

数据库优化学习笔记_冷热分离
冷热分离
当数据库表数据体量大,即使是做了很多SQL层面的优化(索引、执行计划、优化语句、表结构设计)读写依然很慢可以考虑从冷热数据分离去提高速度
热数据:对用户而言,是需要经常用到的数据。从数据获取后需要快速反应面向用户/系统使用,数据需要保持质量和稳定、有效。
在数据处理层面上也是优先的。
比如:在订单系统中,还未完成的订单中的数据可以认为是热数据,及时反应给用户/系统作查询比对处理
冷数据:不是经常用到的。也可以是历史数据,对业务进度影响不大,可以用做离线处理的数据。
比如:订单中已经完成的数据,我们需要对订单数据做聚合统计,订单庞大,统计分析时间长,但是无需给用户做出立刻的反应。
冷热分离:冷数据和热数据的最终形态(通过一系列业务处理后)存放在冷库和热库中,分别存储。
注意:
冷热分离数据的特效有:
1) 如果一个数据被标记为冷数据,我们可以认为:我们不会对它再进行业务操作(UPDATE、DELETE操作)
2) 不会同时的对冷热数据进行读取操作
冷热分离确实可以在某种程度上解决写读写数据慢的问题,但是仍然存在诸多不足。具体表现有:
1)用户查询冷数据速度依旧很慢。
2)由于冷数据多到一定程度,业务就无法再修改冷数据,因为数据量太大系统承受不住。
实现方案1:修改业务代码
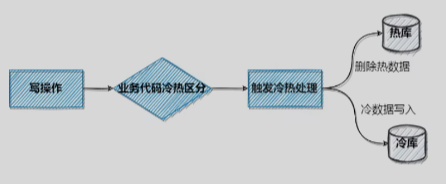
在业务层就去判断冷热数据,触发分离,可以使用触发器等。(同步/异步根据业务逻辑进行具体考量)
比如TIMESTAMPDIFF某个字段到现在已经有一定的时间了,可以认为他是冷数据,我们就从热库中删除,在冷库中写入,
从而减少了热库的数据量。但缺点就是需要不断的运行维护,对代码的侵入性比较高。
实现方案2:CDC(Change Data Capture 变更数据获取)
监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等)
将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
基于查询的CDC:Sqoop、Kafka JDBC source等(后面学习)
基于Binlog的CDC:Canal、Debezium等
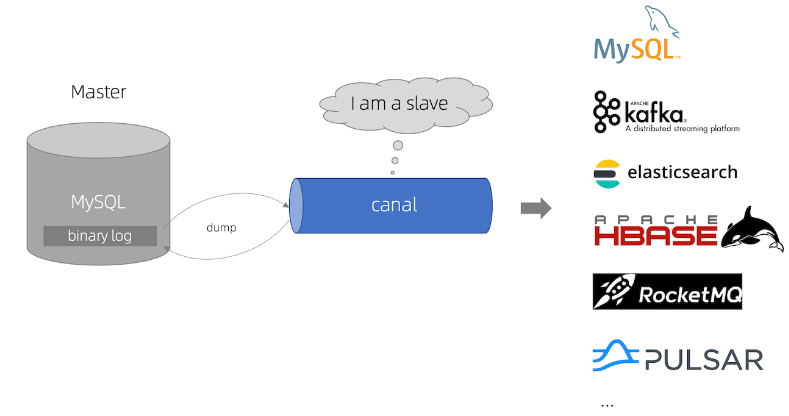
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力(主要用于解决异构通信问题)。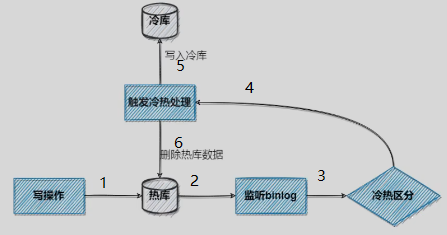
MySQL主备复制原理
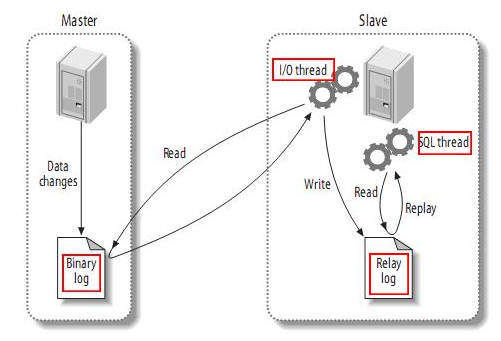
Mysql的Master将数据变更写入binlog,Slave就将binlog拷贝到Slave的中继日志relaylog,通过relaylog同步做到主从备份
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
实现方案3:定时任务扫描
通常使用Springboot的Quartz 或者 Python的Schedule库写脚本,来对库表数据进行定时扫描和处理,
当条件满足后做数据状态的变更或者产生新的数据插入到表中。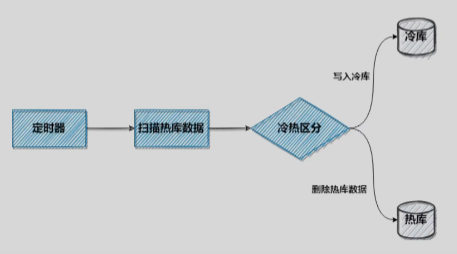
这个有很多考量,值得后面再去应对业务深挖。
总结:解决读写缓慢冷热分离是个有效的手段,但是数据一致性如何保证也是一个问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· Qt个人项目总结 —— MySQL数据库查询与断言