浅谈分布式锁与Redis集群实现分布式锁
分布式系统
什么是分布式系统?
一个分布式系统是一组计算机系统一起工作,在终端用户看来,就像一台计算机在工作一样。
这些机器具有共享状态,并发操作并可独立故障,而不会影响整个系统的正常运行时间。
如设计一个分布式数据库:假设我们使用了三台机器来构建这台分布式数据库,我们追求的结果是,在机器1上插入一条记录,需要在机器3上可以返回那条记录,当然,机器1和2也要能够返回这条记录。
分布式系统的优点
分布式系统最大的好处就是能够让你横向的扩展系统。
-
以单一数据库为例,能够处理更多流量的唯一方式就是升级数据库运行的硬件,这就是纵向扩展。
而纵向扩展的是有局限性的。当到了一定程度以后,我们会发现即使最好的硬件,也不能够满足当前流量的需求。
-
横向扩展是指通过增加更多的机器来提升整个系统的性能,而不是靠升级单台计算机的硬件。
横向扩展则没有这个限制,它没有上限,每当性能下降的时候,你就需要增加一台机器,这样理论上讲可以达到无限大的工作负载支持。
分布式系统在容错和低延迟上也有很多优势。
容错性是指你的分布式系统的某个节点出现错误以后,并不会导致整个系统的瘫痪。而单机系统出错以后,可能会导致整个系统的崩溃。
低延迟是通过在不同的物理位置部署不同的机器,通过就近获取的原则降低访问的延迟时间。
上面讨论了分布式系统的种种好处,但是我们必须要清楚设计和运行分布式系统并非易事。
分布式带来的问题
CAP原则: 任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。
一致性Consistency : 依次读写的是什么就是什么。
可用性Availability : 整个系统不会崩溃, 每个非故障节点总会有一个相应。
分区容忍Partition tolerant : 尽管有分区,系统仍能继续运行并保持其一致性和可用性。
如何选取 ?
对于任何分布式系统来说,分区容忍是一个给定的条件,如果没有这一点,就不可能做到一致性和可用性。试想如果两个节点链接断掉了,他们如何能够做到既可用又一致?
最后你只能选择在网络分区情况下,你的系统要么强一致,要么高可用。
实践表明大多数应用程序更看重可用性。这个考量的主要原因是在不得不同步机器里实现强于一致性时,网络延迟会成为一个问题。这类因素使得应用程序通常会选择提供高可用性的解决方案。
此时采用的是最弱的一致性模型来解决的,这种模型保证了如果没有对某个项目进行新的更新,则该项目的所有访问都会返回目前最新的值。
这些系统提供了BASE属性,这是相对于传统数据库的ACID来讲的。 也就是( Basically available)基本可用的,系统总会返回一个响应。
软状态( Soft state), 系统可以随着时间的推移而变化,甚至在没有输入的情况下也可以变化, 如保持最终的一致性的同步。
最终的一致性(Eventual consistency), 在没有输入的情况下,数据迟早会传播到每一个节点上,从而变得一致。
追求高可用的分布式数据库的例子 - Cassandra,Riak,Voldemort
追求更强一致性的数据存储 --HBase,Couchbase,Redis, Zookeeper
分布式系统的优缺点有哪些?
分布式系统的优点
-
分布式系统中的所有节点都是相互连接的。所以节点可以很容易地与其他节点共享数据。
-
更多的节点可以很容易地添加到分布式系统中,即可以根据需要进行扩展。
-
一个节点的故障不会导致整个分布式系统的失败。其他节点仍然可以相互通信。
-
硬件资源可以与多个节点共享,而不是只限于一个节点。
分布式系统的缺点
-
在分布式系统中很难提供足够的安全,因为节点以及连接都需要安全。
-
一些消息和数据在从一个节点转移到另一个节点时,可能会在网络中丢失。
-
与单用户系统相比,连接到分布式系统的数据库是相当复杂和难以处理的。
-
如果分布式系统的所有节点都试图同时发送数据,网络中可能会出现过载现象。
分布式锁的解决方案
什么是分布式锁?
