和写的过程中都有应用。读的过程主要是查询引擎利用MetaDataTable使用索引进行Data Skipping以提高查找速度;写的过程主要应用在upsert写上,即利用索引查找该纪录是新增(I)还是更新(U),以提高写入过程中纪录的打标(tag)速度。
MetaDataTable
目前使能了"hoodie.metadata.enable"后,会在.hoodie目录下生成一张名为metadata的mor表,利用该表可以显著提升源表的读写性能。
该表目前包含三个分区:files, column_stats, bloom_filters,分区下文件的格式为hfile,采用该格式的目的主要是为了提高metadata表的点查能力。
其中files分区纪录了源表各个分区内的所有文件列表,这样hudi在生成源表的文件系统视图时就不必再依赖文件系统的list files操作(在云存储场景list files操作更有可能是性能瓶颈);TimeLine Server和上述设计类似,也是通过时间线服务器来避免对提交元数据进行list以生成hudi active timeline。
其中column_stats分区纪录了源表中各个分区内所有文件的统计信息,主要是每个文件中各个列的最大值,最小值,纪录数据,空值数量等。只有在开启了"hoodie.metadata.index.column.stats.enable"参数后才会使能column_stats分区,默认源表中所有列的统计信息都会纪录,也可以通过"hoodie.metadata.index.column.stats.column.list"参数单独设置。Hudi表每次提交时都会更新column_stats分区内各文件统计信息(这部分统计信息在提交前的文件写入阶段便已经统计好)。
其中bloom_filters分区纪录了源表中各个分区内所有文件的bloom_filter信息,只有在开启了"hoodie.metadata.index.bloom.filter.enable"参数后才会使能bloom_filters分区,默认纪录源表中record key的bloomfilter, 也可以通过"hoodie.metadata.index.bloom.filter.column.list"参数单独设置。
需要注意bloom_filter信息不仅仅存储在metadata表中(存在该表中是为了读取加速,减少从各个base文件中提取bloomfilter的IO开销)。Hudi表在开启了"hoodie.populate.meta.fields"参数后(默认开启),在完成一个parquet文件写入时,会在parquet文件的footerMetadata中填充bloomfilter相关参数, 其中"hoodie_bloom_filter_type_code"参数为过滤器类型,设置为默认的DYNAMIC_V0(可根据record key数量动态扩容);"org.apache.hudi.bloomfilter"参数为过滤器bitmap序列化结果;"hoodie_min_record_key"参数为当前文件record_key最小值;"hoodie_max_record_key"参数为当前文件record_key最大值。Hudi表提交时其Metadata表bloom_filters分区内的bloom_filter信息便提取自parquet文件footerMetadata的"org.apache.hudi.bloomfilter".
写入
Flink
