SNIP
转自:https://zhuanlan.zhihu.com/p/67080514
An Analysis of Scale Invariance in Object Detection - SNIP
这篇论文主要通过改进的Multi-Scale Training的方式来解决“尺度不变性”的问题,我们先来分析当前算法在处理尺度不变性时的一些方法及其缺点,再来介绍这篇论文的核心思想,最后对这篇论文的一些实验细节进行分析。
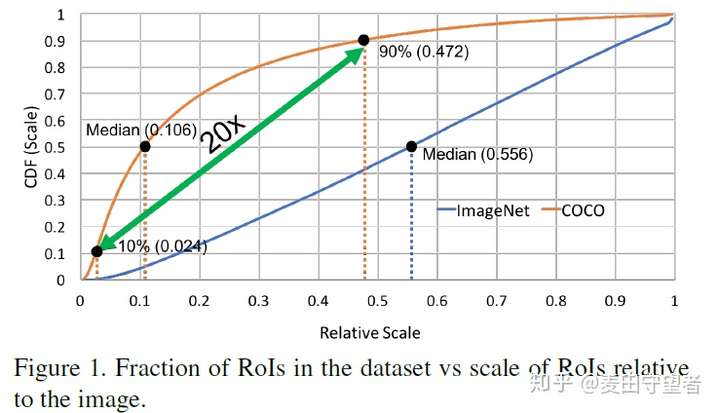
- 存在的问题
- 数据集分布差异:COCO图像中存在大量的小物体,大物体和小物体之间size差距可达20倍之多,这使得COCO数据集和ImageNet数据集的物体的尺寸分布很不一样,ImageNet为224×224的图像,其物体的中位数的尺寸为图像尺寸的一半,基本上不会太小也不会太大,且位于图像中心。所以COCO数据集所面临的问题是如何能够同时对物体尺寸跨度范围较大的场景进行目标检测,这就需要一个检测器能够不管一个物体的尺寸是16×16还是800×800,都能够准确地捕获到其特征并进行准确的分类和定位。
- Domain shift:ResNet等在ImageNet的224×224上预训练的模型,需要在COCO数据集上fine-tune,由于第一点提到的COCO数据集与ImageNet数据集的物体大小分布的差异,就使得fine-tune过程存在domain-shift的问题。预训练的ResNet是用于处理224×224的图片的物体的,其网络权重对于COCO这种存在非常多小物体的数据集并不适用,换句话说就是其网络权重无法作为一个很好的初始特征提取器,从而无法达到很好的fine-tune的效果,如果ResNet预训练和fine-tune的数据集的物体尺寸分布一致,那么则效果是最好的。
- 网络结构不适配:因为COCO数据集中存在大量的小物体,而ResNet的网络结构存在多次下采样(5次),这样像25×25这样大的小物体在网络32倍下采样后,其特征便会消失,网络顶层特征只保留了图像的主要特征,比如大物体的,这样原始的ResNet网络结构就不适用于对小物体的检测。而通常就解决对小物体的检测的方法就是对原图进行上采样,这样可以增大小物体的分辨率,从而使其适应ResNet的下采样的倍数,但是这样的对原图放大之后,原图中所有物体都会被放大,大物体会变得更大,从而使得网络对大物体的检测性能下降。也就是说“upsample利于small objects却不利于large objects,ori image利于large objects却不利于small objects”,而一个网络结构又无法同时适用于小物体和大物体。
- 训练和测试尺寸不匹配的问题:一般会在800×1200上训练(由于GPU显存限制),而在1400×2000上测试,但是训练和测试尺寸不匹配显然不是最优解。在800×1200上训练,由于"each object instance appears at several different scales and some of those appearances fall in the desired scale range",在1400×2000测试时,800×1200图像上的所有objects都会变大,其中的small objects变大后的尺寸仍在800×1200图像中相应类别的尺寸范围,而800×1200中那些原本较大尺寸的物体在1400×2000中会变得非常大,以至于训练和测试的尺寸发生不一致的现象,所以在1400×2000对小物体精度会有提升,但是对于非常大的物体的检测可能不利,没有办法兼顾所有尺寸的物体。