我们在开发应用的时候,如果需要对某一个共享变量进行多线程同步访问的时候,可以使用锁进行处理,并且可以完美的运行
注意这是单机应用,后来业务发展,需要做集群,一个应用需要部署到几台机器上然后做负载均衡:
上图可以看到,变量A存在三个服务器内存中(这个变量A主要体现是在一个类中的一个成员变量,是一个有状态的对象),如果不加任何控制的话,变量A同时都会在分配一块内存,三个请求发过来同时对这个变量操作,显然结果是不对的!即使不是同时发过来,三个请求分别操作三个不同内存区域的数据,变量A之间不存在共享,也不具有可见性,处理的结果也是不对的!
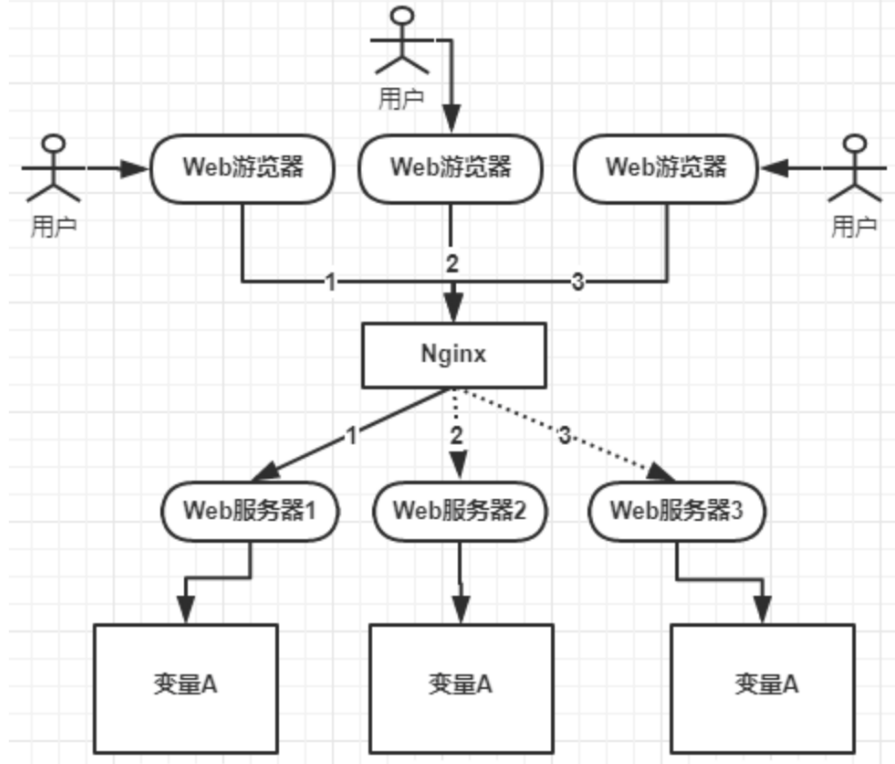
如果我们业务中确实存在这个场景的话,我们就需要一种方法解决这个问题!
为了保证一个方法或属性在高并发情况下的同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用并发处理相关的功能进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的应用并不能提供分布式锁的能力。
为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁应该具备哪些条件?
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
分布式锁的实现方式
基于数据库实现分布式锁;
基于缓存(Redis等)实现分布式锁;
基于Zookeeper实现分布式锁;
Redission
Redisson是一个基于java编程框架netty进行扩展了的redis。
地址:https://github.com/redisson/redisson
Redisson 适用于:分布式应用,分布式缓存,分布式回话管理,分布式服务(任务,延迟任务,执行器),分布式redis客户端。
你应当热爱自由!
作者:Leejk,转载请注明原文链接:https://www.cnblogs.com/leejk/p/15734329.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号