

数据库优化学习笔记_主从分离(主改从查)
查询分离
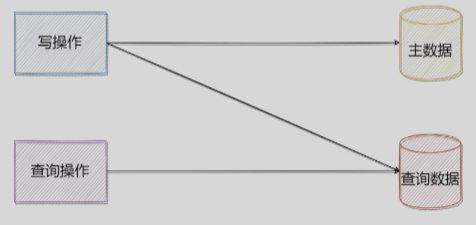
适用场景:1.数据量大 2.所有数据都需要写 3.无法分离冷热数据 4.即使是冷数据,依然要读写保持更新因此没法冷热分离
查询分离从三个方式去建设:
1)同步建立
2)异步建立
3)binlog方式
1)同步建立:
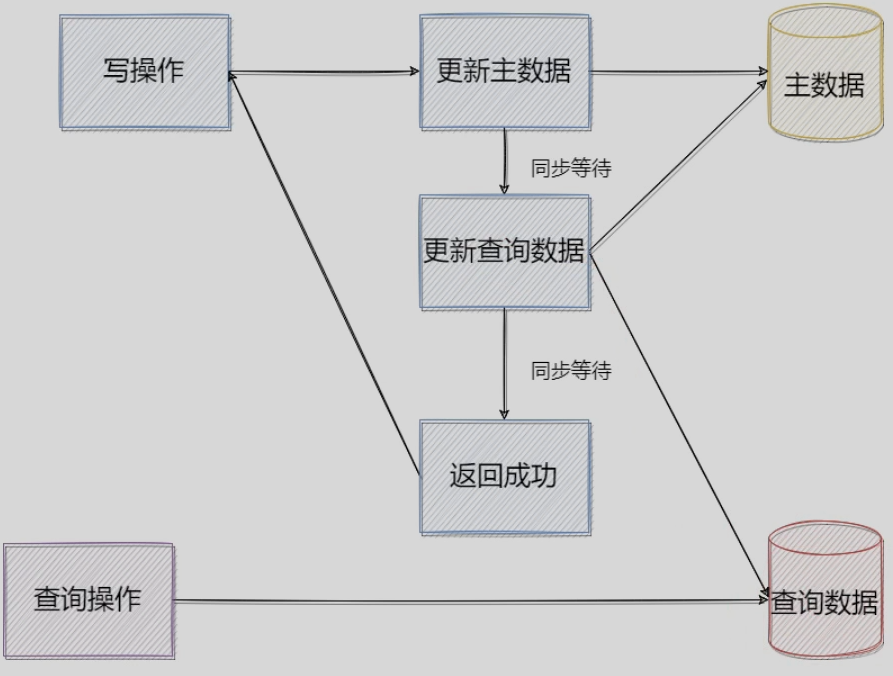
优点:可以一定程度上保证主从数据的一致性,可以从库容灾。(也可以MQ建立)
缺点:更新数据的时候要等待从库备份回应,数据更改的效率会变低,减缓了效率。
2)异步建立:
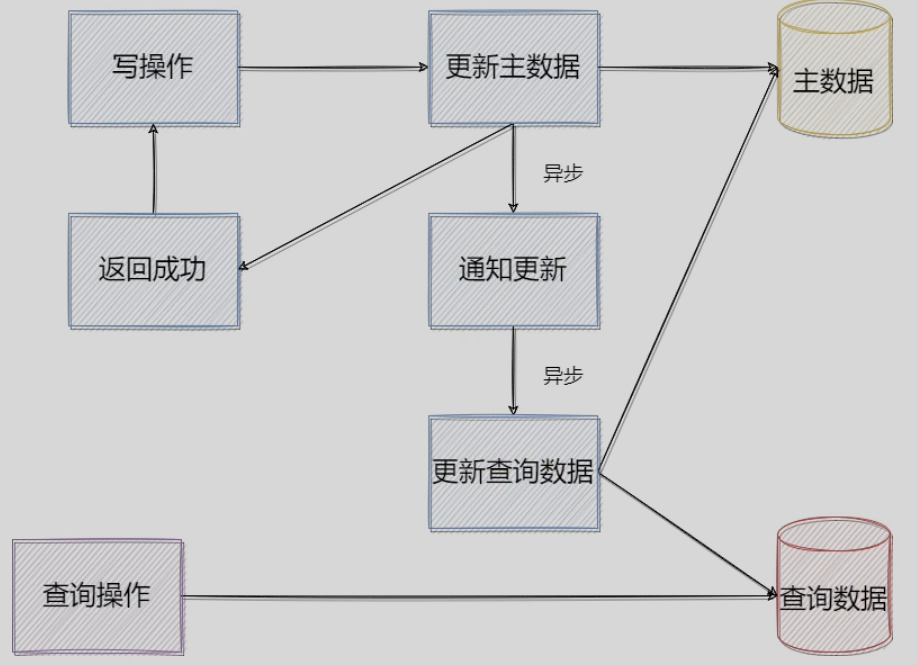
优点:不会影响我们在改数据的时候的效率,容灾
缺点:万一备份宕机/从库过程失败?数据一致性会存在问题。解决方法可以从Kafka的容灾机制去理解(partition分布式备份,选举leader,值得学习)
3)binlog方式(主流方式)
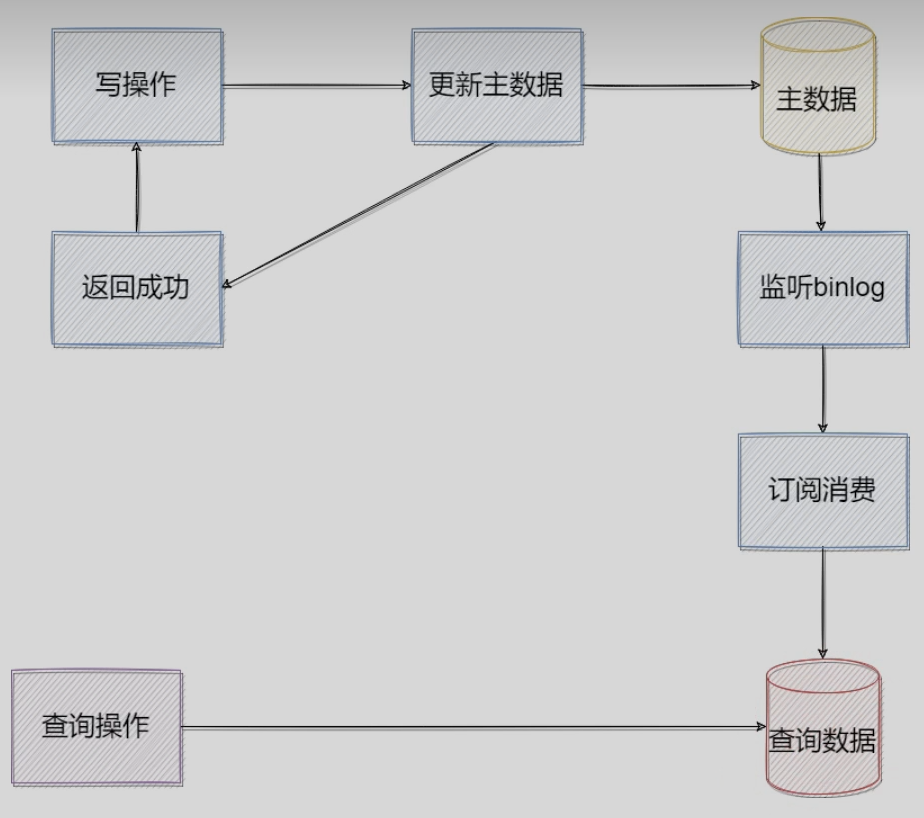
可以利用Canal去实现(如果主数据库就是MySQL的话用Canal容灾/备份/日志收集应该是够用的)
思考:
Q:MQ宕机了怎么办?那就意味着搬运的数据的一致性出现问题(生产者向MQ中搬运了一条数据,此时MQ宕机了,生产者以为消费者消费了,就不往MQ中搬运消息,但是由于MQ宕机了导致消费者没有收到)
A:可以往数据中加入一个标记字段,对数据本身没有任何影响,比如NeedUpdateData=1。生产者把数据批量注入MQ后把NotNeedUpdateData=1,消费者去消费时先批量查询数据然后更新,把NotNeedUpdateData=1,然后把MQ中的数据和消费者中的数据进行 ⊕运算 ,从而保证消息是否被消费 (也可以参照kafka的事务机制来保证数据一致性)
