

1. 新增扩展int类型:long long int,也称long long。
在C++11新特性中,long long一定是最容易被接受的一个。多数程序员看到它时甚至不会意识到这是一个新特性。
与 long long 整型相关的一共有3个:LONG_MIN、LONG_MAX 和ULONG_MAX, 它们分别代表了平台上最小的long long 值、最大的long long 值,以及最大的unsigned long long 值。long long int 64位 , unsigned long long 64位
int64_t用来表示64位整数,在32位系统中是long long int,在64位系统中是long int,所以打印int64_t的格式化方法是:
printf("%ld", value); // 64bit OS
printf("%lld", value); // 32bit OS
2. noexcept
noexcept替代传统的throw抛异常,更大的作用就是保证应用程序的安全
比如: 一个类析构函数不应该抛异常,那么对于常被析构调用的delete,c++11默认将delete设置为noexcept,
使用: .h.cpp文件都需要写
自定义的函数可以如下:
void func() noexcept;
void func() noexcept(true/false);
3. 允许使用 = 或者 {} 进行就地初始化非静态数据成员
如果同时使用类的初始化列表(又称:冒号语法初始化),则初始化列表生效
如下,初始化后,m_high=10,m_strName=test
看起来,是就地初始化先执行,然后才是初始化列表。
class Father { public: Father() :m_high(10) ,m_strName("test") {} private: int m_high = 20; std::string m_strName{"name1"};
注意:
c++11中使用{}初始化,是唯一一种可以防止类型收窄,narrowing的初始化方式, 即:数据变化或者精度丢失,如float->int,高精度到低精度等
这也是{}与其它方式初始化不一样的地方
使用{}初始化,编译器会检查是否出现类型收窄。因此,建议能用{}初始化变量
4. final/override
final: 使派生类无法覆盖它所修饰的虚函数
override: 使用override,则派生类必须覆盖即重写所修饰的虚函数,建议能用就用,避免手一抖写错,新增了一个函数而无法识别
5. using
在c++11前,如果派生类要使用基类的成员函数,可以通过声明using来完成
c++11中,此想法被扩展到构造函数中,使用using来声明继承基类的构造函数,但只能初始化基类的成员,如果要初始化派生类自己的成员,可以使用就地初始化。
如: #include <iostream> #include <string> class A { public: A(int i); A(int i, char c); public: double f(double i) { std::cout << __FUNCTION__ << std::endl; return i; } private: int m_num = 0; char m_c = 'A'; }; class B : public A { public: using A :: A; //使用A的构造函数,C++11后支持 public: using A::f; //使用A的f函数,c++11前就支持 int f(std::string name) { std::cout << __FUNCTION__ << std::endl; return 0; } private: std::string m_strName{"testB"}; }; 使用: int main() { int i = 10; char c = 'B'; double d = 9.98f; B b{i,c}; //c++11中,使用using A :: A 表示使用基类A的构造, //如果没有使用using,此处B没有构造函数,编译报错,如果要实现与A一样的构造,需要全部重写类似B的构造,比较繁琐 //如:B(int i); B(int i, char c). //有了using,直接using,然后自己的变量,就地初始化,方便。 