对flink写入而言就是通过bucket_idx进行打标(仅支持分区内去重打标)或者bucket_assigner算子使用flink state进行打标(支持分区内以及全局去重打标,可通过参数控制,如果要进行全局去重需要使能index.global.enabled且不使能changelog.enabled),目前flink仅支持这两种方式,具体可参考hoodieStreamWrite方法。
对于upsert写入场景,flink state会随着写入数据量的增大而线性增大,导致越写越慢(打标过程变慢)的现象;而bucket_idx由于没有数据查找过程(通过纪录的record key直接哈希得到对应的filegroup进行打标),因此写入速度不会随数据量增大而线性增大。
如果应用场景需要对分区表进行全局去重,则只能使用flink state。如果上层业务允许,我们也可以通过变更表结构,将分区键加入到主键中作为主键的一部分来实现分区间的天然去重。
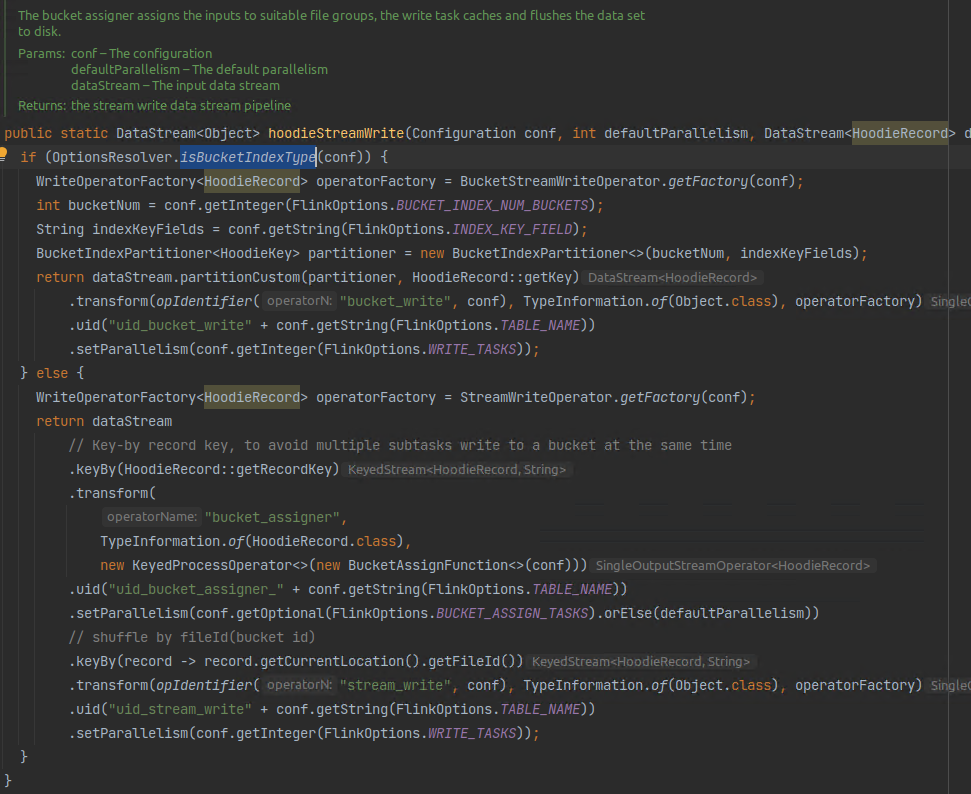
图2. 1 flink写入打标过程
对于metadata表而言,flink可以通过使能参数"hoodie.metadata.index.column.stats.enable"生成column_stats,flink可以在读优化查询时使用到列统计信息进行data skipping。
对于metadata表而言,flink可以通过使能参数"hoodie.metadata.index.bloom.filter.enable"生成bloom_filters,但是flink
目前不支持在读时使用bloomfilter进行data skipping,也不支持在写时通过bloomfilter进行打标。
Spark
对spark写入而言就是对每条纪录调用index.tagLocation进行打标的过程。Spark目前支持SimpleIndex, GlobalSimpleIndex, BloomIndex, BucketIndex, HbaseIndex进行写入打标。
SimpleIndex通过在每个分区内进行InputRecordRdd left outer join ExistingRecordRdd的方式判断输入纪录是否已经存储在当前分区内;GlobalSimpleIndex和SimpleIndex类似,只不过left outer join该表内所有已存在数据而不是当前分区已存在数据。
BloomIndex通过column_stat_idx和bloom_filter_idx进行数据打标过滤:首先通过column_stat_idx(可以从metadata表中获取,也可从parquet footer metadata中获取,通过"hoodie.bloom.index.use.metadata"参数控制)的min,max值过滤掉纪录肯定不存在的文件(在record key递增且数据经过clustering的情况下可以过滤出大量文件)以获得纪录可能存在的文件。然后在纪录可能存在的文件中依次使用每个文件对应的bloomfilter(可以从metadata表中获取,也可从parquet footer metadata中获取,通过"hoodie.bloom.index.use.metadata"参数控制)判断该纪录是否一定不存在。最后得到每个文件可能包含的纪录列表,由于bloomfilter的误判特性,需要将这些纪录在文件中进行精准匹配查找以得到实际需要更新的纪录及其对应的location.