Q:消息的时序性问题?

某个订单 A 更新了 1 次数据变成 A1,线程甲将 A1 的数据搬到查询数据中。不一会儿,后台订单 A 又更新了 1 次数据变成 A2,线程乙也启动工作,将 A2 的数据搬到查询数据中。如果甲线程更新比乙线程快,那么
数据是正确的,那么如果甲线程堵塞了导致比乙线程慢,那么会出现先是更新成A2然后甲线程恢复后更新变成了过期的A1!
A:每次更新都保存上次更新的时间 LastUpdateTime,然后每个线程更新查询数据后,检查当前订单 A 的 LastUpdateTime 是否跟线程刚开始获得的时间一样,且 NotNeedUpdateData 是否等于 0?,如果都满足的话,我们就将 NotNeedUpdateData 的值改为 1 ,然后再做一次搬运。
Q:消息的幂等问题?(幂等就是指多次操作和一次操作是一致的 f(x)=f(f(x)) )
A:主数据的订单 A 更新后,我们在查询数据中插入了 A,此时系统出问题了,系统误以为查询数据没更新,又把订单 A 插入更新了一次。
所谓幂等,就是不管更新查询数据的逻辑执行几次,结果都是我们想要的结果。因此,考虑消费端并发性的问题时,我们需要保证更新查询数据幂等。
主从分离的不足:
1)主数据量越来越大后,写操作还是慢,到时还是会出问题。
2)主数据和查询数据不一致时,业务逻辑需要查询数据保持一致性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· Qt个人项目总结 —— MySQL数据库查询与断言