node实现网页内容的爬取
编写爬虫程序大多是后端开发者的工作,但是node的出现使得前端开发者编写爬虫程序变的可能,而且实习操作起来非常的简单。
首先介绍SuperAgent,SuperAgent是一个小型的渐进式客户端HTTP请求库,与Node.js模块具有相同的API,具有许多高级HTTP客户端功能。从这句官方解释就可以看出SuperAgent是在node环境下封装的实现http请求的库,实现网页内容的请求。
cheerio是在node环境下,能够使用像jquery api的方式获取网页dom中的数据。
这两个工具结合在一起可以抓取业务中特定的内容。我们都知道前端的网页开发中,经常将具有相同样式的dom节点用相同的class名来标记,这样可以使它们具有相同的样式,这样就可以让我们对抓取网页中特定的内容提供了方便。
我们以某网站的新闻也为例:
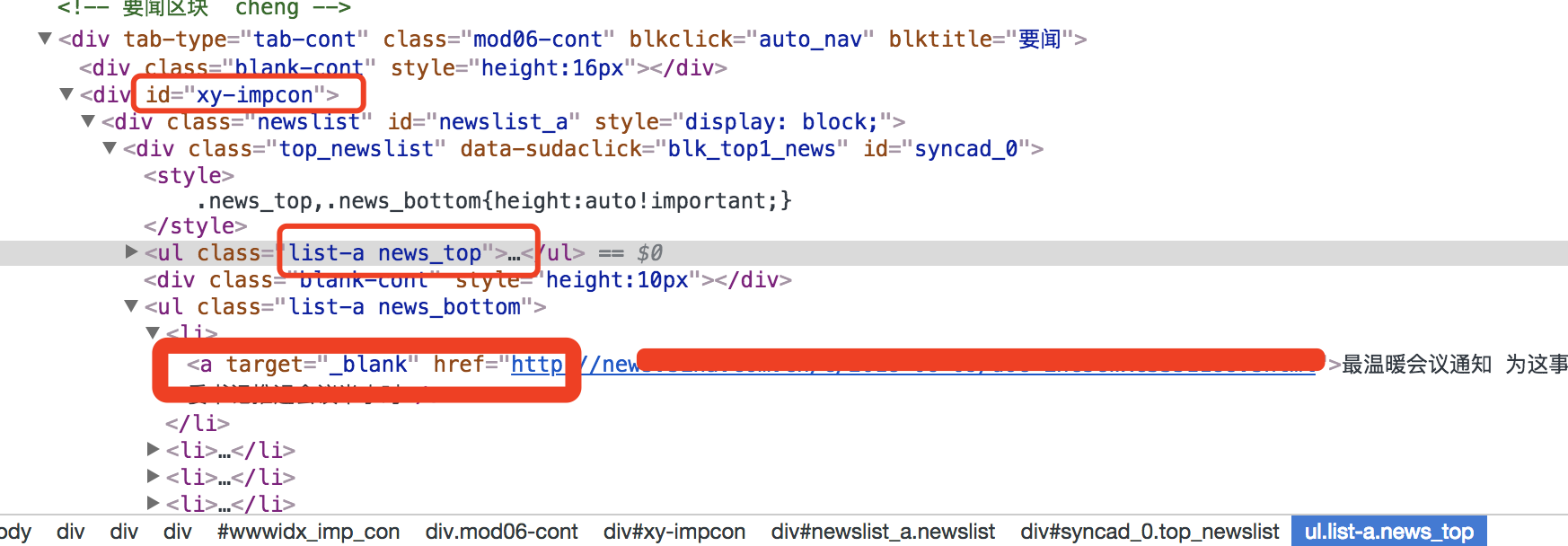
上面图中是新闻列表对应的代码,我们可以看到列表被id="xy-impcon"的div容器包裹,每个类别的新闻列表用ul,ul都有个共同class名list-a,ul下面都有li标签和a标签。如果想获取每个新闻条目我们用cheerio获取dom可以这样写$('#xy-impcon ul.list-a li a'),那么我们就来编写爬取链接和标题程序,并且将爬取的数据保存成文件。
var http = require("http"),
url = require("url"),
superagent = require("superagent"),
cheerio = require("cheerio"),
async = require("async"),
eventproxy = require('eventproxy');
var path = require('path');
var $ = require('jQuery');
var fs = require("fs");
var writerStream2 = fs.createWriteStream(path.resolve(__dirname,'../data/news.txt'),{ flags: 'w',encoding: null,mode: 0666 });
var text = [];
(function (){
superagent.get('爬取网站的url')
.end(function(err,pres){
var $ = cheerio.load(pres.text);
var curPageUrls = $('#xy-impcon ul.list-a li a');
console.log(curPageUrls.length)
curPageUrls.each(function(index, elem){
text.push({
title: $(elem).text(),
url: $(elem).attr('href')
})
})
writerStream2.write(JSON.stringify(text),'UTF8');
});
})();
上面的代码就把爬取的内容都保存成了文件。
除此之外我们还可以使用phantomjs的webpage模块在node环境模拟浏览器端爬取网页数据,生成网页的截图。之后介绍具体用法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号