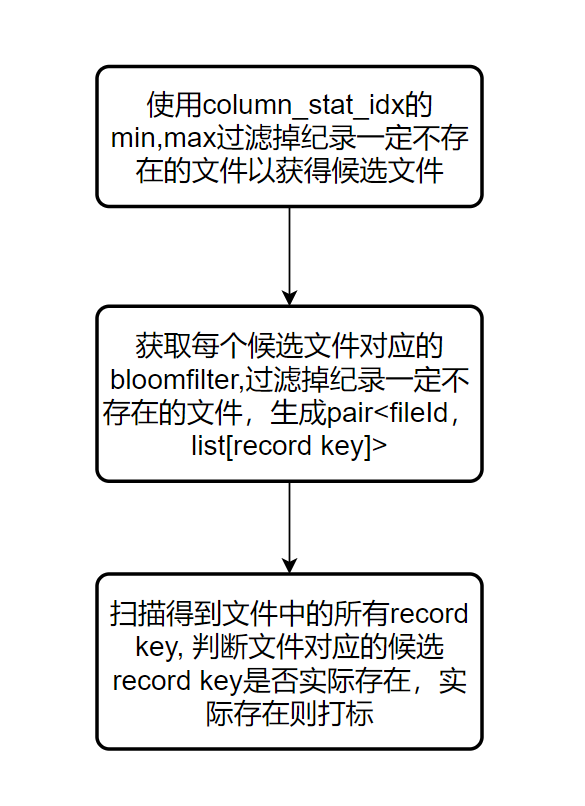
图2. 2 spark写入使用BloomIndex打标过程
BucketIndex和flink的bucket打标类似,通过hash(record_key) mod bucket_num的方式得到纪录实际应该插入的文件位置,如果该文件不存在则为插入,存在则为更新。
HbaseIndex通过外部hbase服务存储record key,因此打标过程需要和hbase服务进行交互,由于使用hbase存储,因此该索引天然是全局的。
读取
Flink
flink读取目前支持使用column_stats进行data skipping.建表时需要使能"metadata.enabled","hoodie.metadata.index.column.stats.enable","read.data.skipping.enabled",这三个参数。
Spark
spark读取目前支持使用column_stats进行data skipping.建表时需要使能" hoodie.metadata.enabled","hoodie.metadata.index.column.stats.enable","read.data.skipping.enabled",这三个参数。
总结
写入打标:
| column_stat_idx | bloom_filter_idx | bucket_idx | flink_state | Simple | Hbase_idx | |
|---|---|---|---|---|---|---|
| Spark | Y | Y | Y | N flink only | Y | Y |
| Flink | N | N | Y | Y | N spark only | N |
MetaDataTable表索引分区构建:
| file_idx | column_stat_idx | bloom_filter_idx | |
|---|---|---|---|
| Spark | Y | Y | Y |
| Flink | Y | Y | Y |
读取data skipping:
| column_stat_idx | bloom_filter_idx | bucket_idx | |
