聊聊性能测试平台
1. 背景
在刚过去的2020年,我司的全链路压测平台已成功落地。今天呢,宝路就来聊聊自己对性能测试平台设计的一些想法与思考!
2. 平台思维导
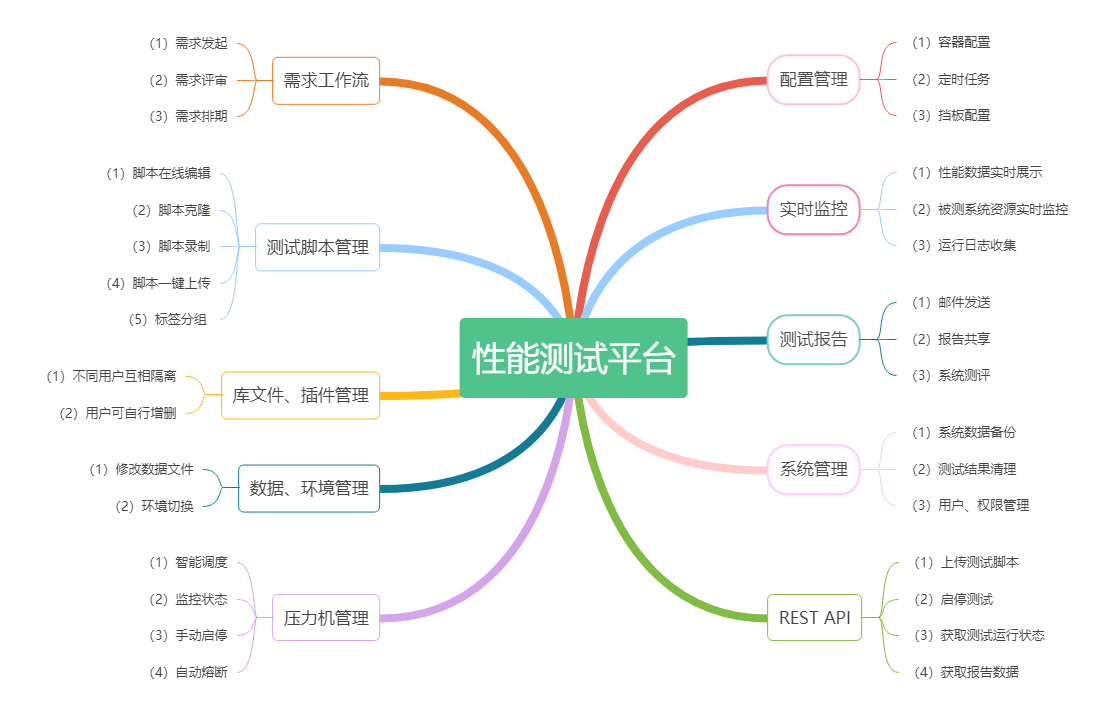
2.1 需求工作流
工作流确保了测试按约定步骤推进,同时让工作的透明度和可再现性。我们工作中常用的有JIRA、TAPD等。平台是完全可以与之进行对接的。
通常情况下压测需求可能由开发部门、业务部门、运维部门发起,测试组接收到压测需求后需要对测试需求调研、评估。
压测需求通过评审后,测试组根据实际情况进行排期、制定压测方案计划。测试组完成压测方案计划后可向项目发起方案评审。多方会议评审通过后,则可进入压测实施、直至测试组完成压测工作,发出性能测试报告。
上面所述的是一个大致的流程,在实施的过程会遇到各种各样的困境,导致流程很难推进下去。
往往很多时候大家对系统性能的认知还不够深刻。本应该做压测的项目却被项目组忽视性能测试,在系统上后引发性能问题;测试跟开发的关系一直很微妙,测试发现的问题多,开发就不happy了(又该挨批了)!测试发现的问题少,上面领导就不happy了(养测试时干什么吃的。。。。)!
