DenseNet
论文:Densely Connected Convolutional Networks
论文链接:https://arxiv.org/pdf/1608.06993.pdf
代码的github链接:https://github.com/liuzhuang13/DenseNet
MXNet版本代码(有ImageNet预训练模型): https://github.com/miraclewkf/DenseNet
文章详解:
这篇文章是CVPR2017的oral,非常厉害。文章提出的DenseNet(Dense Convolutional Network)主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效!众所周知,最近一两年卷积神经网络提高效果的方向,要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception),而作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。博主虽然看过的文章不算很多,但是看完这篇感觉心潮澎湃,就像当年看完ResNet那篇文章一样!
先列下DenseNet的几个优点,感受下它的强大:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,目前很多论文都针对这个问题提出了解决方案,比如ResNet,Highway Networks,Stochastic depth,FractalNets等,尽管这些算法的网络结构有差别,但是核心都在于:create short paths from early layers to later layers。那么作者是怎么做呢?延续这个思路,那就是在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来!
先放一个dense block的结构图。在传统的卷积神经网络中,如果你有L层,那么就会有L个连接,但是在DenseNet中,会有L(L+1)/2个连接。简单讲,就是每一层的输入来自前面所有层的输出。如下图:x0是input,H1的输入是x0(input),H2的输入是x0和x1(x1是H1的输出)……
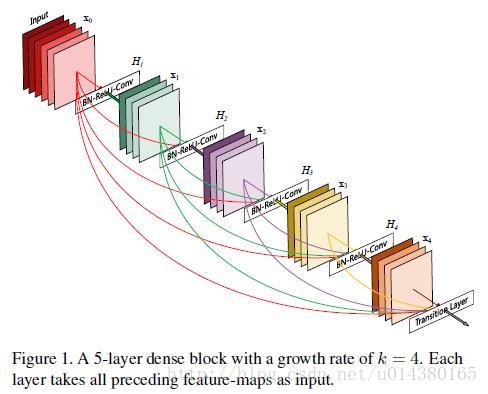
DenseNet的一个优点是网络更窄,参数更少,很大一部分原因得益于这种dense block的设计,后面有提到在dense block中每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。原文的一句话非常喜欢:Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.直接解释了为什么这个网络的效果会很好。前面提到过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。另外作者还观察到这种dense connection有正则化的效果,因此对于过拟合有一定的抑制作用,博主认为是因为参数减少了(后面会介绍为什么参数会减少),所以过拟合现象减轻。
这篇文章的一个优点就是基本上没有公式,不像灌水文章一样堆复杂公式把人看得一愣一愣的。文章中只有两个公式,是用来阐述DenseNet和ResNet的关系,对于从原理上理解这两个网络还是非常重要的。
