Inception Module-深度解析
转自:https://zhuanlan.zhihu.com/p/32702031
inception(也称GoogLeNet)是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
inception原文链接:https://arxiv.org/pdf/1409.4842.pdf
一、核心思想
inception模块的基本机构如下图,整个inception结构就是由多个这样的inception模块串联起来的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
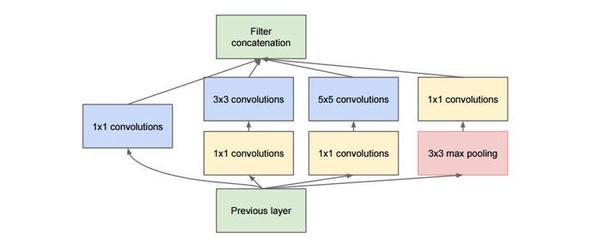
1、1x1卷积
可以看到图1中有多个黄色的1x1卷积模块,这样的卷积有什么用处呢?
作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。这个观点来自于Network in Network(NIN, https://arxiv.org/pdf/1312.4400.pdf),图1里三个1x1卷积都起到了该作用。
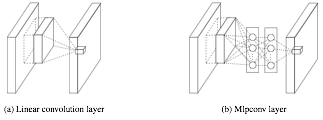
图2左侧是是传统的卷积层结构(线性卷积),在一个尺度上只有一次卷积;右图是Network in Network结构(NIN结构),先进行一次普通的卷积(比如3x3),紧跟再进行一次1x1的卷积,对于某个像素点来说1x1卷积等效于该像素点在所有特征上进行一次全连接的计算,所以右侧图的1x1卷积画成了全连接层的形式,需要注意的是NIN结构中无论是第一个3x3卷积还是新增的1x1卷积,后面都紧跟着激活函数(比如relu)。将两个卷积串联,就能组合出更多的非线性特征。举个例子,假设第1个3x3卷积+激活函数近似于f1(x)=ax2+bx+c,第二个1x1卷积+激活函数近似于f2(x)=mx2+nx+q,那f1(x)和f2(f1(x))比哪个非线性更强,更能模拟非线性的特征?答案是显而易见的。NIN的结构和传统的神经网络中多层的结构有些类似,后者的多层是跨越了不同尺寸的感受野(通过层与层中间加pool层),从而在更高尺度上提取出特征;NIN结构是在同一个尺度上的多层(中间没有pool层),从而在相同的感受野范围能提取更强的非线性。
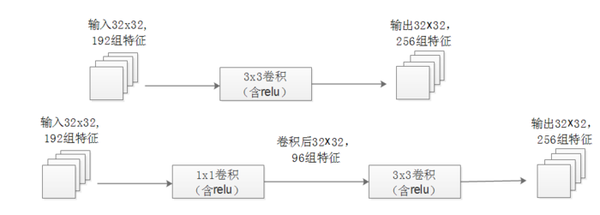
作用2:使用1x1卷积进行降维,降低了计算复杂度。图2中间3x3卷积和5x5卷积前的1x1卷积都起到了这个作用。当某个卷积层输入的特征数较多,对这个输入进行卷积运算将产生巨大的计算量;如果对输入先进行降维,减少特征数后再做卷积计算量就会显著减少。下图是优化前后两种方案的乘法次数比较,同样是输入一组有192个特征、32x32大小,输出256组特征的数据,第一张图直接用3x3卷积实现,需要192x256x3x3x32x32=452984832次乘法;第二张图先用1x1的卷积降到96个特征,再用3x3卷积恢复出256组特征,需要192x96x1x1x32x32+96x256x3x3x32x32=245366784次乘法,使用1x1卷积降维的方法节省了一半的计算量。有人会问,用1x1卷积降到96个特征后特征数不就减少了么,会影响最后训练的效果么?答案是否定的,只要最后输出的特征数不变(256组),中间的降维类似于压缩的效果,并不影响最终训练的结果。
2、多个尺寸上进行卷积再聚合
图2可以看到对输入做了4个分支,分别用不同尺寸的filter进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构有什么好处呢?Szegedy从多个角度进行了解释:
解释1:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
