Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一、Mycat和Sharding-jdbc的区别
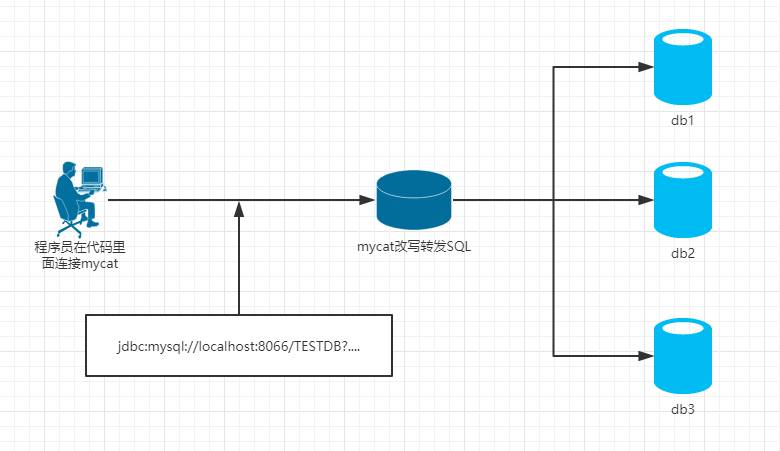
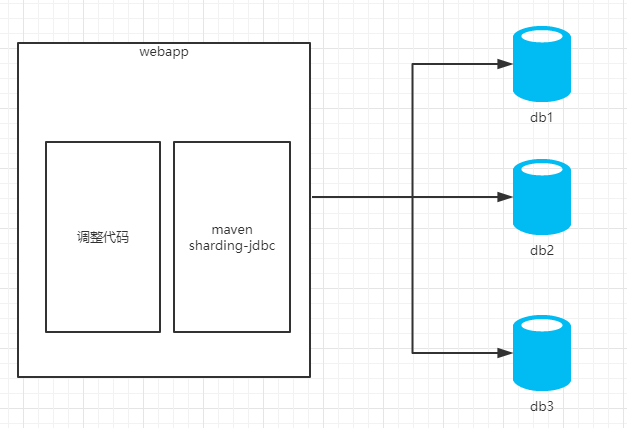
1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
2)使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码
Mycat(proxy中间件层):
Sharding-jdbc(TDDL为代表的应用层):
二、Mycat分片join
在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个:
1.)分布式全局唯一id
2.)分片规则和策略
3.)跨分片技术问题
4.)跨分片事物问题
下面我们来看一下Mycat是如何解决跨分片技术问题——分片join的
1. 使用全局表方式解决跨分片join问题
1.1 先在server.xml里面全局表一致性检测
<property name="useGlobleTableCheck">1</property> <!-- 1为开启全局表一致性检测、0为关闭 -->
1.2 在schema.xml里面配置全局表
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
全局表说明:
1)全局表的插入、更新操作会实时在所有节点上执行,保持各个分片数据的一致性
2)全局表的查询操作只从一个节点上获取
3)全局表可以跟任何一个表进行join操作
2. 使用Share Join方式解决跨分片join问题
Share Join是一个简单的跨分片join,基于HBT(Human Brain Tech)的方式实现。
原理:解析SQL语句,拆分成单表的SQL语句执行,然后把各个节点的数据汇集。
示例:
/*!mycat:catlet=io.mycat.catlets.ShareJoin*/select * from employee a, employee_detail b where a.id = b.id;
说明:目前只支持两张分片表的Join,如果要支持多张表需要自己改造程序代码或者改造Mycat的源代码
对应Mycat源码:
io.mycat.catlets.ShareJoin
io.mycat.catlets.Catlet
public class ShareJoin implements Catlet
3. 使用ER Join方式解决跨分片join问题
ER表也叫父子表,子表存储在哪个分片上依赖于父表的存储位置,并且和父表存储同一个分片上,即子表的记录与所关联的父表记录存放在同一个数据分片上,从而解决跨库join的问题
在schema.xml里面的配置
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile"> <childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id"> <childTable name="order_items" joinKey="order_id" parentKey="id" /> </childTable> <childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" /> </table>
说明:
childTable:标签用来声明子表:
joinKey:声明子表的那个字段和父表关联
parentKey:声明父表的关联主键
primaryKey:父表自身的主键
三、Mycat分页中的坑
Mycat分页的大坑一定要注意:
在对应的分片上去查询分页数据的时候是从第一条记录开始扫描,然后再取出对应的分页数据,如
SELECT * FROM customer ORDER BY id LIMIT 1000100, 100;
这个sql语句被Mycat转化后
1 -> dn1{SELECT * FROM customer ORDER BY id LIMIT 0, 1000100} 2 -> dn2{SELECT * FROM customer ORDER BY id LIMIT 0, 1000100}
所以要在Mycat的server.xm里面开启使用非堆内存。否则内存会爆掉