即使使用Multi-Scale Test,合并所有尺寸的测试结果,但是由于训练时(不管是Signle Scale Training还是Multi-Scale Training),由于物体尺寸跨度范围较大的原因,每次都对所有一张图的所有物体进行训练,总有物体的尺寸与该网络不适配,从而不利于网络的训练或者说需要网络消耗一部分capacity来强行记住这些不同的尺寸(在感受野极度不匹配的情况下),这显然不能达到很好的训练效果。所以论文中即使使用1400×2000训,然后1400×2000测,但是精度提升也很有限,因为虽然小物体尺度增加,其特征不会消失,但是大物体检测更加困难且不利于训练,网络需要分出一部分capacity来对多尺度特征进行记忆(参见王乃岩的解释【https://zhuanlan.zhihu.com/p/36431183】)。
- 本文的动机
- 以上存在的问题,我们会产生一些疑问需要进行实验验证。是否对原图进行上采样真的有利于小物体的检测?比如把原图480×640的图片放大至800×1200。由于前面第3点中的网络结构不适配的这个矛盾的存在,我们是否可以针对不同尺寸的物体训练不同的检测器(scale specific detector)?比如先将ImageNet上的224×224的图片缩小,调小ResNet的stride,然后在低分辨率的图片上训练得到适合小物体的预训练模型,然后再在COCO数据集上fine-tune,这样就解决了domain-shift的问题,且是专门为小物体设计的网络结构,从而可以提升小物体的检测精度。
- scale specific detector或许太过麻烦而且会使得每个检测器的训练样本急剧下降,从而不能达到理想的效果。那么我们是否可以创建一个scale invariant detector,即对于一个upsample后的image,我们只训练其中“尺寸在64×64~256×256范围内的物体”,这样是否可以达到很好的效果(其实这就是本文SNIP的思路)?而传统的方法,对upsample到任意尺寸的image,我们都对该image中所有物体进行训练,这样效果又是否好呢?
- 传统的scale invariant detector就是对一个检测器进行Multi-Scale Training/Multi-Scale Testing,这样虽然在训练时由于对图像resize从而扩充了样本数目,但是这样更加剧了网络学习的困难,即会“增大原始数据集的物体的尺寸跨度范围”,而且要强行让网络学习到一个卷积核能够对尺度跨度范围如此之大的物体特征的提取;并且同一个网络的多尺度训练,必然会因为网络结构不适配的问题,使得“网络每次迭代或者说梯度更新时,必然无法顾及所有物体,即每次只有图像中部分物体能够被分类的很好,其余物体会由于感受野的问题对训练造成不利的影响”;以往方法寄希望于在数据充足的情况下使用一个大网络来强行记住“larget variations in scale”从而完成对不同尺度物体的检测,这样势必会浪费很多network capacity在处理“scale variance”上。
- 我们所希望的是能够同时解决上述存在的4大问题:在COCO数据集上训练时,最好只训练和ImageNet数据集尺寸一致的物体,这样可以避免domain shift带来的问题;网络仅对给定跨度较小的尺寸范围内的物体进行学习,这样就解决了网络结构不适配的问题,因为物体尺寸固定,这样就可以用一个网络结构来学习,即选择适合该尺寸的感受野,“一个物体尺寸,一个网络,一种感受野,这3者相互匹配,且train和test尺寸一致”效果最好;使用scale invariant detector而非scale specific detector,避免样本过少的问题,也就是只训练一个检测器,但是要用到所有的样本。显然原始的Multi-Scale Training/Testing不具备这些要求,所以需要对MST进行改进。更多关于Multi-Scale Training/Testing的缺点参见“《存在的问题》第4点和《本文的动机》第3点”。
