阿里云AnalyticDB基于Flink CDC+Hudi实现多表全增量入湖实践
湖仓一体(LakeHouse)是大数据领域的重要发展方向,提供了流批一体和湖仓结合的新场景。阿里云AnalyticDB for MySQL基于 Apache Hudi 构建了新一代的湖仓平台,提供日志、CDC等多种数据源一键入湖,在离线计算引擎融合分析等能力。本文将主要介绍AnalyticDB for MySQL基于Apache Hudi实现多表CDC全增量入湖的经验与实践。
1. 背景简介
1.1. 多表CDC入湖背景介绍
客户在使用数据湖、传统数据仓库的过程中,常常会遇到以下业务痛点:
-
全量建仓或直连分析对源库压力较大,需要卸载线上压力规避故障
-
建仓延迟较长(T+1天),需要T+10m的低延迟入湖
-
海量数据在事务库或传统数仓中存储成本高,需要低成本归档
-
传统数据湖存在不支持更新/小文件较多等缺点
-
自建大数据数据平台运维成本高,需要产品化、云原生、一体化的方案
-
常见数仓的存储不开放,需要自建能力、开源可控
-
其他痛点和需求……
针对这些业务痛点,AnalyticDB MySQL 数据管道组件(AnalyticDB Pipeline Service) 基于Apache Hudi 实现了多表CDC全增量入湖,提供入湖和分析过程中高效的全量数据导入,增量数据实时写入、ACID事务和多版本、小文件自动合并优化、元信息校验和自动进化、高效的列式分析格式、高效的索引优化、超大分区表存储等等能力,很好地解决了上述提到的客户痛点。
1.2. Apache Hudi简介
AnalyticDB MySQL选择了Apache Hudi作为CDC入湖以及日志入湖的存储底座。回顾 Hudi 的出现主要针对性解决Uber大数据系统中存在的以下痛点:
-
HDFS的可扩展性限制。大量的小文件会使得HDFS的Name Node压力很大,NameNode节点成为HDFS的瓶颈。
-
HDFS上更快的数据处理。Uber不再满足于T+1的数据延迟。
-
支持Hadoop + Parquet的更新与删除。Uber的数据大多按天分区,旧数据不再修改,T+1 Snapshot读源端的方式不够高效,需要支持更新于删除提高导入效率。
-
更快的ETL和数据建模。原本模式下,下游的数据处理任务也必须全量地读取数据湖的数据,Uber希望提供能力使得下游可以只读取感兴趣的增量数据。