b.f(d); //使用using A::f; 表示使用基类的A的f(double)函数 //如果没有,此处基类A中的f(double)已经被B的f(string)的覆盖了,编译会报错。 }
6. 委派构造
看名字,就知道与构造函数有关
c++11中,所谓委派构造是指将构造的任务委派给了目标函数来完成类的构造
直白点,就是构造函数委派另外的构造函数进行构造。
注意: 当使用了委派构造后,就不能使用初始化列表进行构造了。只能选其一
class Info { public: Info():m_a(0),m_strName("") { Init(); } Info(int i):Info() //委派info构造
{ Init(); m_a = i; } Info(std::string name,int i) :Info(i) //委派info(i)构造
{ Init(); m_strName = name; } //error, if use initialize list, then can not use delegate constructor func // Info(std::string name) :Info(), m_a(i) { // Init(); // m_strName = name; // } private: void Init() { //do any other initialize std::cout << __FUNCTION__ << __FILE__ << __LINE__ << std::endl; } private: int m_a; std::string m_strName; };
7.左值,右值
c语言一个典型的说法,=左边的是是左值,右边的是右值
c++中,一个更广泛认同的说法:那就是可以取地址的,有名字的就是左值,反之就是右值。
更为细致的,c++中,右值分为:将亡值和纯右值
纯右值:
1. 函数的非引用返回的临时变量,
2. 一些计算表达式值,如2+3,
3. 不跟对象关联的纯值,如:1,c,d,
4. 类型转换的返回值
5. lambda表达式
将亡值:则是与右值引用 &&相关的
1. 返回右值引用的函数返回值
2. std::move
3. 类型转发后的&&
左值引用 &
右值引用 &&
c++中,由于右值通常不具有名字,所以我只能通过引用的方式找打它,因此就有了右值引用的表达:&&
比如: T&& a = returnValue();
returnValue返回临时对象,本该在函数返回后,生命周期结束,但是由于使用右值引用T&& a接收,因此其生命就被绑定到a上面,
相比于: T a = returnValue();
减少了一次对象的析构与一次对象的构建。
C++11之后引入了引用折叠规则,如:T &&,
当实参类型是一个左值引用,则会推导为X& &&,引用折叠规则最终为X&
当实参类型是一个右值引用,则会推导为X&& &&,引用折叠规则最终为X&&。
即,可以理解T&&为万能引用,无论左值引用右值引用,它都可以接收。
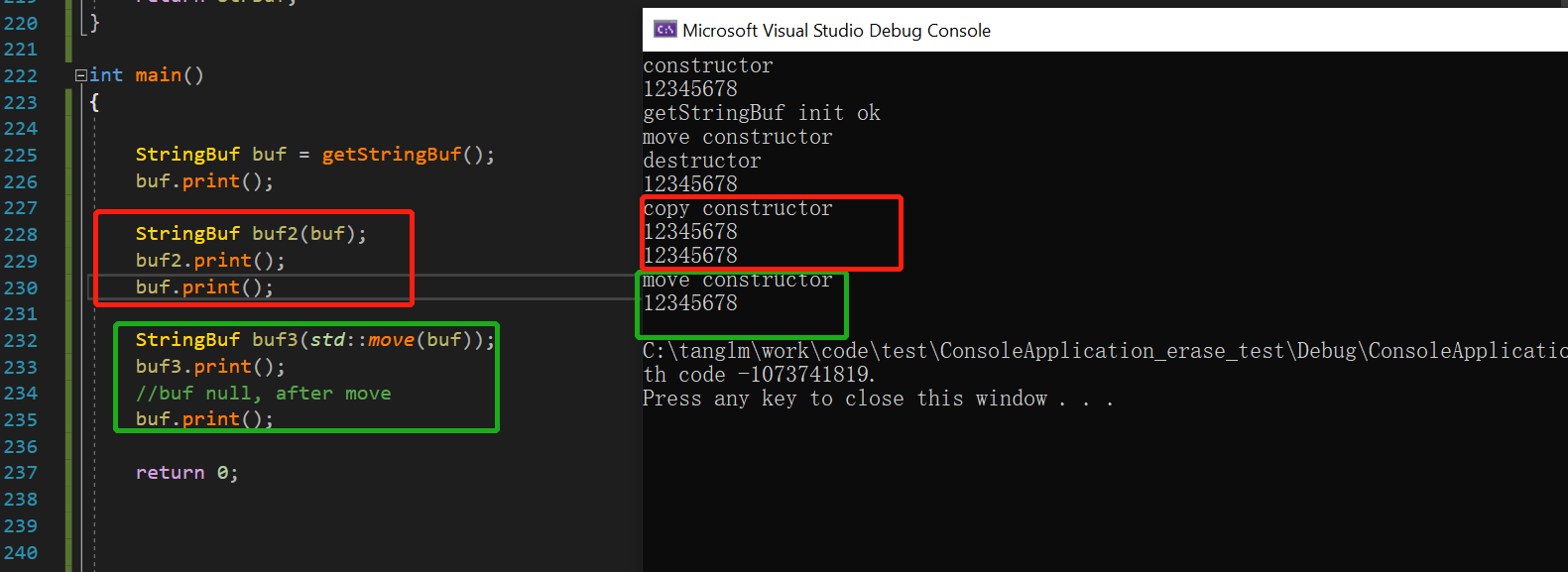
8 . 移动构造std::move
std::move 其实就是将左值强制转换为右值引用,继而我们可以继续通过右值引用使用这个值。而被转换的左值,其声明周期也没有因为转换而变化
static_cast<T&&>(lValue)
使用场景:
假如是个左值,如成员变量为指针或者引用,没有使用右值,通过左值构造对象或者传递参数,就会进行默认的拷贝构造,多一次析构与创建
