致广大数据湖用户的一封信
随着数据湖概念的流行,涌现了很多关于Apache Hudi的文章,但很多文章在阐述时仅仅将Hudi当做一种表格式,这引发了社区的思考,思考Hudi的愿景到底是什么,并且在Hudi社区发起了讨论重新审视Hudi。
我们更倾向于将Hudi当做一个数据湖平台,包含表格式,还包含支持事务的存储层。并重新设计了Hudi的生态设计图
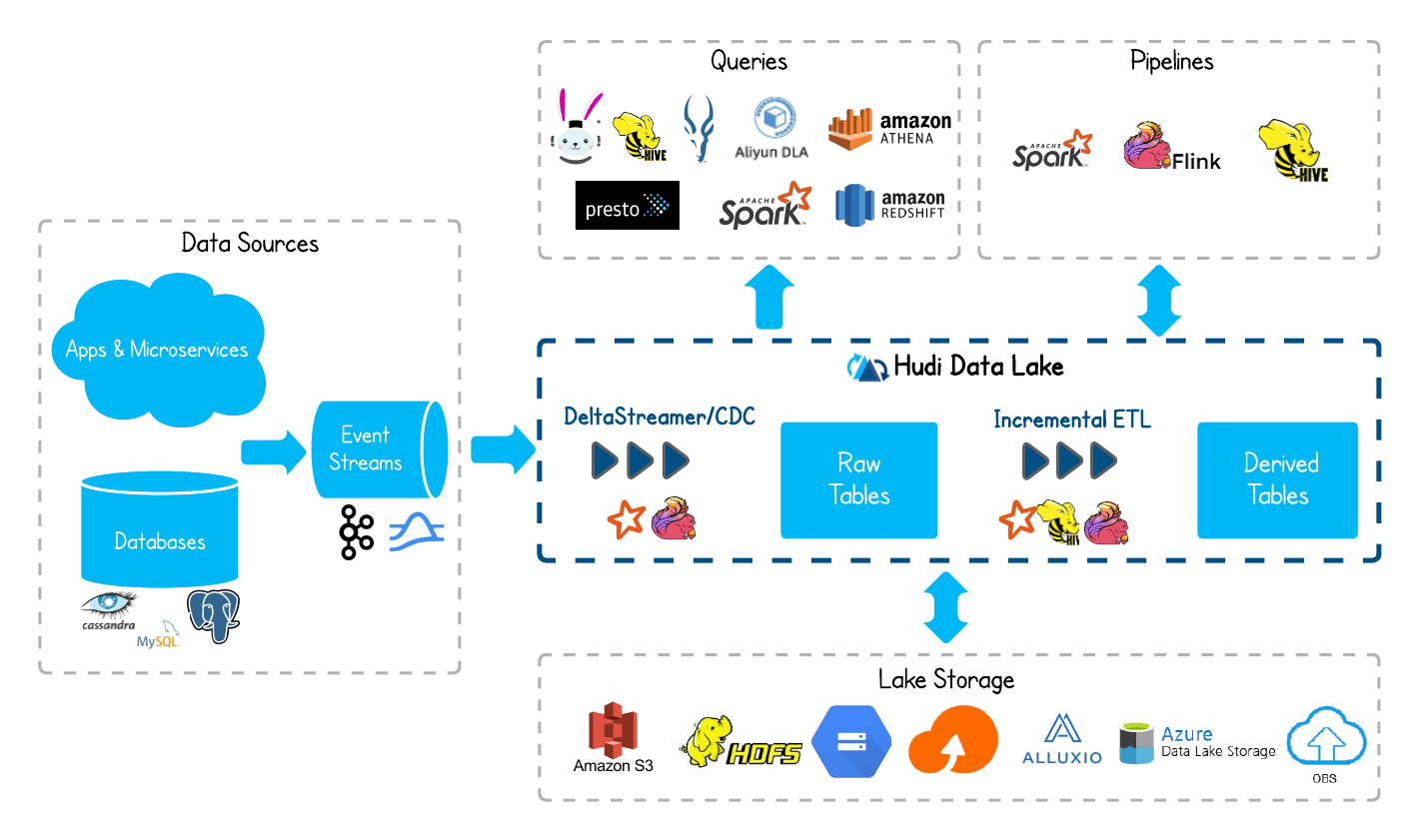
至此Hudi已经提供了如下能力:
- 表格式:存储表Schema;Metadata表,存储文件列表,未来该表还会扩展存储列信息及其他助于写入和查询优化的信息,更多详情请参考 RFC-27 Data skipping index to improve query performance
- 辅助元数据:bloom filters,记录级别索引,bitmap/interval tree和其他更高级的基于硬盘的数据结构。
- 并发控制:支持MVCC(将写入按时间排序序列化至日志中),现在0.8.0版本还支持批处理合并工作负载的OCC乐观并发控制,未来计划多表和完全非阻塞写入,更多详情请参考RFC - 22 : Snapshot Isolation using Optimistic Concurrency Control for multi-writers
- 更新/删除:这是Hudi提供的关键能力,支持主键/唯一键约束,将来支持跨表事务后还可支持外键。
- 表服务:现在Hudi pipeline是自管理的,如文件大小、自动清理、压缩、聚簇数据、冷启动数据。所有的服务绝多数情况都可以独立运行而不阻塞其他服务。
- 数据服务:提供实用工具程序Deltastreamer,提供更高级别的功能,如摄取DFS数据源,Kafka源和即将推出的Pulsar数据源等等),增量ETL支持,重复数据删除,提交回调,即将到来的预提交验证、错误表等。另外还可以朝着流出口、数据监控方向扩展。
我们也可以构建以下内容(视情况而定讨论/RFC)
- 缓存服务:提供Hudi特有的缓存服务,可以保存可变数据并为跨引擎提供查询数据。
- 时间轴元服务器:现在已经在Spark中支持元服务器,可由RocksDB甚至Hudi的元数据表支持,我们可以把它变成一个可扩展、分片的元数据存储服务,所有引擎都可以使用它来获取任何元数据。
为此我建议将我们更名为数据湖平台,而不是“通过DFS(HDFS或云存储)来摄取和管理大型分析数据集的存储和管理”。 并传达我们的愿景,其实我们已经为此做了一些努力,新的愿景也将为新的贡献者提供一个很好的视角来审视该项目。
这与Kafka从Pub-Sub系统演变为流事件平台(加上MirrorMaker / Connect等)非常类似。
具体讨论链接如下:
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号