基于以上的设计目标,Uber公司构建了Hudi(Hadoop Upserts Deletes and Incrementals)并将其捐赠给Apache基金会。从名字可以看出,Hudi最初的核心能力是高效的更新删除,以及增量读取Api。Hudi和“数据湖三剑客”中的其他两位(Iceberg,DeltaLake)整体功能和架构类似,都大体由以下三个部分组成:
-
需要存储的原始数据(Data Objects)
-
用于提供upsert功能的索引数据 (Auxiliary Data)
-
以及用于管理数据集的元数据(Metadata)
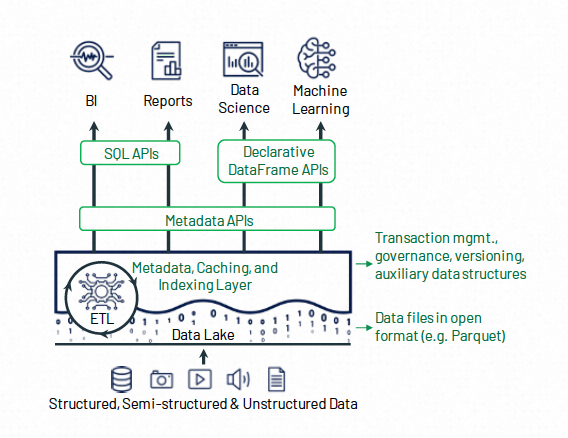
在存储的原始数据层面,Lakehouse一般采用开源的列存格式(Parquet,ORC等),这方面没有太大的差异。 在辅助数据层面,Hudi提供了比较高效的写入索引(Bloomfilter, Bucket Index) ,使得其更加适合CDC大量更新的场景。
1.3. 业界方案简介
阿里云AnalyticDB团队在基于Hudi构建多表CDC入湖之前,也调研了业界的一些实现作为参考,这里简单介绍一下一些业界的解决方案。
1.3.1. Spark/Flink + Hudi 单表入湖
使用Hudi实现单表端到端CDC数据入湖的整体架构如图所示:
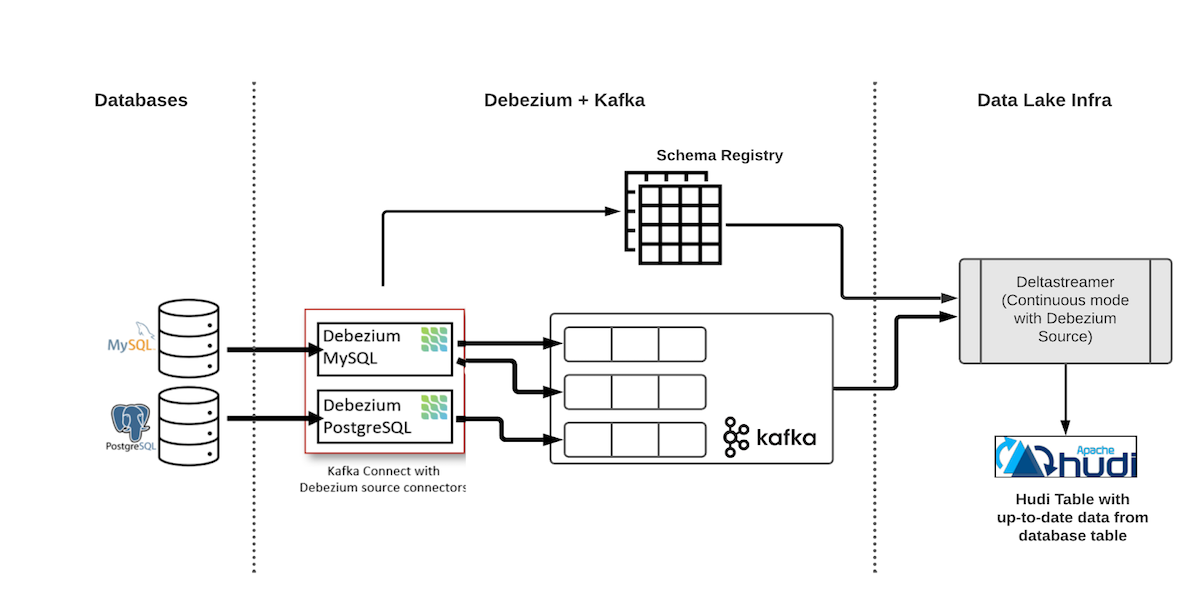
图中的第一个组件是Debezium deployment,它由 Kafka 集群、Schema Registry(Confluence 或 Apicurio)和 Debezium 连接器组成。会源源不断读取数据库的binlog数据并将其写入到Kafka中。
图中的下游则是Hudi的消费端,这里我们选用Hudi提供的DeltaStreamer组件,他可以消费Kafka中的数据并写入到Hudi数据湖中。业界实现类似单表CDC入湖,可以将上述方案中的binlog源从Debezium + Kafka替换成Flink CDC + Kafka等等,入湖使用的计算引擎也可以根据实际情况使用Spark/Flink。
这种方式可以很好地同步CDC的数据,但是存在一个问题就是每一张表都需要创建一个单独的入湖链路,如果想要同步数据库中的多张表,则需要创建多个同步链路。这样的实现存在几个问题:
-