但是如果使用std::move转换为右值,进入移动构造,则会减少了一次对象的析构与一次对象的构建。
如下: 使用move转为右值,强行转换进行移动构造
#pragma once #include <utility> class HugeMem { public: HugeMem(int size) :sz(size > 0 ? size:1) { c = new char[sz]; } //移动构造 HugeMem(HugeMem && hm) :sz(hm.sz), c(hm.c) { hm.c = nullptr; } virtual ~HugeMem() { delete [] c; c = nullptr; } private: char *c; int sz; }; class Moveable { public: Moveable() :c(new char[3]),h(1024) { } //强制使用移动构造,如果没有,会进入拷贝构造 Moveable(Moveable && hm) : c(hm.c),h(std::move(hm.h)) { hm.c = nullptr; } virtual ~Moveable() { delete[] c; c = nullptr; } private: char *c; HugeMem h; };
实际上: 程序员在编写移动构造函数的时候,应该总记得使用std::move将类似于指针,文件句柄等资源转为右值进行传参
这样的好处:
1. 如果成员支持移动构造,直接移动构造
2. 如果成员不支持移动构造,那么将接收的还是左值,实现拷贝构造,也不会引起什么大问题。
当类中同时包含拷贝构造函数和移动构造函数时,如果使用临时对象初始化当前类的对象,编译器会优先调用移动构造函数来完成此操作。
只有当类中没有合适的移动构造函数时,编译器才会退而求其次,调用拷贝构造函数。
具体可以参考:string类c++11版本
https://www.cnblogs.com/leehm/p/14321979.html
9. std::forward
背景:
void forwardTest(T t){ run(t);}
如上: 实际执行的是run,forwardTest只是对外包装一层,转发了调用而已。
似乎平常,都是这么写代码的,貌似是透传,但实际却没那么简单,
这中间在参数t传递给run的时候,就进行了一次临时对象的拷贝,尽管功能上实现了转发,但谈不上完美。
所以,通常需要做的是引用类型,引用不会有拷贝的开销,但如果碰上使用右值的地方,就没法使用了,
或者,run接收的是const t,那岂不是要为run重载几个版本?,
如此std::forward登场了
void forwardTest(T&& t){ run(std::forward<t>);}
结合折叠规则和自动推导
如果是左值, std::forward转化为static_cast<T&>(t)
如果是右值, std::forward转化为static_cast<T&&>(t)
总结:
move和forward在实现上差别并不大,都是强转,不过库既然这么设计,也许是为了让不同的名字有对应的用途,以对应将来的扩展
区别就是:move强行转换成了右值,而forward则是保留了原有的左右值,
使用场景:
但需要将一参数直接透传到另一个函数执行时,可以使用std::forward,减少一次对象的拷贝与析构
10. 显示类型转换 explict
c++11之前,explict用来修饰构造函数,显示指定构造函数类型,不能通过隐式转换
class A { publi: A(int i):m_data(i){} private: int m_data; }
没有使用explict,可以有如:A a = 10;隐式转换调用了构造函数。
加入了explic后,就会提示需要显示指定,编译通不过,只能A a(10);
c++11 以后,允许explict用来修饰类型转换操作符()上,意味着,只有通过直接构造或者强制类型转换才成功使用类型.