<property name="useOffHeapForMerge">1</property>
优化:
1)先查出id
SELECT id FROM customer ORDER BY id LIMIT 1000100, 100;
这个sql语句被mycat转化后
1 -> dn1{SELECT id FROM customer ORDER BY id LIMIT 0, 1000100} 2 -> dn2{SELECT id FROM customer ORDER BY id LIMIT 0, 1000100}
2) 拿到所有的id以后再取获取需要的数据
SELECT * FROM customer where id in(1,2,3....);
这个sql语句被mycat转化后
1 -> dn1{SELECT * FROM customer where id in(1,2,3....);} 2 -> dn2{SELECT * FROM customer where id in(1,2,3....);}
四、Mycat注解
1. Mycat不支持的SQL语句:
1) 某些SQL语法,如insert into......select.....
2) 跨库关联查询
3)存储过程创建
4)存储过程调用
所以Mycat提供Mycat注解来解决上面这些不支持的SQL语句
Mycat的解决办法:Mycat注解
语法:
/*!mycat:sql=Mycat注解SQL语句*/真正执行的SQL !号方式
/*#mycat:sql=Mycat注解SQL语句*/真正执行的SQL #号方式
/**mycat:sql=Mycat注解SQL语句*/真正执行的SQL *号方式
原理:
使用mycat不支持的SQL替换mycat支持的SQL,运行Mycat不支持的SQL

Mycat注解规范:
1) 注解SQL使用select语句,不允许使用delete/update/insert等语句;虽然delete/update/insert等语句也能用在注解中,但这些语句在Sql处理中有额外的逻辑判断,从性能考虑,请使用select语句。
2) 注解SQL禁用表关联语句。
3) 注解SQL尽量用最简单的SQL语句,如select id from tab_a where id=’10000’(如果必要,最好能在注解中指定分片)
4) 无论是原始SQL 还是注解SQL,禁止DDL语句
5) 能不用注解的尽量不用
2. Mycat注解解决不支持insert into......select.....
/*!mycat:sql=select 1*/insert into travelrecord(id,user_id,traveldate,fee,days) select 3,'Tom','20180826',100,8;
3. Mycat注解创建表
/*!mycat:sql=select 1 from test */create table test2(id int);
4. Mycat注解创建存储过程
/*!mycat:sql=select 1 from test */create procedure 'test_proc()' begin end;
5. Mycat注解调用存储过程
/*!mycat:sql=select * from user where id=1 */call test_proc();
6. Mycat注解读写分离数据源选择
/*!mycat:db_type=master */select * from travelrecord;(强制走主库) /*!mycat:db_type=slave */select * from travelrecord;(强制走从库)
五、Catlet使用
通过Catlet支持跨分片复杂SQL实现以及存储过程支持等等
使用方式:通过mycat注解方式来执行
1. 跨分片联合查询注解支持
/*!mycat:catlet=io.mycat.catlets.ShareJoin */select o.id,u.* from order o,user u where o.user_id=u.id;
2. 批量插入与ID自增长结合的支持
/*!mycat:catlet=io.mycat.route.sequence.BatchInsertSequence */insert into user(name) values('Tom'),('Cat'),('Alan');

 浙公网安备 33010602011771号
浙公网安备 33010602011771号