Hadoop和Spark场景、性能比较
Hadoop和Spark
Spark 基于内存进行数据处理,适合数据量大,对实时性要求不高的场合。
Hadoop 要求每个步骤的数据序列化到磁盘,I/O成本高,导致交互分析迭代算法开销很大。
Hadoop 的MapReduce 表达能力有限,所有计算都要转换成 Map和Reduce两个操作,不能适用于所有场景,对于复杂的数据处理过程难以描述。
Spark 的计算模式也属于MapReduce类型,但Spark不仅提供了 Map 和 Reduce操作,还包括了 Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort、PartionBy 等多种转换操作,以及 Count、Collect、Reduce、Lookup、Save 等行为操作
Spark基于DAG(有向无环图)的任务调度执行机制比Hadoop Mapreduce 的迭代执行机制更优越!
Spark 各个处理结点之间的通信模型不再像 Hadoop 一样只有 Shuffle 一种模式,程序开发者可以使用 DAG 开发复杂的多步数据管道,控制中间结果的存储、分区等。
二者执行流程对比
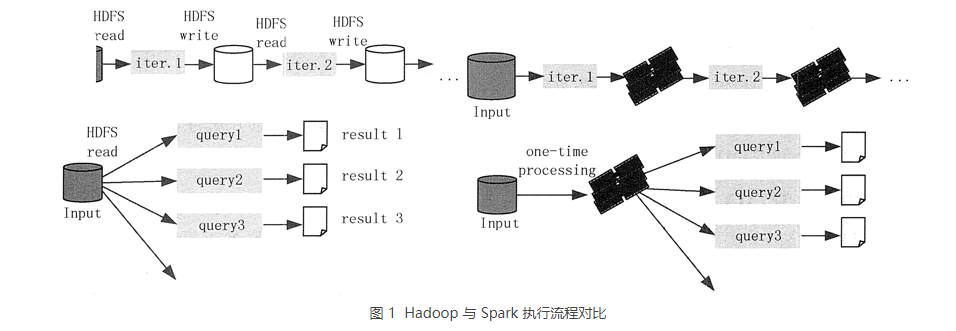
从中可以看出,Hadoop 不适合于做迭代计算,因为每次迭代都需要从磁盘中读入数据,向磁盘写中间结果,而且每个任务都需要从磁盘中读入数据,处理的结果也要写入磁盘,磁盘 I/O 开销很大。而 Spark 将数据载入内存后,后面的迭代都可以直接使用内存中的中间结果做计算,从而避免了从磁盘中频繁读取数据。
对于多维度随机查询也是一样。在对 HDFS 同一批数据做成百或上千维度查询时,Hadoop 每做一个独立的查询,都要从磁盘中读取这个数据,而 Spark 只需要从磁盘中读取一次后,就可以针对保留在内存中的中间结果进行反复查询。
Spark 在 2014 年打破了 Hadoop 保持的基准排序(SortBenchmark)记录,使用 206 个结点在 23 分钟的时间里完成了 100TB 数据的排序,而 Hadoop 则是使用了 2000 个结点在 72 分钟才完成相同数据的排序。也就是说,Spark 只使用了百分之十的计算资源,就获得了 Hadoop 3 倍的速度。
尽管与 Hadoop 相比,Spark 有较大优势,但是并不能够取代 Hadoop。
因为 Spark 是基于内存进行数据处理的,所以不适合于数据量特别大、对实时性要求不高的场合。另外,Hadoop 可以使用廉价的通用服务器来搭建集群,而 Spark 对硬件要求比较高,特别是对内存和 CPU 有更高的要求。
总结
总而言之,大数据处理场景有以下几个类型。
1)复杂的批量处理
偏重点是处理海量数据的能力,对处理速度可忍受,通常的时间可能是在数十分钟到数小时。
2)基于历史数据的交互式查询
通常的时间在数十秒到数十分钟之间。
3)基于实时数据流的数据处理
通常在数百毫秒到数秒之间。
目前对以上三种场景需求都有比较成熟的处理框架::
用 Hadoop 的 MapReduce 技术来进行批量海量数据处理。
用 Impala 进行交互式查询。
用 Storm 分布式处理框架处理实时流式数据。
以上三者都是比较独立的,所以维护成本比较高,而 Spark 能够一站式满足以上需求。
通过以上分析,可以总结 Spark 的适应场景有以下几种:
1)Spark 是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大;数据量小但是计算密集度较大的场合,受益就相对较小。
2)Spark 适用于数据量不是特别大,但是要求实时统计分析的场景。
3)由于 RDD 的特性,Spark 不适用于那种异步细粒度更新状态的应用,例如,Web 服务的存储,或增量的 Web 爬虫和索引,也就是不适合增量修改的应用模型。
你应当热爱自由!
作者:Leejk,转载请注明原文链接:https://www.cnblogs.com/leejk/p/16309821.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号