
大端小端
由于某个问题,最近突然联想到大端小端问题,
时间久远,记忆有点模糊,所以又重新翻看了一下,做个记录,内容大都来源伟大的互联网。。。。。。
1. 大端小端概念
大端小端其实是我们通俗意义上的叫法,实际上指的是计算机存储字节的顺序模式,根据数据在内存中的存储方式分为两种大端字节序模式和小端字节序模式。
大端字节序模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。符合我们的阅读习惯。
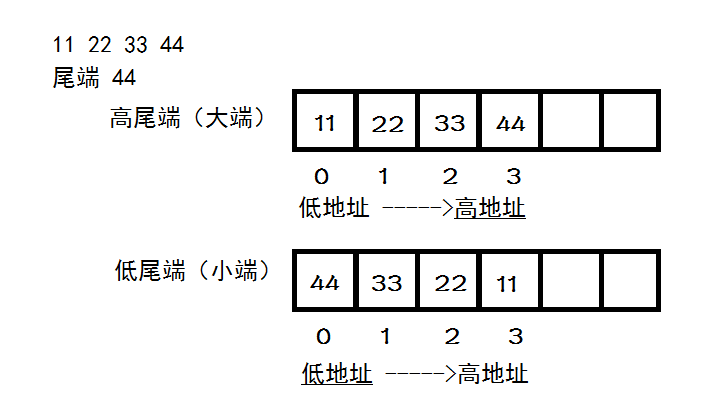
2. 使用场景
一般网络上的数据都是以大端数据模式进行交互的,而我们的主机大多数是以小端数据模式进行处理,所以在做网络通信的时候,往往需要进行转换。
曾经就遇到过socket通信时两边对发二进制结构体,然后读出来的数据非常奇怪,查询下来发现是字节序问题。
socket编程,下面的函数应该不会陌生
htons()、htonl()分别将16位、32位主机数据转换为网络字节序,也称为大端字节序
ntohs()、ntohl()则分别将16位、32位网络字节序转换为主机数据。
3. 编写程序判断大小端(面试中偶尔会遇到)
1. 直接强转,匹配对应内存地址的值,简单明了。
-rwxr-xr-x 1 rtmptest staff 8432 Nov 16 09:37 test
-rw-r--r-- 1 rtmptest staff 267 Nov 15 16:45 test.c
ch71mlp000277:~ rtmptest$ cat test.c
#include <stdio.h>
int main()
{
int i = 0x12345678;
char *c =(char *)&i;
if(c[0] == 0x12 && c[1] == 0x34 && c[2] == 0x56 && c[3] == 0x78)
{
printf("Big-Endian Mode\n");
}
else
{
printf("Little-Endian Mode\n");
}
return 0;
}
ch71mlp000277:~ rtmptest$ gcc -o test test.c
ch71mlp000277:~ rtmptest$ ./test
Little-Endian Mode
ch71mlp000277:~ rtmptest$
2. 通过联合体共用起始地址特性,来匹配对应的值。
#include <stdio.h>
typedef union
{
unsigned short a;
unsigned char b[2];
}u_data;
int main()
{
u_data data;
data.a = 0x1234;
//union data struct: a&b own the same 2 bytes address.
//b[0] is a's lower address
//b[1] is a's higher address.
if(data.b[0] == 0x12 && data.b[1] == 0x34)
{
printf("Big-Endian Mode\n");
}
else
{
printf("Little-Endian Mode\n");
}
printf("b[0]=0x%x,b[1]=0x%x\n",data.b[0],data.b[1]);
return 0;
}
ch71mlp000277:~ rtmptest$ gcc -o test1 test1.c
ch71mlp000277:~ rtmptest$ ./test1
Little-Endian Mode
b[0]=0x34,b[1]=0x12
ch71mlp000277:~ rtmptest$
4. 为什么会有大小端模式之分呢?
内容摘自:https://bbs.csdn.net/topics/390968161
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器)
另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。
因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于 大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号