第一个公式是ResNet的。这里的l表示层,xl表示l层的输出,Hl表示一个非线性变换。所以对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换。
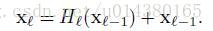
第二个公式是DenseNet的。[x0,x1,…,xl-1]表示将0到l-1层的输出feature map做concatenation。concatenation是做通道的合并,就像Inception那样。而前面resnet是做值的相加,通道数是不变的。Hl包括BN,ReLU和3*3的卷积。
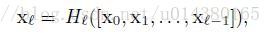
所以从这两个公式就能看出DenseNet和ResNet在本质上的区别,太精辟。
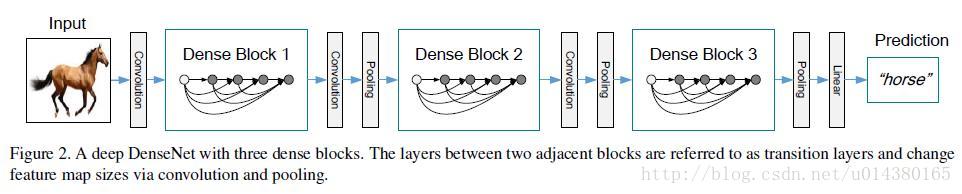
前面的Figure 1表示的是dense block,而下面的Figure 2表示的则是一个DenseNet的结构图,在这个结构图中包含了3个dense block。作者将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
这个Table1就是整个网络的结构图。这个表中的k=32,k=48中的k是growth rate,表示每个dense block中每层输出的feature map个数。为了避免网络变得很宽,作者都是采用较小的k,比如32这样,作者的实验也表明小的k可以有更好的效果。根据dense block的设计,后面几层可以得到前面所有层的输入,因此concat后的输入channel还是比较大的。另外这里每个dense block的3*3卷积前面都包含了一个1*1的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征,何乐而不为。另外作者为了进一步压缩参数,在每两个dense block之间又增加了1*1的卷积操作。因此在后面的实验对比中,如果你看到DenseNet-C这个网络,表示增加了这个Translation layer,该层的1*1卷积的输出channel默认是输入channel到一半。如果你看到DenseNet-BC这个网络,表示既有bottleneck layer,又有Translation layer。
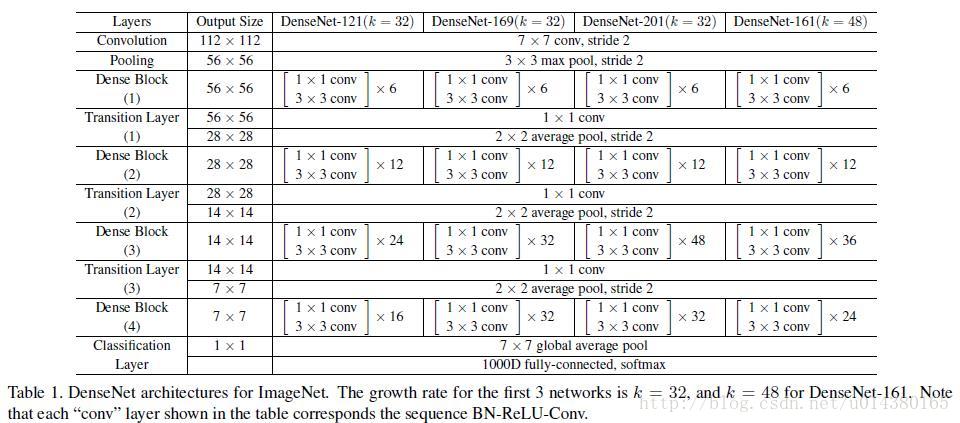
再详细说下bottleneck和transition layer操作。在每个Dense Block中都包含很多个子结构,以DenseNet-169的Dense Block(3)为例,包含32个1*1和3*3的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),那么如果不做bottleneck操作,第32层的3*3卷积操作的输入就是31*32+(上一个Dense Block的输出channel),近1000了。而加上1*1的卷积,代码中的1*1卷积的channel是growth rate*4,也就是128,然后再作为3*3卷积的输入。这就大大减少了计算量,这就是bottleneck。