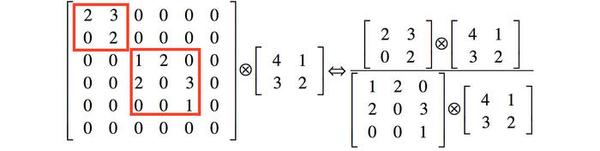
解释2:利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。举个例子下图左侧是个稀疏矩阵(很多元素都为0,不均匀分布在矩阵中),和一个2x2的矩阵进行卷积,需要对稀疏矩阵中的每一个元素进行计算;如果像右图那样把稀疏矩阵分解成2个子密集矩阵,再和2x2矩阵进行卷积,稀疏矩阵中0较多的区域就可以不用计算,计算量就大大降低。这个原理应用到inception上就是要在特征维度上进行分解!传统的卷积层的输入数据只和一种尺度(比如3x3)的卷积核进行卷积,输出固定维度(比如256个特征)的数据,所有256个输出特征基本上是均匀分布在3x3尺度范围上,这可以理解成输出了一个稀疏分布的特征集;而inception模块在多个尺度上提取特征(比如1x1,3x3,5x5),输出的256个特征就不再是均匀分布,而是相关性强的特征聚集在一起(比如1x1的的96个特征聚集在一起,3x3的96个特征聚集在一起,5x5的64个特征聚集在一起),这可以理解成多个密集分布的子特征集。这样的特征集中因为相关性较强的特征聚集在了一起,不相关的非关键特征就被弱化,同样是输出256个特征,inception方法输出的特征“冗余”的信息较少。用这样的“纯”的特征集层层传递最后作为反向计算的输入,自然收敛的速度更快。
解释3:Hebbin赫布原理。Hebbin原理是神经科学上的一个理论,解释了在学习的过程中脑中的神经元所发生的变化,用一句话概括就是fire togethter, wire together。赫布认为“两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种‘组合’,其中一个神经元的兴奋会促进另一个的兴奋”。比如狗看到肉会流口水,反复刺激后,脑中识别肉的神经元会和掌管唾液分泌的神经元会相互促进,“缠绕”在一起,以后再看到肉就会更快流出口水。用在inception结构中就是要把相关性强的特征汇聚到一起。这有点类似上面的解释2,把1x1,3x3,5x5的特征分开。因为训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用。
在inception模块中有一个分支使用了max pooling,作者认为pooling也能起到提取特征的作用,所以也加入模块中。注意这个pooling的stride=1,pooling后没有减少数据的尺寸。
二、论文关键点解析
Page 3:The fundamental way of solving both issues would be by ultimately moving from fully connected to sparsely connected architectures, even inside the convolutions. Besides mimicking biological systems, this would also have the advantage of firmer theoretical underpinnings due to the ground-breaking work of Arora et al. [2]. Their main result states that if the probability distribution of the data-set is representable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer by layer by analyzing the correlation statistics of the activations of the last layer and clustering neurons with highly correlated outputs.