- 现有的解决方案
- Train on 1.5~2x,Test on up to 4x。虽然在大图上训练可以使网络学习到对小物体进行分类(因为放大了,所以小物体的特征会有些许保留,这样利于对小物体的训练),并且增加多个stage以对大物体进行检测。这样做的缺点在“《存在的问题》第4点”中已经叙述,且即使将小物体放大且增加更多的stage,但是仍然无法解决“一个网络结构无法对所有尺寸的物体适配”的问题,即无法保证“能够同时获取所有尺寸的物体的高层语义特征和浅层细节特征”,这似乎是现有网络结构的一个缺陷。
- Dilated/DetNet:为了保证小物体在高层特征图中不至于丢失信息,所以需要“在保证网络感受野的同时,保持特征图的大尺寸”,即不使用下采样这种压缩物体信息的操作,而仅增大感受野,因为不断下采样会使得像25×25大小的小物体的特征在高层消失。而虽然DetNet的大尺寸的特征图保证了小物体的信息,即高层特征图包含了小物体的语义特征,但是Dilated Conv使得高层的感受野较大(因为必须要能够检测大物体),所以高层特征图的每个位置,其都涵盖了原图中较大一部分区域,使得小物体的特征并不精细,试想对于25×25的小物体,DetNet中高层的感受野实在是太大了。所以这就存在“感受野、特征图尺寸、小物体的精细特征”之间的矛盾。我们需要的是,高层特征的感受野与图像中每个物体的尺寸相匹配。
- SSD/MS-CNN:高层特征不含有小物体的信息,所以不同stage的特征图负责处理不同尺度的物体,但是由于回归和分类同时需要一个物体的“语义和位置”特征,所以SSD这种网络结构难以对小物体同时具备这些特征。
- FPN/RetinaNet:这种融合高层和底层特征,在原始Faster R-CNN基础上性能提升了很多,以一个top-down的结构使得每个stage都具备了高层的语义特征,从而解决了SSD的问题,似乎这样就可以在浅层同时获取小物体的位置和语义特征了。但是FPN有一个严重的缺点(在DetNet论文中被提及):高层(P5 in RPN/Head,P5/P6 in RPN)中含有large objects的语义但丢失了large objects的位置信息,所以高层仍然不利于对large objects的定位;高层尺寸较小(32被下采样)导致高层其实并不包含小物体的语义特征,所以即使使用top-down结构,浅层特征图对小物体进行特征提取,但是仍然无法提取到小物体的语义特征(因为诸如25×25的小物体,其特征由于下采样的原因在高层消失了),所以不利于小物体的分类。DetNet通过在stage4之后一直维持感受野不变(即一直是16倍下采样),使得高层特征图可以同时具备大物体和小物体的语义特征和大物体的位置特征。
- Multi-Scale Training/Testing:为了对small、medium、large objects都预测的好,以往都会多尺度训练和测试,这或许是一个好方法,因为训练过程中每个尺寸的物体都被照顾到了,但是也存在一些缺点,参见“《存在的问题》第4点和《本文的动机》第3点”。
- 关于FPN/DetNet的思考:我们都知道网络浅层含有细节信息如位置,高层含有语义信息如类别,ResNet中高层含有大物体的意义特征但是由于分辨率过低而不含有大物体的位置特征,DetNet通过增大高层的分辨率使得高层具有大物体的位置特征,且高层也同时包含小物体的语义特征。所以关于backbone,大物体或者小物体,其语义特征和位置特征分别位于哪一个stage,该stage和“下采样倍数、特征图分辨率、感受野”有和关系,高层有大分辨率可以同时具备大物体的类别信息和位置信息,且也会具备小物体的类别信息,但是否具备小物体的位置信息?一个给定尺寸的物体的类别的信息,应该在较高的stage上,而该物体的位置特征应该位于较低的stage上,但是随着stage的继续增加(继续下采样),该物体的类别特征消失,而如果增加stage却保持分辨率,是否可以同时保持语义和位置特征。也就是说CNN中,各个尺寸的物体的语义和位置特征分辨位于CNN的哪一个stage的特征图上,其和下采样倍数和分辨率有何关系,就像王乃岩说的“是否可以显式地拆分出CNN中对于物体表示的不同因素(semantic,scale等等)【https://zhuanlan.zhihu.com/p/36431183】”。