同时存在多条入湖链路提高了运维难度
-
动态增加删除库表比较麻烦
-
对于数据量小/更新不频繁的表,也需要单独创建一条同步链路,造成了资源浪费。
目前,Hudi也支持一条链路多表入湖,但还不够成熟,不足以应用于生产,具体的使用可以参考这篇文档。
1.3.2. Flink VVP 多表入湖
阿里云实时计算Flink版(即Flink VVP) 是一种全托管Serverless的Flink云服务,开箱即用,计费灵活。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。
阿里云Flink产品提供了多表入湖的能力(binlog -> flink cdc -> 下游消费端),支持在一个Flink任务中同时消费多张表的binlog并写入下游消费端:
-
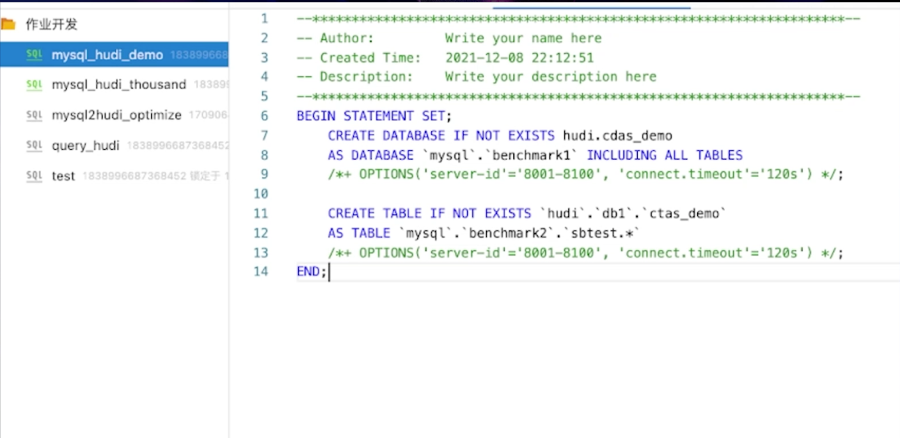
Flink SQL执行create table as table,可以把MySQL库下所有匹配正则表达式的表同步到Hudi单表,是多对一的映射关系,会做分库分表的合并。
-
Flink SQL执行create database as database,可以把 MySQL库下所有的表结构和表数据一键同步到下游数据库,暂时不支持hudi表,计划支持中。
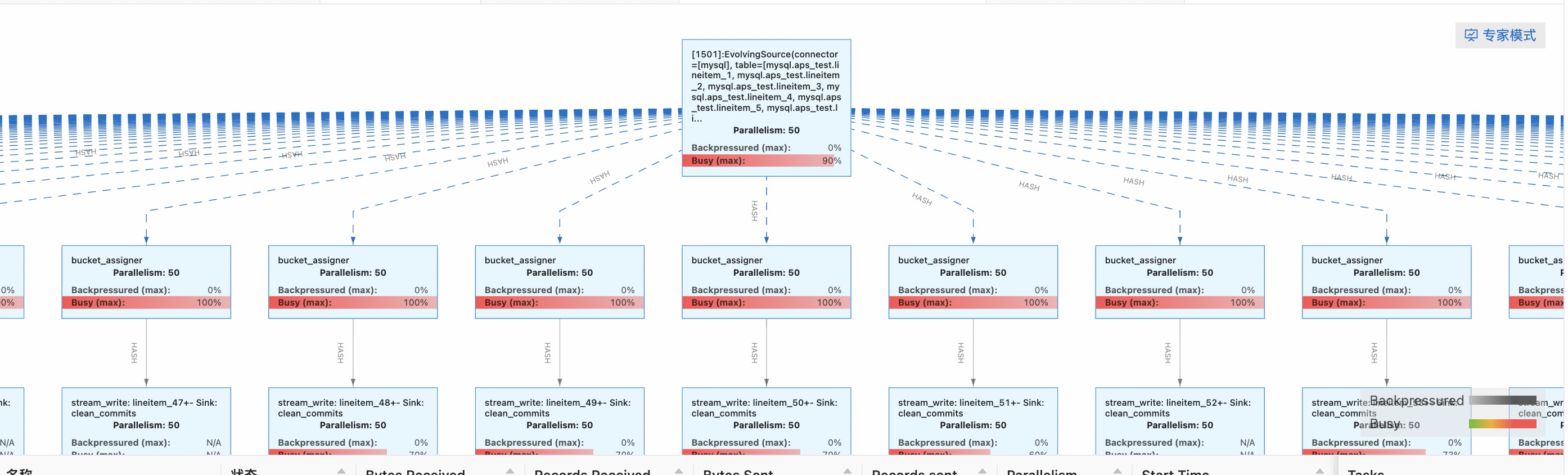
启动任务后的拓扑如下,一个源端binlog source算子将数据分发到下游所有Hudi Sink算子上。
通过Flink VVP可以比较简单地实现多表CDC入湖,然而,这个方案仍然存在以下的一些问题:
-
没有成熟的产品化的入湖管理界面,如增删库表,修改配置等需要直接操作Flink作业,添加统一的库表名前缀需要写sql hint。(VVP更多的还是一个全托管Flink平台而不是一个数据湖产品)
-
只提供了Flink的部署形态,在不进行额外比较复杂的配置的情况下,Compaction/Clean等TableService必须运行在链路内,影响写入的性能和稳定性。
综合考虑后,我们决定采用类似Flink VVP多表CDC入湖的方案,在AnalyticDB MySQL上提供产品化的多表CDC全增量入湖的功能。
2. 基于Flink CDC + Hudi 实现多表CDC入湖
2.1. 整体架构
AnalyticDB MySQL多表CDC入湖的主要设计目标如下:
-
支持一键启动入湖任务消费多表数据写入Hudi,降低客户管理成本。
-
提供产品化管理界面,用户可以通过界面启停编辑入湖任务,提供库表名统一前缀,主键映射等产品化功能。
-
尽可能降低入湖成本,减少入湖过程中需要部署的组件。
基于这样的设计目标,我们初步选择了以Flink CDC作为binlog和全量数据源,并且不经过任何中间缓存,直接写入Hudi的技术方案。

Flink CDC 是 Apache Flink 的一个Source Connector,可以从 MySQL等数据库读取快照数据和增量数据。在Flink CDC 2.0 中,实现了全程无锁读取,全量阶段并发读取以及断点续传的优化,更好地达到了“流批一体”。
使用了Flink CDC的情况下,我们不需要担心全量增量的切换,可以使用统一的Hudi Upsert接口进行数据消费,Flink CDC会负责多表全增量切换和位点管理,降低了任务管理的负担。而Hudi并不支持原生消费多表数据,所以需要开发一套代码,将Flink CDC的数据写入到下游多个Hudi表。
这样实现的好处是:
-
链路短,需要维护的组件少,成本低(不需要依赖独立部署的binlog源组件如kafka,阿里云DTS等)
-
业界有方案可参考,Flink CDC + Hudi 单表入湖是一个比较成熟的解决方案,阿里云VVP也已经支持了Flink多表写入Hudi。
下面详细介绍一下 AnalyticDB MySQL 基于这样架构选型的一些实践经验。
2.2. Flink CDC+ Hudi 支持动态Schema变更
目前通过Flink将CDC数据写入Hudi的流程为
-
数据消费:源端使用CDC Client消费binlog数据,并进行反序列化,过滤等操作。
-
数据转换:将CDC格式根据特定Schema数据转换为Hudi支持的格式,比如Avro格式、Parquet格式、Json格式。
-
数据写入:将数据写入Hudi,部署在TM的多个Hudi Write Client,使用相同的Schema将数据写入目标表。
-
数据提交:由部署在Flink Job Manager的Hudi Coordinator进行单点提交,Commit元数据包括本次提交的文件、写入Schema等信息。
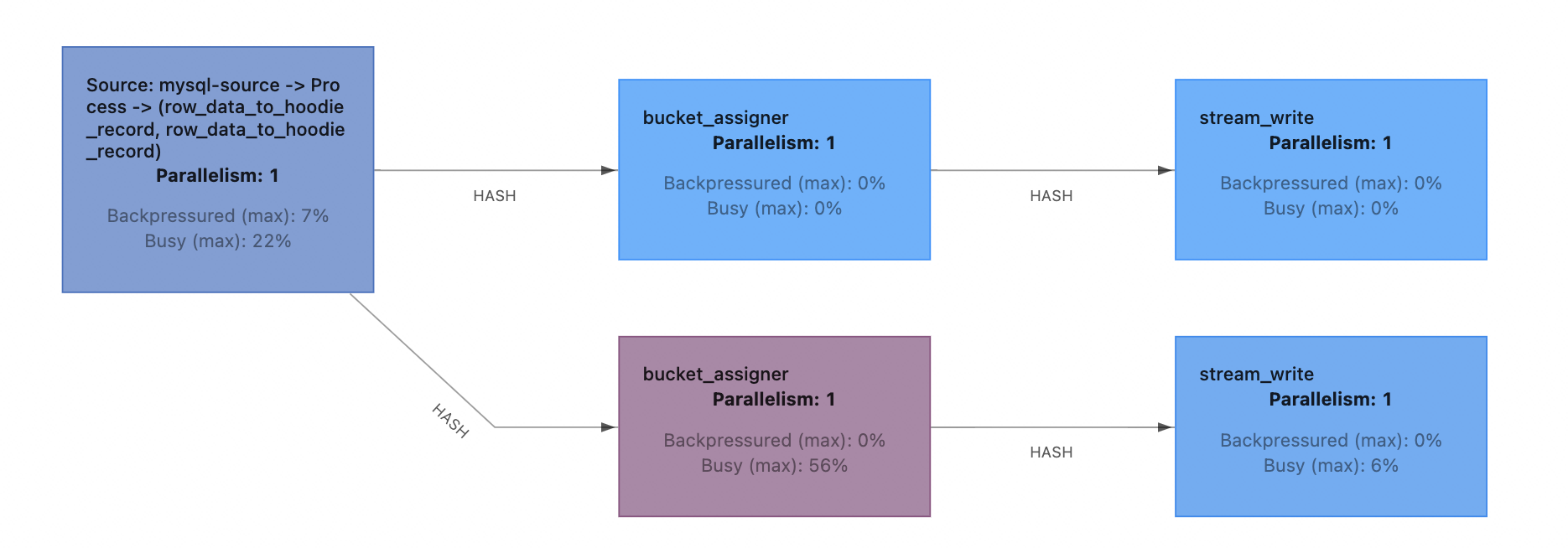
