Apache Hudi vs Delta Lake:透明TPC-DS Lakehouse性能基准
1. 介绍
最近几周,人们对比较 Hudi、Delta 和 Iceberg 的表现越来越感兴趣。 我们认为社区应该得到更透明和可重复的分析。 我们想就如何执行和呈现这些基准、它们带来什么价值以及我们应该如何解释它们添加我们的观点。
2. 现有方法存在哪些问题?
最近 Databeans 发布了一篇博客,其中使用 TPC-DS 基准对 Hudi/Delta/Iceberg 的性能进行了正面比较。虽然很高兴看到社区挺身而出并采取行动提高对行业当前技术水平的认识,但我们发现了一些与实验进行方式和结果报告有关的问题,我们希望分享和今天更广泛地讨论。
作为一个社区,我们应该努力在发布基准时增加更严格的标准。我们相信这些是任何基准测试工作的关键原则:
- 可重现性:如果结果不可重现,读者别无选择,只能盲目相信表面上的结果。相反,应该记录基准,以便任何人都可以使用相同的工具获得相同的结果。
- 开放:为了获得相同的结果,确保用于基准测试的工具可用于检查正确性至关重要。
- 公平:随着正在测试的技术的复杂性不断增长,基准设置需要确保所有竞争者都使用记录在案的配置来测试工作负载。
关于这些基本问题,不幸的是,我们认为 Databeans 博客没有完整地分享结果是什么以及如何实现的。例如:
-
基准 EMR 运行时配置未完全披露:尚不清楚,例如Spark 的动态分配功能是否被禁用,因为它有可能对测量产生不可预测的影响。
-
用于基准测试的代码是 Delta 基准测试框架的扩展,不幸的是它也没有公开共享,因此无法查看或重复相同的实验。
-
无法访问代码也会影响分析应用于 Hudi/Delta/Iceberg 的配置的能力,这使得评估公平性具有挑战性
3. 我们建议如何运行基准测试
我们会定期运行性能基准测试,以确保一起提供Hudi 丰富的功能集与基于 Hudi 的 EB 数据湖的最佳性能。我们的团队在对复杂分布式系统(如 Apache Kafka 或 Pulsar)进行基准测试方面拥有丰富的经验,符合上述原则。
为确保已发布的基准符合以下原则:
- 我们关闭了 Spark 的动态分配功能,以确保我们在稳定的环境中运行基准测试,并消除 Spark 集群决定扩大或缩小规模时结果中的任何抖动。 我们使用 EMR 6.6.0 版本,Spark 3.2.0 和 Hive 3.1.2(用于 HMS),具有以下配置(在创建时在 Spark EMR UI 中指定)有关如何设置 HMS 的更多详细信息,请按照说明进行操作 在README文件中
[{
"Classification": "spark-defaults",
"Properties": {
"spark.dynamicAllocation.enabled": "false"
}
}, {
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "true"
}
}, {
"Classification": "hive-site",
"Properties": {
"javax.jdo.option.ConnectionURL": < hive_metastore_url > ,
"javax.jdo.option.ConnectionDriverName": "org.mariadb.jdbc.Driver",
"javax.jdo.option.ConnectionUserName": < username > ,
"javax.jdo.option.ConnectionPassword": < password >
}
}]
- 我们已经公开分享了我们对 Delta 基准测试框架的修改,以支持通过 Spark Datasource 或 Spark SQL 创建 Hudi 表。 这可以在基准定义中动态切换。
- TPC-DS 加载不涉及更新。 Hudi 加载的 databeans 配置使用了不适当的写入操作
upsert,而明确记录了 Hudibulk-insert是此用例的推荐写入操作。 此外,我们调整了 Hudi parquet 文件大小设置以匹配 Delta Lake 默认值。
CREATE TABLE ...
USING HUDI
OPTIONS (
type = 'cow',
primaryKey = '...',
precombineField = '',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
-- Disable Hudi’s record-level metadata for updates, incremental processing, etc
'hoodie.populate.meta.fields' = 'false',
-- Use “bulk-insert” write-operation instead of default “upsert”
'hoodie.sql.insert.mode' = 'non-strict',
'hoodie.sql.bulk.insert.enable' = 'true',
-- Perform bulk-insert w/o sorting or automatic file-sizing
'hoodie.bulkinsert.sort.mode' = 'NONE',
-- Increasing the file-size to match Delta’s setting
'hoodie.parquet.max.file.size' = '141557760',
'hoodie.parquet.block.size' = '141557760',
'hoodie.parquet.compression.codec' = 'snappy',
– All TPC-DS tables are actually relatively small and don’t require the use of MT table (S3 file-listing is sufficient)
'hoodie.metadata.enable' = 'false',
'hoodie.parquet.writelegacyformat.enabled' = 'false'
)
LOCATION '...'