|---|---|---|---|
| Spark | Y | N | N |
| Flink | Y | N | N |
社区进展/规划
Column Stats Index
RFC-27 Data skipping(column_stats) index to improve query performance
状态:COMPLETED
简述:列统计索引的rfc设计
原理:列统计索引存储在metadata table中,使用hfile存储索引数据

图5. 1 hfile layout
HFile最大的优势是数据按照key进行了排序,因此点查速度很快。
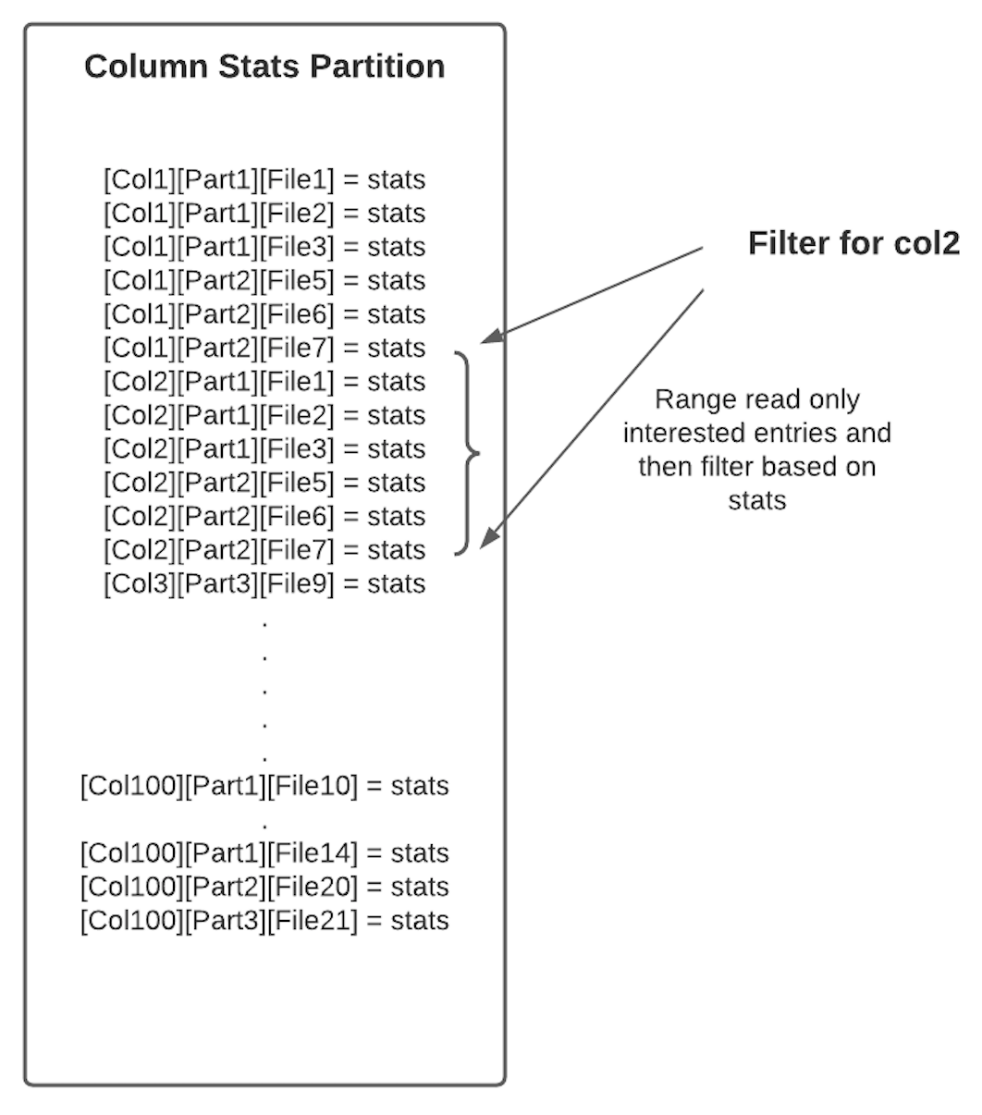
图5. 2 column stats index storage format
由于HFile的前缀搜索速度很快,因此上述布局(一个列的统计信息在相邻的data block中)可以快速拿到一个列在各个文件中的统计信息。
https://github.com/apache/hudi/blob/master/rfc/rfc-27/rfc-27.md
RFC-58 Integrate column stats index with all query engines
状态:UNDER REVIEW
简述:集成列统计索引到presto/trino/hive
原理:基于RFC-27 metadata table中的column_stats index来实现上述引擎的data skipping,当前有两种可能的实现:基于列域(column domain, 域是一个列可能包含值的一个集合)的实现和基于hudiExpression的实现。

图5. 3 HudiExpression sketch
https://github.com/apache/hudi/pull/6345
Bucket Index
RFC-29 Hash(bucket) Index
状态:COMPLETED
简述:bucket index的rfc设计
原理:对主键做hash后取桶个数的模(hash(pk) mod bucket_num), 即数据在写入时就按照主键进行了clustering,后续upsert可以直接通过hash找到对应的桶。

图5. 4 hash process