其中,步骤2-4都要用到使用写入Schema,在目前的实现中都是在任务部署前确定好的。同时在任务运行时没有提供动态变更Schema的能力。
针对这个问题,我们设计实现了一套可以动态无干预更新Flink Hudi入湖链路Schema的方案。整体思路为在Flink CDC中识别DDL binlog事件,遇到DDL事件时,停止消费增量数据,等待savepoint完成后以新的schema重新启动任务。
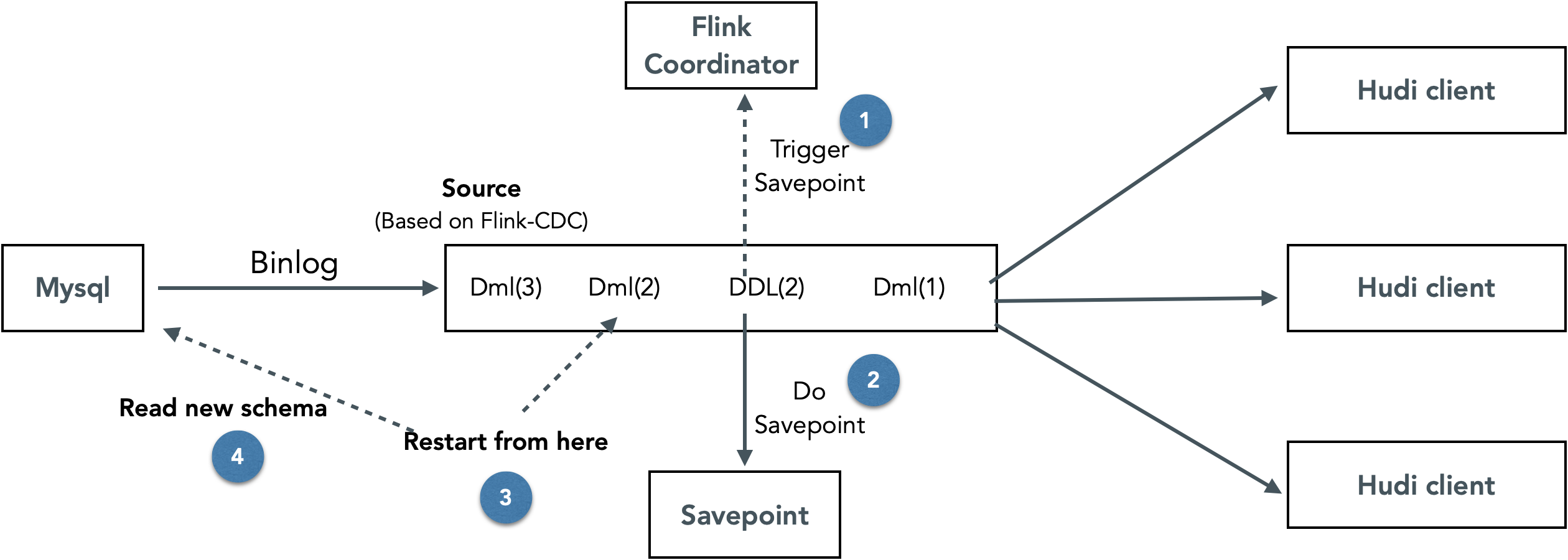
这样实现的好处是可以动态更新链路中的Schema,不需要人工干预。缺点是需要停止所有库表的消费再重启,DDL频繁的情况下对链路性能的影响很大。
2.3. Flink多表读写性能调优
2.3.1. Flink CDC + Hudi Bucket Index 全量导入调优
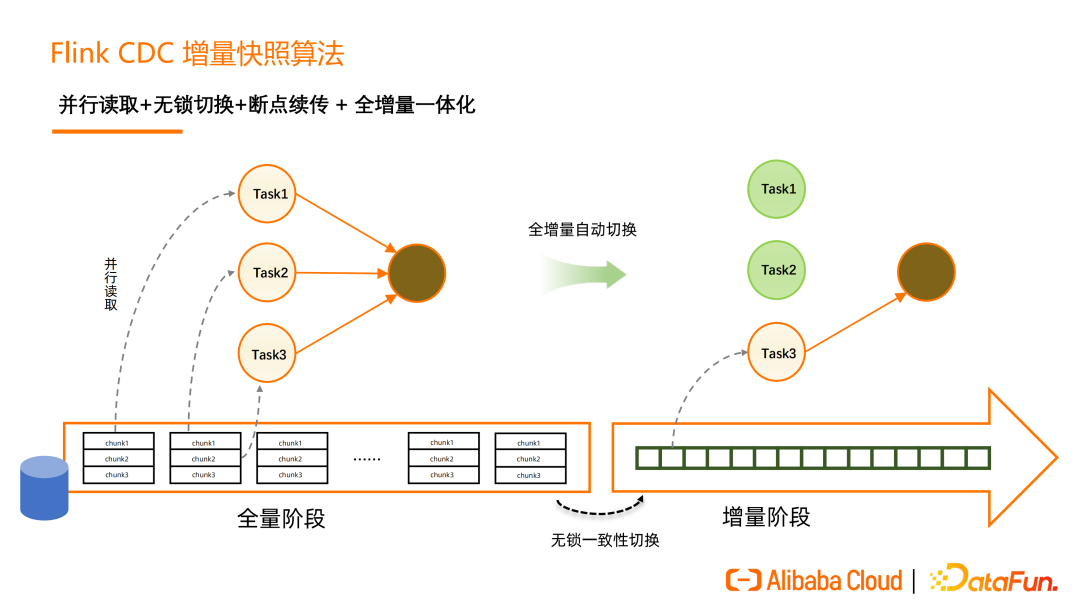
这里首先简单介绍一下Flink CDC 2.0 全量读取 + 全增量切换的流程。在全量阶段,Flink CDC会将单表根据并行度划分为多个chunk并分发到TaskManager并行读取,全量读取完成后可以在保证一致性的情况下,实现无锁切换到增量,真正做到“流批一体”。
在导入的过程中,我们发现了两个问题:
1)全量阶段写入的数据为log文件,但为加速查询,需要compact成Parquet,带来写放大
由于全量和增量的切换Hudi是没有感知的,所以为了实现去重,在全量阶段我们也必须使用Hudi的Upsert接口,而Hudi Bucket Index的Uspert会产生log文件,需要进行一次Compaction才能得到parquet文件,造成一定的写放大。并且如果全量导入的过程中compaction多次,写放大会更加严重。
那么能不能牺牲读取性能,只写入log文件呢? 答案也是否定的,log文件增多不仅会降低读取性能,也会降低oss file listing的性能,使得写入也变慢(写入的时候会list当前file slice中的log和base文件)
解决方法:调大Ckp间隔或者全量增量使用不同的compaction策略解决(全量阶段不做compaction)
2)Flink 全量导入表之间为串行,而写Hudi的最大并发为Bucket数,有时无法充分利用集群并发资源