开发人员心理叫苦,测试人员也是黯然神伤!今天就不过多展开聊,宝路后面计划专门开一篇 “如何做好性能测试”的文章。
2.2 测试脚本管理
脚本在线编辑:支持测试人员调整脚本,如调整并发用户、压测环境、参数数据等。
脚本克隆:为了测试人员在不改动父脚本的前提下,快速拷贝以达到测试人员快速编写调整脚本。
脚本录制:目前大概有四种脚本编写方式:1.纯手工编写(相对比较慢)、2.JMeter代理录制(感觉不好用)3.Fiddler抓包工具插件转jmx脚本(目前对脚本的兼容性有待考察)4.采用meterSphere的录制插件(目前开源,非常推荐使用)。
脚本一键上传:两种方式:1.传统的文件上传(平台页面点击上传>选择脚本文件进行上传)、2.插件方式(单独开发JMeter插件,GUI模式下编写完脚本后点击上按钮默认直接上传当前脚本及参数化文件,非常的方便,大家可参考bzm开源的插件自行开发)。
脚本标签:这个功能是为了更好的对测试脚本进行快速查找区分,测试人员可根据自定义的标签来实现快速查找脚本。
2.3 库文件、插件管理
在使用JMeter测试工具测试,大家肯定经常会遇到一个问题那就是经常要上传一些插件(需放lib/ext目录下)和依赖的库文件(需放lib目录下)。如果不做统一管理,很容易出现jar包冲突、覆盖其他人上传的包等现象,进而造成测试失败。
那么怎么规避呢?咱们其实可以从用户角度分析,比如:测试用户A在做某个项目时需要上传一个A1插件或A1库文件,但是这个插件或文件对测试用户B根本就用不到。
那就各子维护自己的插件就完事了呗,普通用户自己上传的插件只对自己生效或者可见,那些通用的插件,比如特殊Thread Group、TPS、Shaping Timer等插件则可由组长或者管理员账户统一来维护。这些插件对特定组员或者普通测试用户可见,且不可编辑(防止乱删)。
场景执行前先对salve机器进行数据同步,比如参数文件、插件和库文件、服务器时间等。
2.4 数据、环境管理
修改数据文件:压测的时候经常会遇到脚本中包含了某些参数文件。特别是消耗性的数据,会让人难受。。。。要反复的搞很多个参数化文件,然后再对每个slave机进行替换。既然有了性能平台,那性能平台就应该支持在线修改参数据、一键同步文件。记住这种消耗性的数据一定要进行数据分块。不然在压测过程数据库会形成大量锁等待,造成TPS较低。
环境管理:这个应该很好理解,测试人员可提前维护好各个环境。总之一句话说:“脚本不应依赖于环境”。脚本在运行的时候是可以选择环境的,而不是在脚本中固定请求地址。
2.5 压力机管理
智能调度:根据测试脚本中总并发用户,智能分配压力机,进而达到slave机资源利用率最大化。
监控状态:测试人员可查看压测过程中,所用到slave机的资源消耗情况。如果发现cpu资源消耗较高,可重新配置slave机的并发分配占比,进而达到最优测试结果的目的。
手动启停:在测试过程中,如遇slave状态异常,测试人员可在平台上对slave机进行人为的启停。
自动熔断:在测试过程中,如果在某一段连续时间内,出现大量失败请求,此时salve自动触发停止测试场景,以此来保护被测系统。常用的开源插件有 AutoStop Listener。这个是一个值得探讨的问题,到底是应该停止压测场景,还是停止某些slave机?是maser发起停止全部 还是salve之间互相通知?关于这块,宝路这边也计划深入研究一下,毕竟总有更好的办法!
2.6 配置管理
容器配置:为每台容器salve机器配置并发用户上限、cpu数等。
定时任务:测试人员可以配置计划任务,来达到定制执行压测计划的目的。
挡板配置:支持部署单独的挡板模块。配置管理请求地址、接口报文、交易延迟等。
2.7 实时监控
性能数据结果实时展示:常见的方案有两种:一是采用InfluxDB+ Grafana的解决方案(这里也有“坑”,以后宝路会写文章来分析);二是采用MySQL+Echars +Kafka的解决方案。
被测系统资源监控:解决方案:Collectd+InfluxDB+ Grafana
以上所述的方案,宝路更倾向与采用InfluxDB+ Grafana的解决方案。至于原因嘛,暂且不谈。当然了想做好这些肯定不容易,每个都需要你去了解,不能光看看网上的帖子就以为自己会了。。。有好多东西都是值得深挖的。
2.8 测试报告
邮件发送:这个功能肯定是常用功能,值得讨论的就是制定一个能满足自己的报告模板。其核心主题就是怎么展示才能让不懂性能的人看明白,也就是所谓的通俗易懂。。。不能总站在自己的角度考虑问题,对吧!
报告共享:邮件的方式算其中一种,测试人员也可以采用共享的方式,给制定人员共享测试报告。该用户通过登录平台或者制定连接均可查看。
系统测评:当测试人员完成压测需求后,会根据测试结果再结合约定的规则对系统进行评分,再由测试组长复评。这个规则是值得商榷的。。。比如可以根据不同并发用户下的接口响应时间、系统资源消耗等方面进行规则制定。通过不断的完善,以达成大家均认可的一个评分规则。
2.9 系统管理
这个就简要说了,常用的数据清理功能,可以按时间段清理测试结果,来确保磁盘预留足够的空间,其包含了一些常用的用户权限管理、用户的增删改等。
2.10 REST API
作为一个测试平台,无论功能还是性能,其实都绕不开CI/CD、DevOps。关于这个趋势想必也不需要宝路来过多叙述了。
这就意味着,平台必须要具备这个能力!外部系统可以通过平台API方便的调用平台的服务。图中也仅是举个几个API的例子,为更好的适配,更多的API服务是非常值得开发和研究的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号