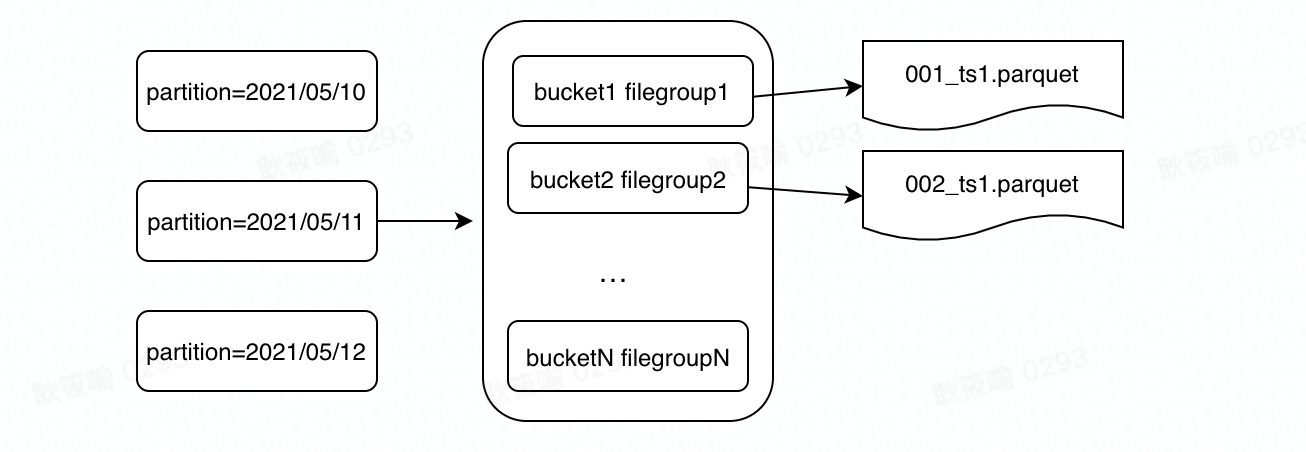
图5. 5 bucket-filegroup mapping
目前一个桶和一个filegroup一一对应,数据文件的前缀会加上bucketId。
https://cwiki.apache.org/confluence/display/HUDI/RFC+-+29%3A+Hash+Index
RFC-42 Consistent hashing index for dynamic bucket numbers
状态:ONGOING
简述:bucket index一致性哈希实现的rfc设计
原理:RFC-29实现的bucket index不支持动态修改桶个数,由此导致数据倾斜和一个file group size过大,采用一致性哈希可以在不改变大多数桶的情况下完成桶的分裂/合并,以尽可能小的减小动态调整桶数量时对读写的影响。
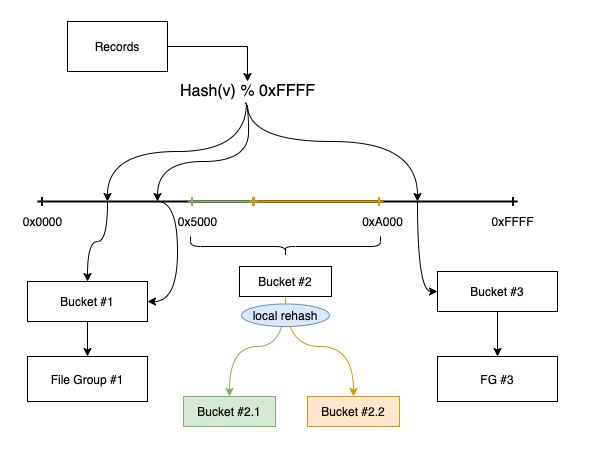
图5. 6 一致性哈希算法
通过Hash(v) % 0xFFFF得到一个范围hash值,然后通过一个range mapping layer将哈希值和桶关联起来,可以看到如果bucket#2过大,可以将其对应的范围0x5000-0xA000进行split分成两个桶,仅需要在这个范围内进行重新分桶/文件重写即可。
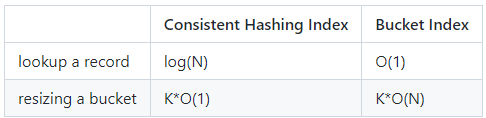
图5. 7 算法复杂度对比
https://github.com/apache/hudi/blob/master/rfc/rfc-42/rfc-42.md
https://github.com/apache/hudi/pull/4958
https://github.com/apache/hudi/pull/6737
Bloom Index
RFC-37 Metadata based Bloom Index
状态:COMPLETED
简述:bloom index的rfc设计
原理:将base文件内的bloom filter提取到metadata table中以减少IO,提升查找速度
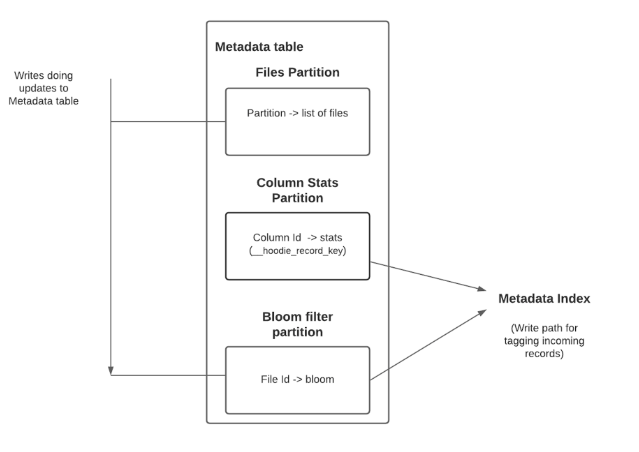