Flink CDC全量导入的是表内并行,表之间串行。导入单表的时候,如果读+写的并发小于集群的并发数,会造成资源浪费,在集群可用资源较多的时候,可能需要适当调高Hudi的Bucket数以提高写入并发 。而小表并不需要很大的并发即可导入完成,在串行导入多个小表的时候一般会有资源浪费情况。如果可以支持小表并发导入,全量导入的性能会有比较好的提升。
解决办法:适当的调大Hudi bucket数来提高导入性能。
2.3.2. Flink CDC + Hudi Bucket Index 增量调优
1) Checkpoint 反压调优
在全增量导入的过程中,我们发现链路Hudi Ckp经常反压引起写入抖动:
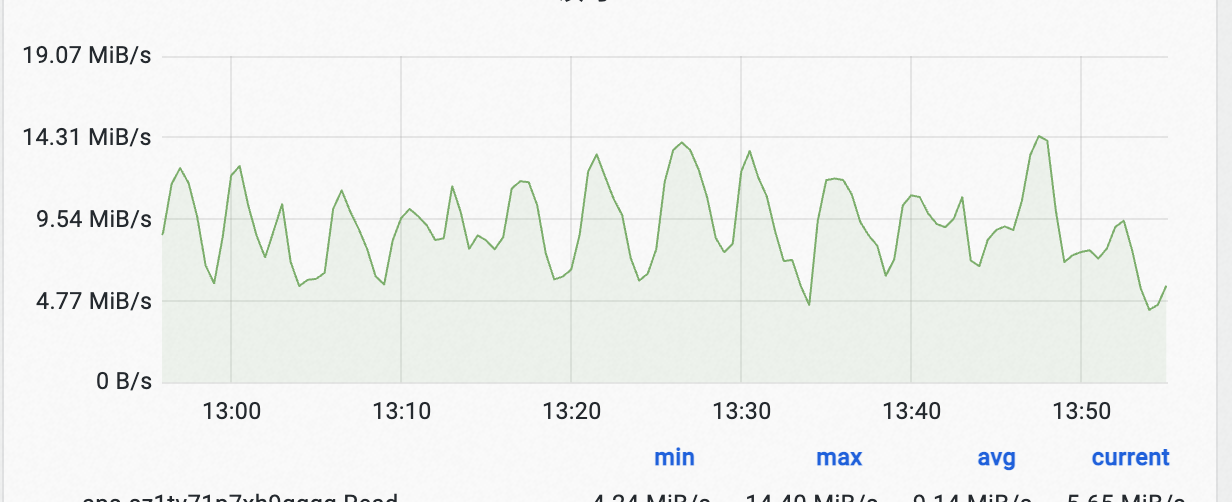
可以发现写入流量的波动非常大。
我们详细排查了写入链路,发现反压主要是因为Hudi Ckp时会flush数据,在流量比较大时候,可能需要在一个ckp间隔内flush 3G数据,造成写入停顿。
解决这个问题的思路就是调小Hudi Stream Write的buffer大小(即write.task.max.size)将Checkpoint窗口期间flush数据的压力平摊到平时。
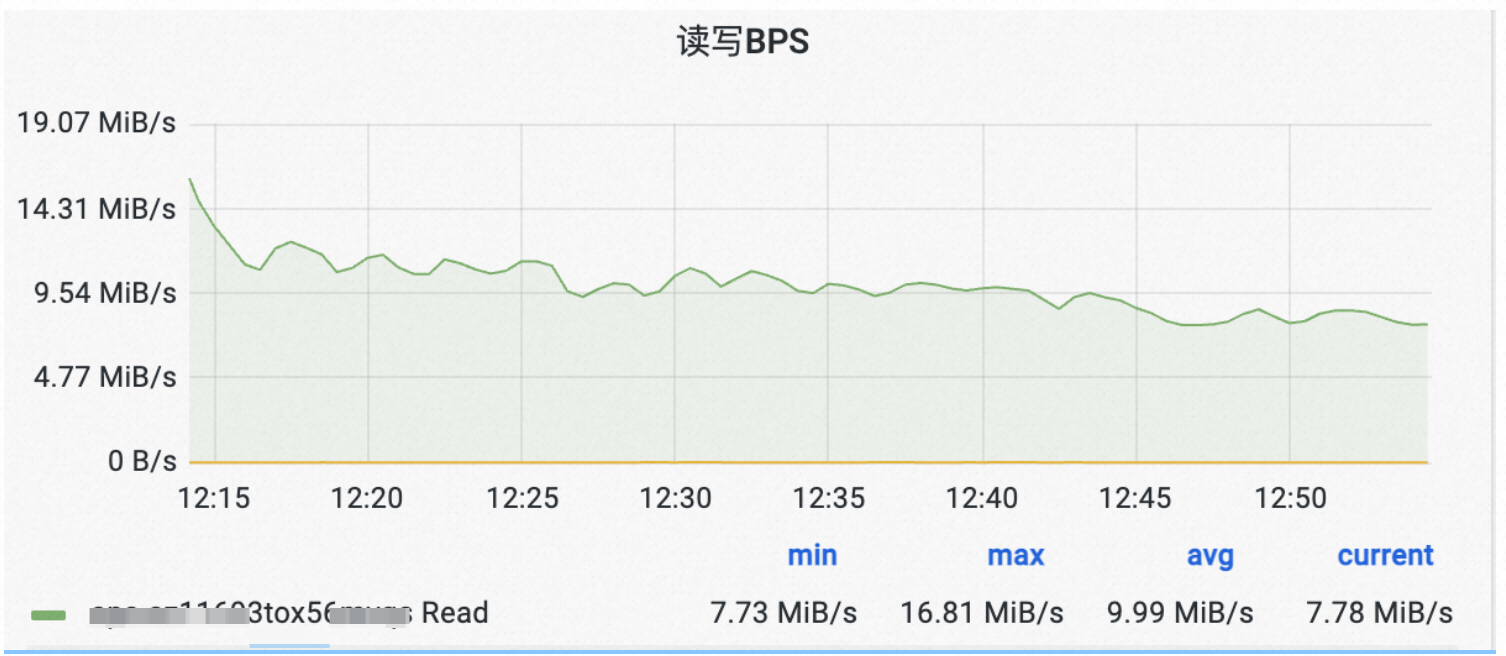
从上图可以看到,调整了buffer size后,因checkpoint造成了反压引起的写入流量变化得到了很好的缓解。
为了缓解Ckp的反压,我们还做了其他的一些优化:
-
调小Hudi bucket number,减少Ckp期间需要flush的文件个数(这个和全量阶段调大bucket数是冲突的,需要权衡选择)
-
使用链路外Spark作业及时运行Compaction,避免积累log文件过多导致写log时list files的开销过大
2) 提供合适的写入Metrics帮助排查性能问题
在调优flink链路的过程中,我们发现了flink hudi写入相关的metrics缺失的比较严重,排查时需要通过比较麻烦的手段分析性能(如观察现场日志,dump内存、做cpu profiling等)。于是,我们在内部开发了一套Flink Stream Write的 Metrics 指标帮助我们可以快速的定位性能问题。
指标主要包括:
-
当前Stream Write算子占据的buffer大小
-
Flush Buffer耗时
-
请求OSS创建文件耗时
-
当前活跃的写入文件数
-
....