Hudi 的起源植根于增量数据处理,以将所有老式批处理作业变成增量。 因此,Hudi 的默认配置面向增量更新插入和为增量 ETL 管道生成更改流,而将初始负载视为罕见的一次性操作。 因此需要更加注意加载时间才能与 Delta 相媲美。
4. 运行基准测试
4.1 加载


可以清楚地看到,Delta 和 Hudi 在 0.11.1 版本中的误差在 6% 以内,在当前 Hudi 的 master* 中误差在 5% 以内(我们还对 Hudi 的 master 分支进行了基准测试,因为我们最近在 Parquet 编码配置中发现了一个错误 已及时解决)。
为 Hudi 在原始 Parquet 表之上提供的丰富功能集提供支持,例如:
还有更多,Hudi 在内部存储了一组额外的元数据以及每条称为元字段的记录。 由于 tpc-ds 主要关注快照查询,在这个特定的实验中,这些字段已被禁用(并且未计算),Hudi 仍然将它们保留为空值,以便在未来打开它们而无需模式演进。 添加五个这样的字段作为空值,虽然开销很低,但仍然不可忽略。
4.2 查询
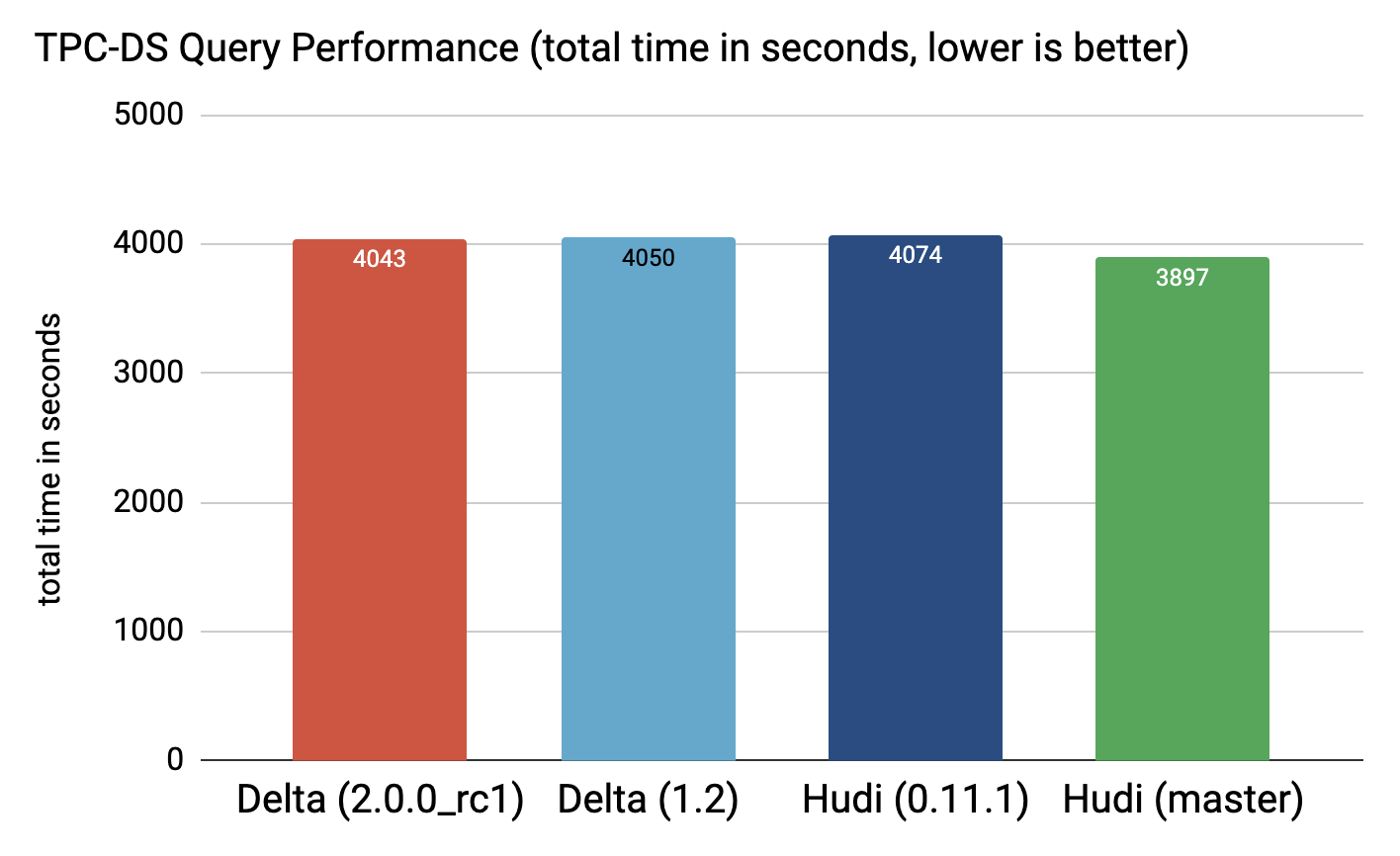
正如我们所见,Hudi 0.11.1 和 Delta 1.2.0 的性能几乎没有区别,而且 Hudi 目前的 master 速度要快一些(~5%)。
您可以在 Google Drive 上的此目录中找到原始日志:
要重现上述结果,请使用我们在 Delta 基准存储库 中的分支并按照自述文件中的步骤进行操作。
5. 结论
总而言之,我们想强调开放性和可重复性在性能基准测试这样敏感和复杂的领域的重要性。 正如我们反复看到的那样,获得可靠和值得信赖的基准测试结果是乏味且具有挑战性的,需要奉献、勤奋和严谨的支持。
展望未来,我们计划发布更多内部基准测试,突出显示 Hudi 丰富的功能集如何在其他常见行业工作负载中达到无与伦比的性能水平。 敬请关注!
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号