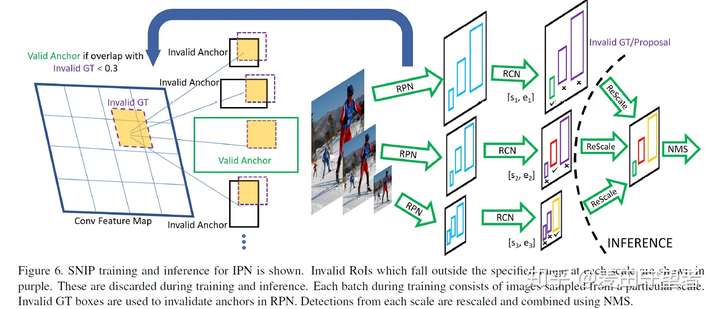
- SNIP
SNIP是对Multi-Scale Training/Test的一种扩展,思路很简单,参考《本文的动机》尤其是第4点,就可以理解SNIP核心要素了。
- 选取3种图像分辨率:(480, 800)训练[120, ∞)的proposals,(800, 1200)训练[40, 160]的proposals,(1400, 2000)训练[0, 80]的proposals
- 对于每个分辨率的图像,BP时只回传在对应尺度范围内的proposals的梯度
- 这样保证了只使用一个网络,但是每次训练的物体的尺寸都是一致的,和ImageNet的物体尺寸一致以解决domain shift的问题,且符合backbone的感受野,且训练和测试尺寸一致,满足“ImageNet预训练尺寸,一种物体尺寸,一个网络,一种感受野,这4者相互匹配,且train和test尺寸一致”
- 一个网络,但却使用了所有的物体训练,相比scale specific detector,SNIP充分利于了数据
- 测试时,同一个detector在3种分辨率的图像上各测一次,并且对于每个分辨率的图像只保留其对应尺度的dtboxes,然后再合并,执行SoftNMS
- 从Image Pyramid层面来解决问题,因为对于“输入尺寸单一,设计一个scale invariant detector”存在着无法解决的矛盾(参见《存在的问题》第4点和《本文的动机》)
- SNIP解决了Multi-Scale Training/Test的缺陷


- 分类网络的实验
- CNN-B:Train on 224×224 original data,Test on up-sampled 48×48、64×64、80×80、96×96、128×128(to 224×224)separately;也就是高清图训练,低清图测试(虽然尺寸一样,但是清晰度不一样),看看“训练和测试尺度不一致会导致怎样的精度的差别”以及可以揭示domain shift问题的解决的重要性。似乎对于需要对于每个尺寸单独训一个分类器
- CNN-S:Train on 48×48,Test on 48×48;Train on 96×96,Test on 96×96。由于图像尺寸改变了,所以需要缩小网络开头的stride和kernel_size。由于测试和训练的尺寸一致,精度提升很多。
- CNN-B-FT:Train on 224×224 original data, fine-tune on up-sampled 48×48(to 224×224),test on up-sampled 48×48(to 224×224);Train on 224×224 original data, fine-tune on up-sampled 96×96(to 224×224),test on up-sampled 96×96(to 224×224)。证明了“upsample small objects”然后训练是有利于对小物体的检测的,且在大物体224×224的预训练模型对于小物体48×48的训练是有帮助的。且比CNN-S精度高,所以无需scale specific detector。从而证明了SNIP的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号