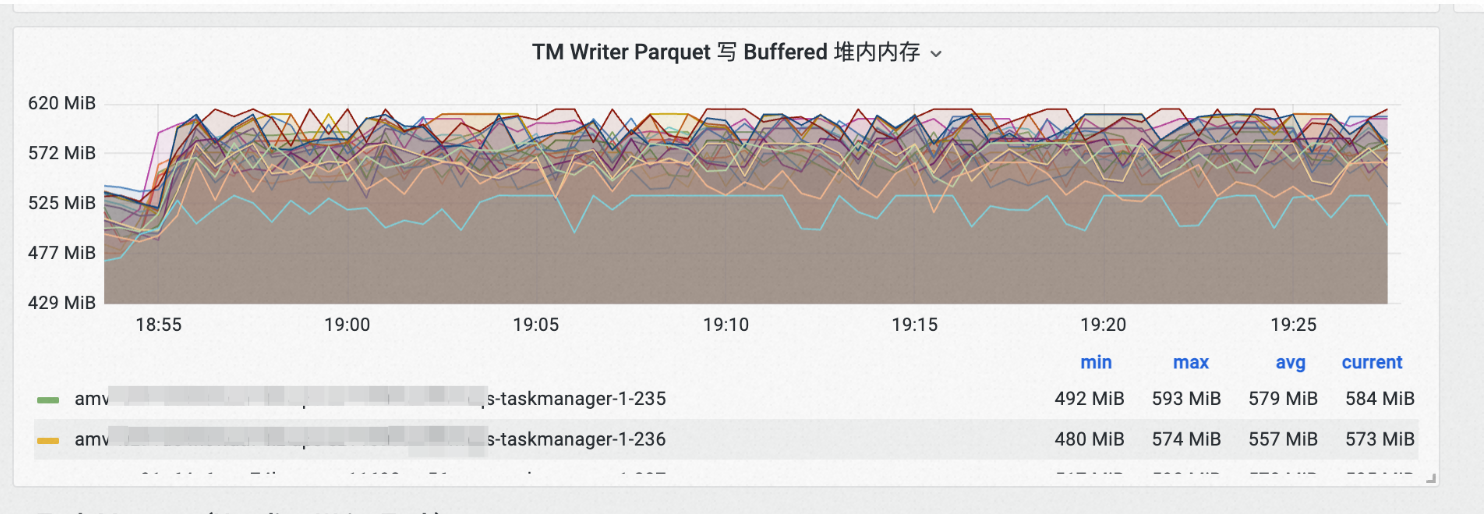
Stream Write/Append Write 占据的堆内内存Buffer大小统计:
Parquet/Avro log Flush到磁盘耗时:
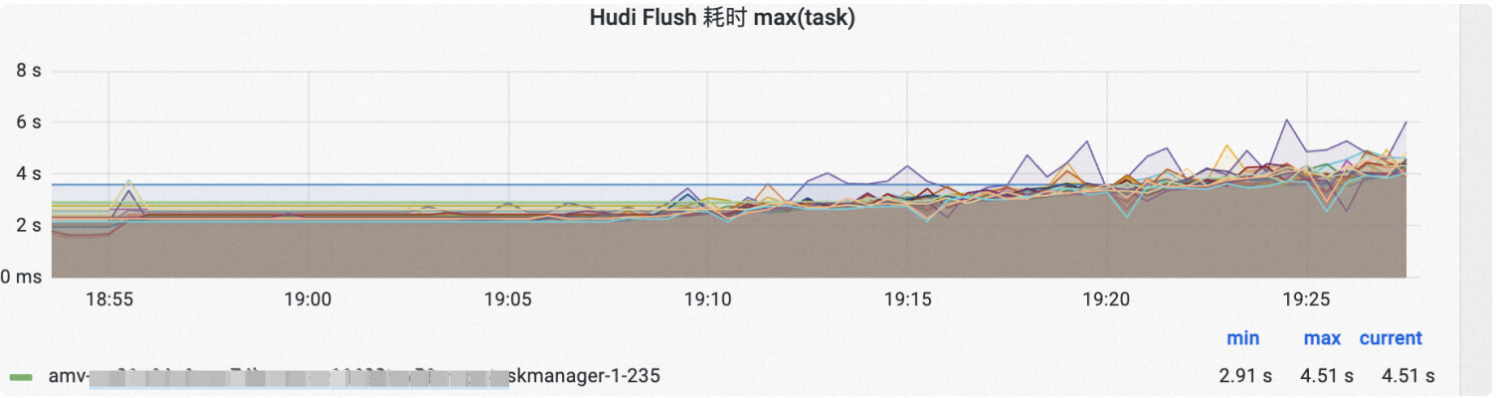
通过指标值的变化可以帮助快速定位问题,比如上图Hudi flush的耗时有一个上扬的趋势,我们很快定位发现了因为Compaction做得不及时,导致log文件积压,使得file listing速度减慢。在调大Compaction资源后,Flush耗时可以保持平稳。
Flink-Hudi Metrics相关的代码我们也在持续贡献到社区,具体可以参考HUDI-2141。
3) Compaction调优
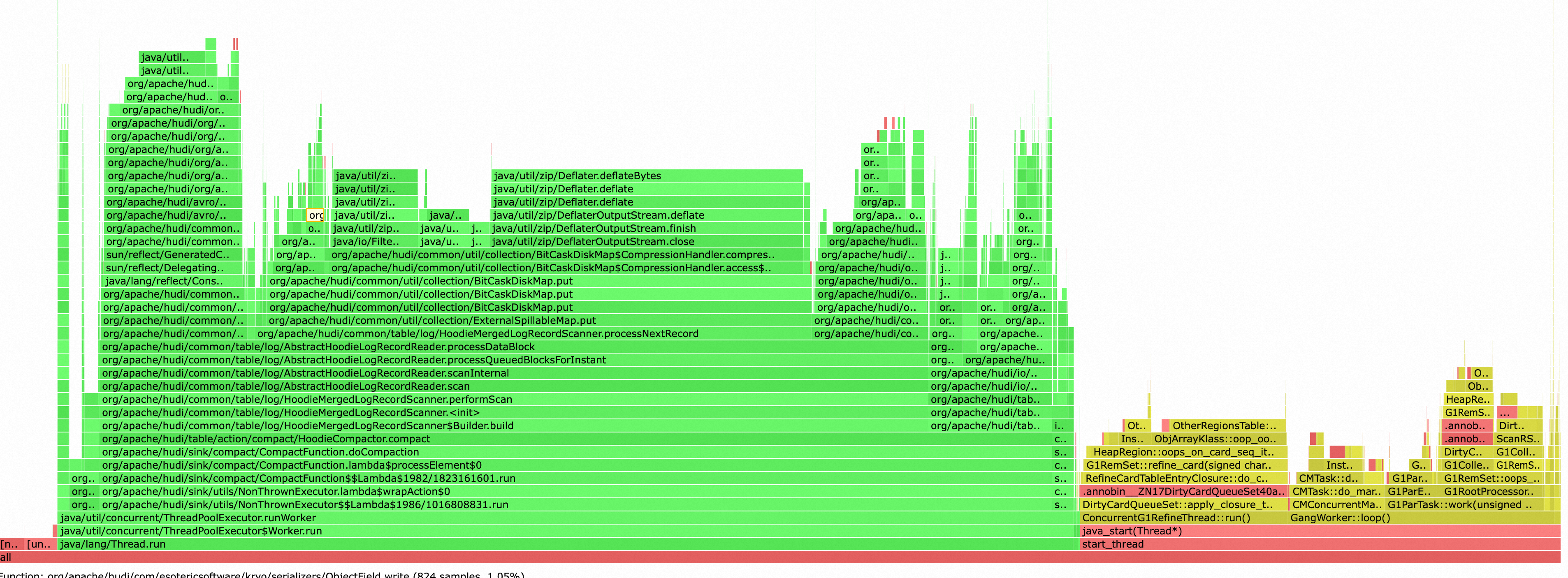
为了简化配置,我们一开始采用了在链路内Compaction的方案,但是我们很快就发现了Compaction对写入资源的抢占非常严重,并且负载不稳定,很大影响了写入链路的性能和稳定性。如下图,Compaction和GC几乎吃满了Task Manager的Cpu资源。
于是,我们采用了TableService和写入链路分离部署的策略,使用Spark离线任务运行TableService,使得TableService和写入链路相互不影响。并且,Table Service的消耗的是Serverless资源,按需收费。写入链路因为不用做Compaction,可以保持一个比较小的资源,整体来看资源利用率和性能稳定性都得到了很好的提升。
为了方便管理数据库内多表的TableService,我们开发了一个可以在单个Spark任务内运行多表的多个TableService的实用工具,目前已经贡献到社区,可以参见PR。
3. Flink CDC Hudi 多表入湖总结
经过我们多轮的开发和调优,Flink CDC 多表写入 Hudi 达到了一个基本可用的状态。其中,我们认为比较关键的稳定性/性能优化是
-
将Compaction从写入链路独立出去,提高写入和Compaction的资源利用率
-
开发了一套Flink Hudi Metrics系统,结合源码和日志精细化调优Hoodie Stream Write。
但是,这套架构方案仍然存在以下的一些无法简单解决的问题:
-
Flink Hudi不支持schema evolution。Hudi转换Flink Row到HoodieRecord所用的schema在拓扑被创建时固定,这意味着每次DDL都需要重启Flink链路,影响增量消费。而支持不停止任务动态变更Schema在Flink Hudi场景经POC,改造难度比较大。
-
多表同步需要较大的资源开销,对于没有数据的表,仍然需要维护他们的算子,造成不必要的开销。
-
新增同步表和摘除同步表需要重启链路。Flink任务拓扑在任务启动时固定,新增表/删除表都需要更改拓扑重启链路,影响增量消费。