class B; class A { publi: explict operator B () const {return B();} } void Func(B b); void main() { A a; B b1(a); //直接构造初始化 B b2 = static_cast<B>(a); //强制类型转换 //其它都不行,拷贝构造 B b3 = a; Func(a); }
11. POD
12. 非首先联合体union
c++11之前,联合体成员数据类型有一些限制,比如:自定义的结构体类型若增加了构造函数,则是不允许作为联合体的成员的,
c++11之后,取消了对联合体成员数据类型的限制。标准规定,任何非引用类型都可以作为联合体的成员
需要自己写构造函数初始化一些带有构造函数的类成员。(默认的构造函数会被删掉)
13. inline namespace, 解决父子命名空间的繁锁
14. 使用using定义类型的别名,类似typdef
typedef unsigned int UINT
using UINT = unsigned int
15. 右 > 的改进
c++11之前,实例化模板类遇到两个>中间需要加空格,避免编译错误,因为会被当做右移>>
如:vector<vector<int> > vec
c++11后,没有了,不会报错,自动匹配解析了。
为了避免与右移动重复,真正右移动的时候,建议(不是强制)加括号避免被解析出错如:(3>>2)
16. typeid
c++11之前,就支持RTTI运行时类型识别,RTTI为每个类型生成type_info,typeid(类型)可以返回变量的类型type_info信息数据
而type_info.name()成员函数就可以返回类型的名字。
C++11之后,新增了hash_code()这个成员函数,返回类型的唯一hash,用于类型的比较=====C#有点像
17. auto与decltype
c++11新增的自动类型推导
auto从变量推导:
如:auto i=10;
不能使用auto四种情况:
1. func函数,auto不能作为形参
2. 结构体,非静态成员变量,不能为auto
3. 声明auto数组
4. 实例化模板的时候,不能使用auto,如std::vector<auto> v = {1};
decltype从表达式推导:
如:auto a = 10, b = 20;
decltype(a + b) c = 10; c的类型与a+b一样
decltype规则:decltype(e)
1. 如果e是不带括号的标记符表达式或者类成员访问表达式,那么decltype(e)就是e所命名的实体类型, e不能是被重载的函数
2. 假设e的类型是T,如果e是将亡值,则decltype(e) = T&&
3. 假设e的类型是T,如果e是左值,则decltype(e) = T&
4. 假设e的类型是T,则decltype(e) = T
最容易迷糊的是1和3,来我们看:
int i = 0;
decltype(i) a; ===规则1, i不带括号,就是i,int
decltype( (i) ) a ===规则3, i带括号,(i)不是一个表达式,确是一个左值可以取地址,因此是 int&
解释一下1中的标记符表达式:
基本上除去所有关键字,字面量等编译器标记的之外,所有自己定义的变量都是,成员变量也是
如: int arry[10];
int *prt = nullptr;
Struct S {double d;}s;
像array,prt,s.d都是,而类似a+b这种则不是,得归到规则4种。
decltype与auto不同的是:
auto不能带带走cv修饰符即:const/volatile
decltype是能带走的,即没法继承cv修饰符,被去掉了。
18. 追踪返回类型:自动推导返回值
解决泛型种如下问题:比如需要泛型返回值,自动推导,下面会编译不过,因为不认识t1和t2
template<typename T1, typename T2> decltype(t1 + t2) Sum(T1 t1, T2 t2){ return t1 + t2; } //c++11之后:返回值后置 auto Sum(T1 t1, T2 t2) -> decltype(t1 + t2) { return t1 + t2; } 如: old: int func(char *a, int b); new: auto func(char *a, int b)->int;
19. for循环
int array = {1,2,3}; for(auto i : array) {}
20. enum
c++11以前: enum的变量全局的,容易混,容易污染
如: enum Type{General, Light, Medium, Heavy}
enum Category {General, Pisotol, MachineGun, Cannon }
General有重复,需要自己加命名空间,加类封装等等
c++11 强类型枚举: enum class type name{。。。}
如: enum class char C {c1 = 1, c2= 2}
enum class int D {D1 = 1, D2 = 2, Dbig = 0xFFFF}
使用: C:c1 D:D1
加上了名称,强作用域,隔开,type可以为wchar_t的任意类型。
21. 智能指针
1. unique_ptr 看名字,独占的指针, 从实现上看,是一个删除了拷贝构造,保留了移动构造的指针封装
std::unique_ptr<int> p1(new int(11));
std::unique_ptr<int> p2 = p1; //编译不过,独占,不能被复制
std::unique_ptr<int> p3 = std::move(p1); //唯一,可以移动构造,完了之后,p1失效
2. share_prt 看名字,共享指针,有引用计数,只要有赋值,就是++,到0后自动删除
