数据仓库分层概念
数据仓库分层
ODS数据运营层

该层存储进行清洗后的源数据,如MySQL的数据映射到Hive中,装到Hive的数据就是ODS层。源数据装入该数据需要进行筛选,比如源数据有 name = 喻文波,age = - 100岁,该数据属于异常数据,需要处理(剔除)掉。
DW数据仓库层
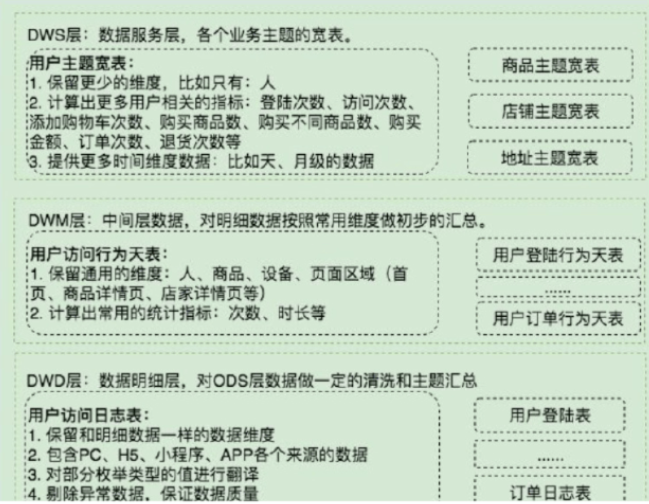
数据仓库层(DW),是数据仓库的主体,在这⾥,从 ODS 层中获得的数据按照主题建⽴各种数据模型。这⼀层和维度建模会有⽐较深的联系。
细分:
数据明细层:DWD(Data Warehouse Detail)
数据仓库的细节数据层,是对STAGE层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循业务事务处理的形式,将各个专业数据进行集中,明细层跟STAGE层的粒度一致,属于分析的公共资源。
数据中间层:DWM(Data WareHouse Middle)
概念:轻度汇总层数据仓库中DWD层和DM层之间的⼀个过渡层次,是对DWD层的⽣产数据进⾏轻度综合和汇总统计(可以把复杂的清洗,处理包含,如根据PV⽇志⽣成的会话数据)。轻度综合层与DWD的主要区别在于⼆者的应⽤领域不同,DWD的数据来源于⽣产型系统,并未满意⼀些不可预见的需求⽽进⾏沉淀;轻度综合层则⾯向分析型应⽤进⾏细粒度的统计和沉淀
数据⽣成⽅式:由明细层按照⼀定的业务需求⽣成轻度汇总表。明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接⼊到轻度汇总层。
⽇志存储⽅式:内表,parquet⽂件格式。
⽇志删除⽅式:长久存储。
表schema:⼀般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名。库名:dwb,表名:初步考虑格式为:dwb⽇期业务表名,待定。
旧数据更新⽅式:直接覆盖
数据服务层:DWS主题层(Data WareHouse Servce)
又称宽表,按照业务划分,如流量,用户,商品订单,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
数据生成方式:由轻度汇总层和明细层数据计算生成
日志存储方式:使用impala内表,parquet文件格式
日志删除方式:长久存储
表scheme:按天创建分区,没有时间字段按业务创建分区
库与表的命名:库:dm,表:dm日期业务表名
旧数据更新方式:直接覆盖
APP数据产品层