图5. 8 bloom filter location in metadata table
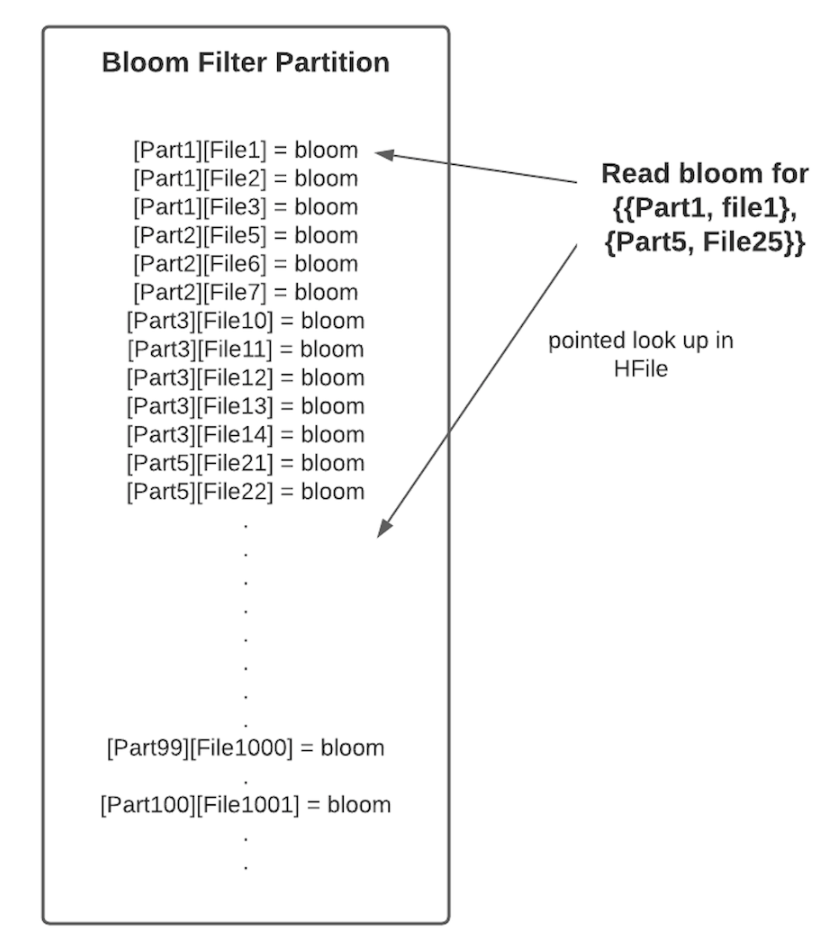
图5. 9 bloom index storage format
Key的生成方式为:
key = base64_encode(concat(hash64(partition name), hash128(file name)))
因此一个分区内的文件天然的在HFile的相邻data block中,采用base64编码可以减少key的磁盘存储空间。
https://github.com/apache/hudi/blob/master/rfc/rfc-37/rfc-37.md
Record-level Index
RFC-08 Record-level index to speed up UUID-based upserts and deletes
状态:ONGOING
简述:记录级(主键)索引的rfc设计
原理:为每条记录生成recordKey <-> partition, fileId的映射索引,以加速upsert的打标过程。
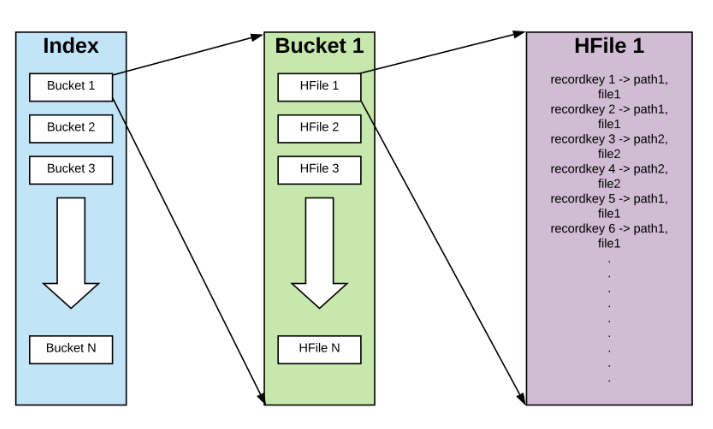
图5. 10 行级索引实现
每条记录被哈希到对应的bucket中,每一个bucket中包含多个HFile文件,每个HFile文件的data block中包含recordKey <-> partition, fileId的映射。
https://issues.apache.org/jira/browse/HUDI-53
https://github.com/apache/hudi/pull/5581
Secondary Index
RFC-52 Secondary index to improve query performance
状态:UNDER REVIEW
简述:二级(非主键/辅助)索引的rfc设计
原理:二级索引可以精确匹配数据行(记录级别索引只能定位到fileGroup),即提供一个column value -> row 的映射,如果查询谓词包含二级索引列就可以根据上述映射关系快速定位目标行。

图5. 11 二级索引架构
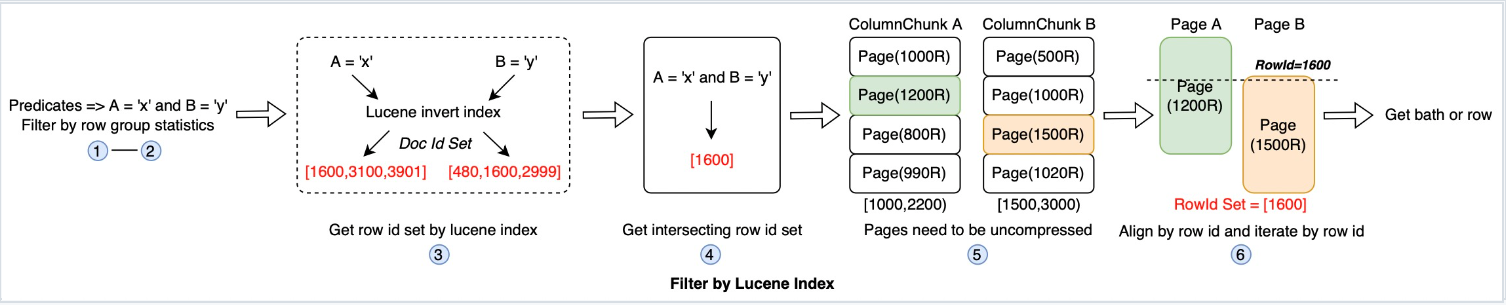