3. weak_ptr 不会增加引用技术,通过lock返回share_ptr,如果无效,返回空,交叉引用使用,父->子,share,子->父 weak, 避免相互,无法释放,内存泄漏。
share_ptr<int> sp(new int(11)); //计数1
weak_ptr<int> wp = sp// 计数1,不增加
share_ptr<int> sp1 = wp.lock() //转化为share,如果sp已经被删除,sp1为空
22. constexptr
由constexptr修饰的变量就是所谓的常量表达式值。
c++11中, constexptr是不能修饰自定义的变量的。
const int i = 10; //常量表达式
constexptr int j = i; //常量表达式值
二者大部分没啥区别,有一点:
如果i在全局声明,则编译器一定会为i产生数据。
而对于j,只要没有代码显示使用j的地址,编译器可以不为其产生数据,而仅仅作为编译数据
23. 变长模板,变长函数/参数
24. 多线程
std::thread, lock_guard, mutex, condition_variable
std::lock_guard
std::unique_lock
1. 正常情况,为了省去手动的lock/unlock,采用lock_guard包装,即可打到加锁保护的目的
std::lock_guard<std::mutex> lk(mQueMutex);
2. 线程在wait的时候,就得使用unique_lock,不能使用lock_guard
std::unique_lock<std::mutex> lk(mQueMutex);
mQueCondVar.wait_for(lk, std::chrono::milliseconds(10));
理由:
std:lock_guard中无法暂时释放锁和加锁,而unique_lock可以临时释放锁,枷锁
wait过程需要临时释放锁,如果一直锁着不释放,会永远无法捕捉变量得更新
std::recursive_mutex
std::mutex
1. 正常情况,mutex配合上述lock,直接使用
2. 同一个线程,重复加锁,使用mutex则会导致死锁,此时就需要使用std::recursive_mutex
recursive_mutex 递归锁
可以允许一个线程对同一互斥量多次加锁,解锁时,需要调用与lock()相同次数的unlock()才能释放使用权
如下也可行:std::lock_guard<std::recursive_mutex>
condition_variable
m_cv.notify_one();
std::unique_lock<std::mutex> lk(m_mtx);
m_cv.wait_for(lk, std::chrono::seconds(5));
lk.unlock();
互斥量可以保护共享数据的修改,如果线程正在等待共享数据的某个条件出现,仅用互斥量的话就需要反复对互斥对象锁定解锁,以检查值的变化,这样将频繁查询的效率非常低。
条件变量可以让等待共享数据条件的线程进入休眠,并在条件达成时唤醒等待线程,提供一种更高效的线程同步方式。
条件变量一般和互斥锁同时使用,提供一种更高效的线程同步方式。
原子类型: atomic_bool, atomic_int,......
内存顺序: memory_order_relaxed...
c++11中,所有的原子操作都可以使用memory_order作为一个参数
int t = 1;
atomic<int> a;
a.store(1, memory_order_relaxed);
25. 线程局部存储
====c++11只做了语法统一,没有性能的规定
int thread_local errorCode;
一旦声明thread_local类型变量,其值从线程开始初始化,结束后不在有效。
如:两个线程T1,T2。
1. 每个定义一个全局errorCode,各自为战
2. 定义一个全局的errorCode,到底是哪个报的error,无法确定
26. nullptr
从0到NULL, 再从NULL到nullptr
27. 类的默认函数: 五大函数+析构
1. 构造
2. 拷贝构造
3. 移动构造
4. 拷贝赋值(operator =)
5. 移动赋值
6. 析构
具体可以参考:string类c++11版本
https://www.cnblogs.com/leehm/p/14321979.html
28. ==default和==delete
29. lambda表达式
30. std::function和std::bind
类模版std::function是一种通用、多态的函数封装。简而言之就是将c时代的函数指针等包装成可调用对象形式。
包括:普通函数、Lambda表达式、函数指针、以及其它函数对象等。
std::function对象是对C++中现有的可调用实体的一种类型安全的包裹(我们知道像函数指针这类可调用实体,是类型不安全的)。
std::function是一个函数对象类,它包装其它任意的函数对象,被包装的函数对象具有类型为T1, …,TN的N个参数,并且返回一个可转换到R类型的值。
std::function使用模板转换构造函数接收被包装的函数对象;特别是,闭包类型可以隐式地转换为std::function
注意:封装类的成员函数的时候,就需要使用std::bind来进行对象转换了
例:
1 //声明一个模板 2 typedef std::function<int(int)> Functional; 3 4 5 //普通函数 6 int TestFunc(int a) 7 { 8 return a; 9 } 10 11 //Lambda表达式 12 auto lambda = [](int a)->int{return a;}; 13 14 //functor仿函数 15 class Functor 16 { 17 public: 18 int operator() (int a) 19 { 20 return a; 21 } 22 }; 23 //类的成员函数和类的静态成员函数 24 class CTest 25 { 26 public: 27 int Func(int a) 28 { 29 return a; 30 } 31 static int SFunc(int a) 32 { 33 return a; 34 } 35 }; 36 37 38 int main(int argc, char* argv[]) 39 { 40 //封装普通函数 41 Functional obj = TestFunc; 42 int res = obj(0); 43 cout << "normal function : " << res << endl; 44 45 //封装lambda表达式 46 obj = lambda; 47 res = obj(1); 48 cout << "lambda expression : " << res << endl; 49 50 //封装仿函数 51 Functor functorObj; 52 obj = functorObj; 53 res = obj(2); 54 cout << "functor : " << res << endl; 55 56 //封装类的成员函数 57 CTest t; 58 obj = std::bind(&CTest::Func, &t, std::placeholders::_1); 59 res = obj(3); 60 cout << "member function : " << res << endl; 61 62 //封装类static成员函数 63 obj = CTest::SFunc; 64 res = obj(4); 65 cout << "static member function : " << res << endl; 66 67 return 0; 68 }
实际项目:
如:c++ rabbitmq操作库:amqpcpp
其中有个event声明,如下:
注意,要使用c++11生效,编译库的时候需要修改makefile加上std=c++11
///////////////////////////////////// void addEvent( AMQPEvents_e eventType, int (*event)(AMQPMessage*) ); #if __cplusplus > 199711L // C++11 or greater void addEvent( AMQPEvents_e eventType, std::function<int(AMQPMessage*)>& event ); #endif virtual ~AMQPQueue(); /////////////////////////////////////
调用的时候,c方式:
//自定义回调
int onMessage(AMQPMessage* message) {...} queue->addEvent(AMQP_MESSAGE, onMessage);
c++方式:
如果还是按照上面c的方式调用,会报编译错误
调用方式如下:
使用bind声明好可调用对象,然后再传参
onMessage在类的成员函数里面
//自定义回调
int CMQProcessor::onMessage(AMQPMessage* message) {...} typedef std::function<int(AMQPMessage*)> AMQEVENT; AMQEVENT onMessageEvent = std::bind(&CMQProcessor::onMessage,this, std::placeholders::_1); queue->addEvent(AMQP_MESSAGE, onMessageEvent);
31. 数据对齐:
操作符: alignof() --->查看对齐字节数
struct A{ int a; char c; }; //alignof(A) = 8 说明8字节对齐
对齐描述符: alignas() ---->指定使用几个字节对齐,既可以是类型,也可以是具体数值
struct alignas(4) A{ int a; char c; }; //使A按4字节对齐 //alignas(double)和alignas(8)一样, //stl:std::align等
32. unicode支持,常见的由UTF-8, UTF-16,UTF-32
Windows UTF-16
linux/mac UTF-8
UTF-8:变长编码unicode,英文通常1字节表示,与ASCII码兼容,
中文采用3字节,省空间,一个汉字就是 3+‘\0’= 10字节, 没有大小端问题。 没有u8string,需要函数与多字节转换
UTF-16:定长编码, 由字节序问题,LE和BE版本 有u16string,u32string,方便操作
c++11前: wchar_t表示,Windows下被实现位16位宽,理论长度可以为8位,16位,32位,
这样各个平台不一致,难以移植
c++11后: char16_t 16字节, 存储UTF-16编码的unicode数据
char32_t 32字节, UTF-32
char 8字节, UTF-8,
各个平台统一。
增加前缀来表示unicode字符
u8 UTF-8 u8"123"
u UTF-16 u“ab”
U UTF-32 U"唐"
之前的 L 表示宽字符wchar_t,四种前缀
L“123456”
普通的就不用加,默认的 “123456”
33. 原生字符串的支持 R
所见即所得,不转义,看见的就是输入的
cout << R("hello \n world") << endl;
输出:
hello \n world
\n没有转义,是什么就输出什么。
unicode u8R, u16R, u32R也一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号