提供为数据产品使用的结果数据。
主要是提供给数据产品和数据分析使⽤的数据,⼀般会存放在 ES、Mysql 等系统中供线上系统使⽤,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使⽤。
如我们经常说的报表数据,或者说那种⼤宽表,⼀般就放在这⾥。
应⽤层(App)
概念:应⽤层是根据业务需要,由前⾯三层数据统计⽽出的结果,可以直接提供查询展现,或导⼊⾄Mysql中使⽤。
数据⽣成⽅式:由明细层、轻度汇总层,数据集市层⽣成,⼀般要求数据主要来源于集市层。
⽇志存储⽅式:使⽤impala内表,parquet⽂件格式。
⽇志删除⽅式:长久存储。
表schema:⼀般按天创建分区,没有时间概念的按具体业务选择分区字段。
库与表命名。库名:apl,另外根据业务不同,不限定⼀定要⼀个库。(其实就叫app_)就好了
旧数据更新⽅式:直接覆盖。
一图设计数据分层
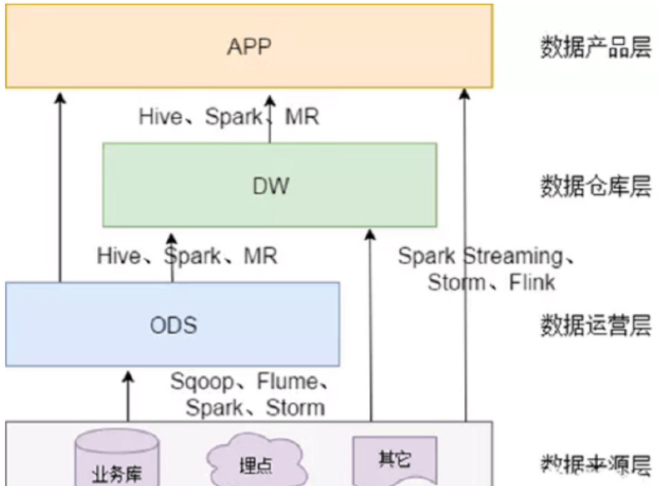
数据来源
业务库,这⾥经常会使⽤ Sqoop 来抽取我们业务库⽤的是databus来进⾏接收,处理kafka就好了。
实时⽅⾯,可以考虑⽤ Canal 监听 Mysql 的 Binlog,实时接⼊即可。
埋点⽇志,线上系统会打⼊各种⽇志,这些⽇志⼀般以⽂件的形式保存,我们可以选择⽤ Flume 定时抽取,也可以⽤⽤ Spark Streaming或者 Storm 来实时接⼊,当然,Kafka 也会是⼀个关键的⾓⾊。
还有使⽤filebeat收集⽇志,打到kafka,然后处理⽇志
注意: 在这层,理应不是简单的数据接⼊,⽽是要考虑⼀定的数据清洗,⽐如异常字段的处理、字段命名规范化、时间字段的统⼀等,⼀般这些很容易会被忽略,但是却⾄关重要。特别是后期我们做各种特征⾃动⽣成的时候,会⼗分有⽤。
ODS、DW → App层
这⾥⾯也主要分两种类型:
每⽇定时任务型:⽐如我们典型的⽇计算任务,每天凌晨算前⼀天的数据,早上起来看报表。 这种任务经常使⽤ Hive、Spark 或者⽣撸
MR 程序来计算,最终结果写⼊ Hive、Hbase、Mysql、Es 或者 Redis 中。
实时数据:这部分主要是各种实时的系统使⽤,⽐如我们的实时推荐、实时⽤户画像,⼀般我们会⽤ Spark Streaming、Storm 或者Flink 来计算,最后会落⼊ Es、Hbase 或者 Redis 中。
DIM维表层
Dimension
高基数维度数据:一般是用户信息表,商品信息表等,数据量庞大,千万级别
低基数维度数据:一般是配置表,比如枚举值对应表,日期维表,数据量小,万级别
分层结构举例
对DWD进行加工操作后,就是DWM层,下图简单以DWD进行解释
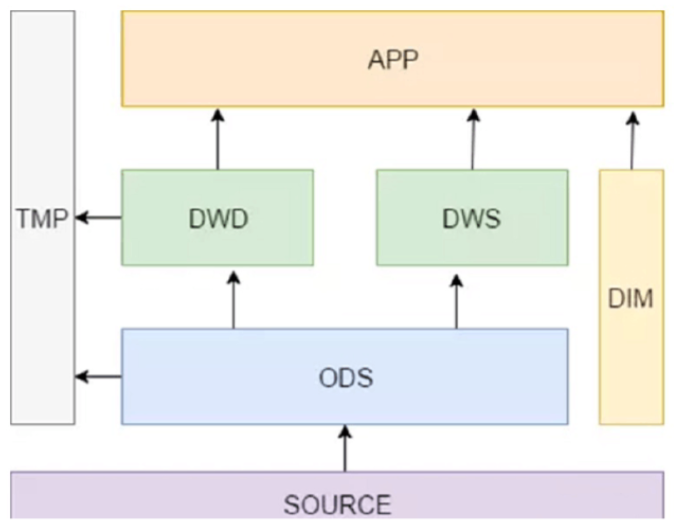
DWS:轻度汇总层,从ODS层中对⽤户的⾏为做⼀个初步的汇总,抽象出来⼀些通⽤的维度:时间、ip、id,并根据这些维度做⼀些统计
值,⽐如⽤户每个时间段在不同登录ip购买的商品数等。这⾥做⼀层轻度的汇总会让计算更加的⾼效,在此基础上如果计算仅7天、30天、
90天的⾏为的话会快很多。我们希望80%的业务都能通过我们的DWS层计算,⽽不是ODS。
DWD:这⼀层主要解决⼀些数据质量问题和数据的完整度问题。⽐如⽤户的资料信息来⾃于很多不同表,⽽且经常出现延迟丢数据等问
题,为了⽅便各个使⽤⽅更好的使⽤数据,我们可以在这⼀层做⼀个屏蔽。(汇总多个表)
DIM:这⼀层⽐较单纯,举个例⼦就明⽩,⽐如国家代码和国家名、地理位置、中⽂名、国旗图⽚等信息就存在DIM层中。
TMP:每⼀层的计算都会有很多临时表,专设⼀个DWTMP层来存储我们数据仓库的临时表。
一图总结

你应当热爱自由!
作者:Leejk,转载请注明原文链接:https://www.cnblogs.com/leejk/p/16304656.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)