图5. 12 使用Lucene index进行谓词过滤
如上图所示:先通过row group统计信息进行首次过滤以加载指定page页,然后通过lucene索引文件(倒排索引,key为列值,value为row id集合)过滤出指定的行(以row id标识),合并各谓词的row id,加载各个列的page页并进行row id对齐,取出目标行。Lucene index只是二级索引框架下的一种可能实现。
https://github.com/apache/hudi/pull/5370
Function Index
RFC-63 Index on Function
状态:UNDER REVIEW
简述:函数索引的rfc设计
原理:通过sql或者hudi配置定义一个在某列上的函数作为函数索引,将其记录到表属性中,在数据写入时索引函数可以作为排序域,由此每个数据文件对应于索引函数值都有一个较小的min-max以进行有效的文件过滤,同时metadata table中也会维护文件级别的索引函数值对应的列统计信息。数据文件中不会新增索引函数值对应的列。

图5. 13 带timestamp的hudi表
如上图所示,一个场景需要过滤出每天1点到2点的数据,由于把timestamp直接转成小时将不会保序,就没法直接使用timestamp的min,max进行文件过滤,如果我们对timestamp列做一个HOUR(timestamp)的函数索引,然后将每个文件对应的函数索引min,max值记录到metadata table中,就可以快速的使用上述索引值进行文件过滤。
https://github.com/apache/hudi/pull/5370
Support data skipping for MOR
Hudi当前还不支持针对MOR表中log文件的索引,社区目前正在讨论中:
https://issues.apache.org/jira/browse/HUDI-3866
https://cwiki.apache.org/confluence/display/HUDI/RFC+-+06+%3A+Add+indexing+support+to+the+log+file
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号