作者提出需要将全连接的结构转化成稀疏连接的结构。稀疏连接有两种方法,一种是空间(spatial)上的稀疏连接,也就是传统的CNN卷积结构:只对输入图像的某一部分patch进行卷积,而不是对整个图像进行卷积,共享参数降低了总参数的数目减少了计算量;另一种方法是在特征(feature)维度进行稀疏连接,就是前一节提到的在多个尺寸上进行卷积再聚合,把相关性强的特征聚集到一起,每一种尺寸的卷积只输出256个特征中的一部分,这也是种稀疏连接。作者提到这种方法的理论基础来自于Arora et al的论文Provable bounds for learning some deep representations(Arora et al这篇论文数学要求太高了,没读懂)。
Page3:On the downside, todays computing infrastructures are very inefficient when it comes to numerical calculation on non-uniform sparse data structures. Even if the number of arithmetic operations is reduced by100×, the overhead of lookups and cache misses is so dominant that switching to sparse matrices would not pay off. The gap is widened even further by the use of steadily improving, highly tuned, numerical libraries that allow for extremely fast dense matrix multiplication, exploit-ing the minute details of the underlying CPU or GPU hardware [16,9]. Also, non-uniform sparse models require more sophisticated engineering and computing infrastructure. Most current vision oriented machine learning systems utilize sparsity in the spatial domain just by the virtue of employing convolutions. However, convolutions are implemented as collections of dense connections to the patches in the earlier layer. ConvNets have traditionally used random and sparse connection tables in the feature dimensions since [11] in order to break the symmetry and improve learning, the trend changed back to full connections with [9] in order to better optimize parallel computing. The uniformity of the structure and a large number of filters and greater batch size allow for utilizing efficient dense computation.
作者提到如今的计算机对稀疏数据进行计算的效率是很低的,即使使用稀疏矩阵算法也得不偿失(见笔者图4描述的计算方法,注意图4左侧的那种稀疏矩阵在计算机内部都是使用元素值+行列值的形式来存储,只存储非0元素)。使用稀疏矩阵算法来进行计算虽然计算量会大大减少,但会增加中间缓存(具体原因请研究稀疏矩阵的计算方法)。
当今最常见的利用数据稀疏性的方法是通过卷积对局部patch进行计算(CNN方法,就是前面提到的在spatial上利用稀疏性);另一种利用数据稀疏性的方法是在特征维度进行利用,比如ConvNets结构,它使用特征连接表来决定哪些卷积的输出才累加到一起(普通结构使用一个卷积核对所有输入特征做卷积,再将所有结果累加到一起,输出一个特征; 而ConvNets是选择性的对某些卷积结果做累加)。ConvNets利用稀疏性的方法现在已经很少用了,因为只有在特征维度上进行全连接才能更高效的利用gpu的并行计算的能力,否则你就得为这样的特征连接表单独设计cuda的接口函数,单独设计的函数往往无法最大限度的发挥gpu并行计算的能力。
Page 4:This raises the question whether there is any hope for a next, intermediate step: an architecture that makes use of the extra sparsity, even at filter level, as suggested by the theory, but exploits our current hardware by utilizing computations on dense matrices. The vast literature on sparse matrix computations (e.g. [3]) suggests that clustering sparse matrices into relatively dense submatrices tends to give state of the art practical performance for sparse matrix multiplication.
前面提到ConvNets这样利用稀疏性的方法现在已经很少用了,那还有什么方法能在特征维度上利用稀疏性么?这就引申出了这篇论文的重点:将相关性强的特征汇聚到一起,也就是上一章提到的在多个尺度上卷积再聚合。
Page 6:The use of average pooling before the classifier is based on [12], although our implementation differs in that we use an extra linear layer.
Network in Network(NIN, https://arxiv.org/pdf/1312.4400.pdf)最早提出了用Global Average Pooling(GAP)层来代替全连接层的方法,具体方法就是对每一个feature上的所有点做平均,有n个feature就输出n个平均值作为最后的softmax的输入。它的好处:1、对数据在整个feature上作正则化,防止了过拟合;2、不再需要全连接层,减少了整个结构参数的数目(一般全连接层是整个结构中参数最多的层),过拟合的可能性降低;3、不用再关注输入图像的尺寸,因为不管是怎样的输入都是一样的平均方法,传统的全连接层要根据尺寸来选择参数数目,不具有通用性。
Page 6:By adding auxiliary classifiers connected to these intermediate layers, we would expect to encourage discrimination in the lower stages in the classifier, increase the gradient signal that gets propagated back, and provide additional regularization.
inception结构在在某些层级上加了分支分类器,输出的loss乘以个系数再加到总的loss上,作者认为可以防止梯度消失问题(事实上在较低的层级上这样处理基本没作用,作者在后来的inception v3论文中做了澄清)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号