至于transition layer,放在两个Dense Block中间,是因为每个Dense Block结束后的输出channel个数很多,需要用1*1的卷积核来降维。还是以DenseNet-169的Dense Block(3)为例,虽然第32层的3*3卷积输出channel只有32个(growth rate),但是紧接着还会像前面几层一样有通道的concat操作,即将第32层的输出和第32层的输入做concat,前面说过第32层的输入是1000左右的channel,所以最后每个Dense Block的输出也是1000多的channel。因此这个transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。文中还用到dropout操作来随机减少分支,避免过拟合,毕竟这篇文章的连接确实多。
实验结果:
作者在不同数据集上采用的DenseNet网络会有一点不一样,比如在Imagenet数据集上,DenseNet-BC有4个dense block,但是在别的数据集上只用3个dense block。其他更多细节可以看论文3部分的Implementation Details。训练的细节和超参数的设置可以看论文4.2部分,在ImageNet数据集上测试的时候有做224*224的center crop。
Table2是在三个数据集(C10,C100,SVHN)上和其他算法的对比结果。ResNet[11]就是kaiming He的论文,对比结果一目了然。DenseNet-BC的网络参数和相同深度的DenseNet相比确实减少了很多!参数减少除了可以节省内存,还能减少过拟合。这里对于SVHN数据集,DenseNet-BC的结果并没有DenseNet(k=24)的效果好,作者认为原因主要是SVHN这个数据集相对简单,更深的模型容易过拟合。在表格的倒数第二个区域的三个不同深度L和k的DenseNet的对比可以看出随着L和k的增加,模型的效果是更好的。
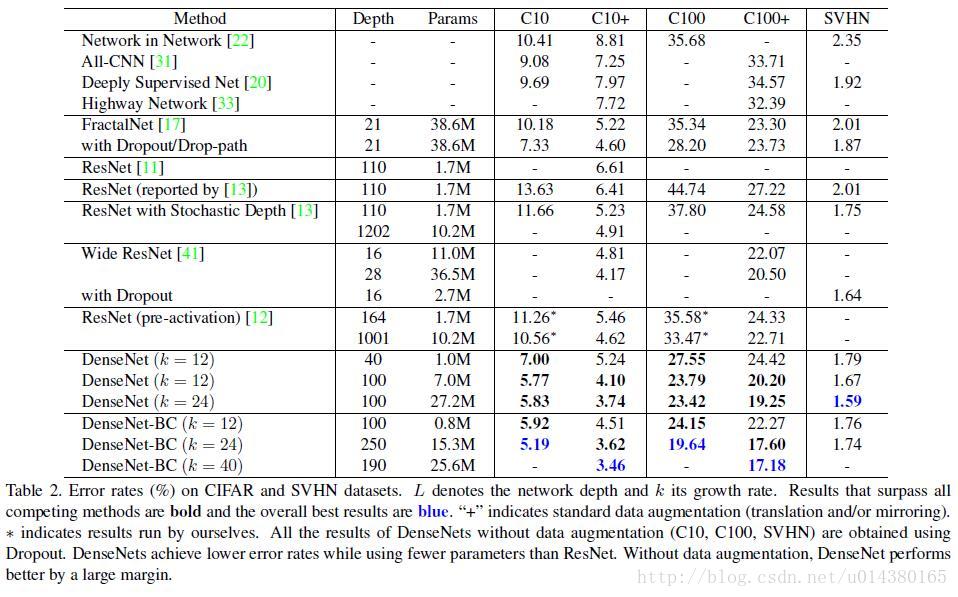
Figure3是DenseNet-BC和ResNet在Imagenet数据集上的对比,左边那个图是参数复杂度和错误率的对比,你可以在相同错误率下看参数复杂度,也可以在相同参数复杂度下看错误率,提升还是很明显的!右边是flops(可以理解为计算复杂度)和错误率的对比,同样有效果。
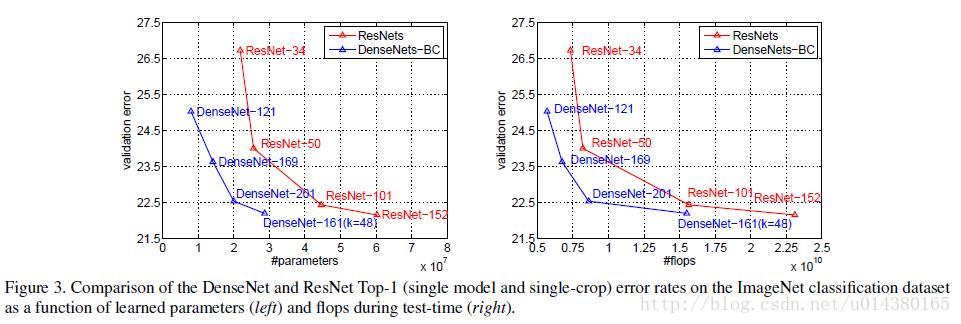
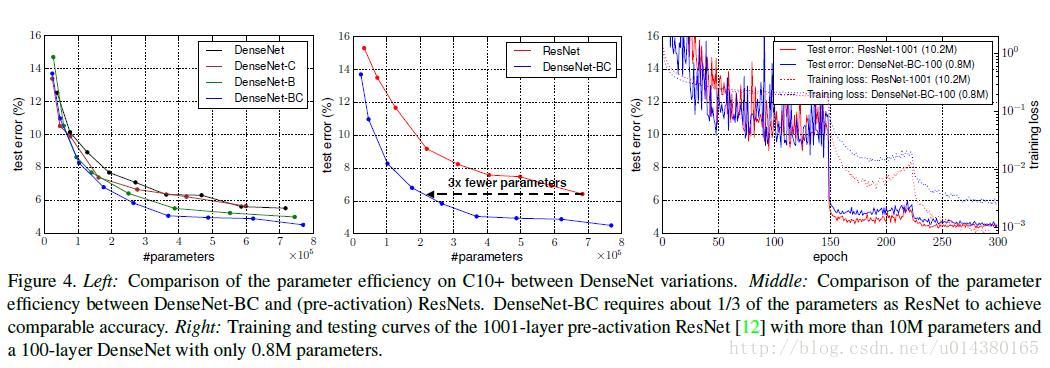
Figure4也很重要。左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果。
另外提一下DenseNet和stochastic depth的关系,在stochastic depth中,residual中的layers在训练过程中会被随机drop掉,其实这就会使得相邻层之间直接连接,这和DenseNet是很像的。
总结:
博主读完这篇文章真的有点相见恨晚的感觉,半年前就在arxiv上挂出来了,听说当时就引起了轰动,后来又被选为CVPR2017的oral,感觉要撼动ResNet的地位了,再加上现在很多分类检测的网络都是在ResNet上做的,这岂不是大地震了。惊讶之余来总结下这篇文章,该文章提出的DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号