-
直接读取源库/binlog对源库压力大,多并发读取binlog容易打挂源库,也使得binlog client不稳定。并且由于没有中间缓存,一旦binlog位点过期,数据需要重新导入。
-
全量同步同一时刻只能并发同步一张表,对于小表的导入不够高效,大表也有可能因为并发设置较小而利用不满资源。
-
Hudi的Bucket数对全量导入和增量Upsert写入的性能影响很大,但是使用Flink CDC + Hudi的框架目前没办法为数据库里不同的表决定不同的Bucket数,使得这个值难以权衡。
如果继续基于这套方案实现多表CDC入湖,我们也可以尝试从下面的一些方向着手:
-
优化Flink CDC全量导入,支持多表并发导入,支持导入时对源表数据量进行sample以动态决定Hudi的Bucket Index Number。解决上述问题5,问题6。
-
引入Hudi的Consistent Hashing Bucket Index,从Hudi端解决bucket index数无法动态变更的问题,参考HUDI-6329。解决上述问题5,问题6。
-
引入一个新的binlog缓存组件(自己搭建或者使用云上成熟产品),下游多个链路从缓存队列中读取binlog,而不是直接访问源库。解决上述问题4。
-
Flink支持动态拓扑,或者Hudi支持动态变更Schema。解决上述问题1,2,3。
不过,基于经过内部讨论和验证,我们认为继续基于Flink + Hudi框架实现多表CDC全增量入湖难度较大,针对这个场景,应该更换为Spark引擎。主要的一些考虑如下。
-
上述讨论的Flink-Hudi优化方向,工程量和难度都比较大,有些涉及到了核心机制的变动。
-
团队内部对Spark全增量多表入湖有一定的积累,线上已经有了长期稳定运行的客户案例。
-
基于Spark引擎的功能丰富度更好,如Spark微批语义可以支持隐式的动态Schema变更,Table Service也更适合使用Spark批作业运行。
在我们后续的实践中,也证实了我们的判断是正确的。引擎更换为Spark后,多表CDC全增量入湖的功能丰富程度,扩展性,性能和稳定性都得到了很好的提升。我们将在之后的文章中介绍我们基于Spark+Hudi实现多表CDC全增量的实践,也欢迎读者们关注。
4. 参考资料
PS:如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”,将会是我不竭的动力!
作者:leesf 掌控之中,才会成功;掌控之外,注定失败。
出处:http://www.cnblogs.com/leesf456/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果觉得本文对您有帮助,您可以请我喝杯咖啡!



 浙公网安备 33010602011771号
浙公网安备 33010602011771号