
性能优化系列八:MYSQL的配置优化
一、关键配置
1. 配置文件的位置
MySQL配置文件
/etc/my.cnf 或者 /etc/my.cnf.d/server.cnf
几个关键的文件:
.pid文件,记录了进程id
.sock文件,是内部通信使用的socket接口,比3306快
.log文件,日志文件
.cnf或.conf文件,配置文件
安装目录:basedir
数据目录:datadir
2. 在哪里保存你的数据
基本配置,指定数据目录,my.cnf或者server.cnf
[mysqld]
user = mysql
port = 3306
socket = /data/3306/mysql.sock,#这里指定了一个特别的连接
basedir = /usr/local/mysql
datadir = /data/3306/data
[client]
port = 3306
socket = /data/3306/mysql.sock,在客户端也要声明它,命令行要用到
3. 查询缓存要不要开
写入频繁的数据库,不要开查询缓存
query_cache_size
Query_cache里的数据又怎么处理呢?首先要把Query_cache和该表相关的语句全部置为失效,然后在写入更新。那么如果Query_cache非常大,该表的查询结构又比较多,查询语句失效也慢,一个更新或是Insert就会很慢,这样看到的就是Update或是Insert怎么这么慢了。所以在数据库写入量或是更新量也比较大的系统,该参数不适合分配过大。而且在高并发,写入量大的系统,建议把该功能禁掉。
query_cache_limit
指定单个查询能够使用的缓冲区大小,缺省为1M
query_cache_min_res_unit
默认是4KB,设置值大对大数据查询有好处,但如果你的查询都是小数据查询,就容易造成内存碎片和浪费
说明:禁掉查询缓存的方法就是直接注释掉查询缓存的配置,如#query_cache_size=1M, 这样就可以了
4. 其他需要开的缓存
读缓存,线程缓存,排序缓存
sort_buffer_size = 2M
connection级参数。太大将导致在连接数增高时,内存不足。
max_allowed_packet = 32M
网络传输中一次消息传输量的最大值。系统默认值 为1MB,最大值是1GB,必须设置1024的倍数。
join_buffer_size = 2M
和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享
tmp_table_size = 256M
默认大小是 32M。GROUP BY 多不多的问题
max_heap_table_size = 256M
key_buffer_size = 2048M
索引的缓冲区大小,对于内存在4GB左右的服务器来说,该参数可设置为256MB或384MB。
read_buffer_size = 1M
read_rnd_buffer_size = 16M
进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索
bulk_insert_buffer_size = 64M
批量插入数据缓存大小,可以有效提高插入效率,默认为8M
Innodb缓存
innodb_buffer_pool_size = 2048M
只需要用Innodb的话则可以设置它高达 70-80% 的可用内存。一些应用于 key_buffer 的规则有 ——如果你的数据量不大,并且不会暴增,那么无需把innodb_buffer_pool_size 设置的太大了。
innodb_additional_mem_pool_size = 16M
网络传输中一次消息传输量的最大值。系统默认值为1MB,最大值是1GB,必须设置1024的倍数。
innodb_log_files_in_group = 3
循环方式将日志文件写到多个文件。推荐设置为3
innodb_lock_wait_timeout = 120
InnoDB 有其内置的死锁检测机制,能导致未完成的事务回滚。innodb_file_per_table = 0 独享表空间,关闭
5. 连接数
open_files_limit = 10240
允许打开的文件数
back_log = 600
短时间内的多少个请求可以被存在堆栈中
max_connections = 3000
MySQL默认的最大连接数为100,MySQL服务器允许的最大连接数16384
max_connect_errors = 6000
设置每个主机的连接请求异常中断的最大次数,当超过该次数,MYSQL服务器将禁止host的连接请求
thread_cache_size = 300
重新利用保存在缓存中线程的数量
thread_concurrency = 8
thread_concurrency应设为总CPU核数的2倍
thread_stack = 192K
每个线程的堆栈大小,默认值足够大,可满足普通操作。可设置范围为128K至4GB,默认为192KB。
6. 线程池有关参数
线程池很少配
thread_handling
表示线程池模型。
thread_pool_size
表示线程池的group个数,一般设置为当前CPU核心数目。理想情况下,一个group一个活跃的工作线程,达到充分利用CPU的目的。
thread_pool_stall_limit
用于timer线程定期检查group是否“停滞”,参数表示检测的间隔。
thread_pool_idle_timeout
当一个worker空闲一段时间后会自动退出,保证线程池中的工作线程在满足请求的情况下,保持比较低的水平。60秒
thread_pool_oversubscribe
该参数用于控制CPU核心上“超频”的线程数。这个参数设置值不含listen线程计数。
threadpool_high_prio_mode
表示优先队列的模式。
thread_pool_max_threads
限制线程池最大的线程数,超过将无法再创建更多的线程,默认为100000。
thread_pool_high_prio_tickets
最多语序多少次被放入高优先级队列中,默认为4294967295。只有在thread_pool_high_prio_mode为transactions的时候才有效果
说明:
线程处理的最小单位是statement(语句)
线程池实现在server端,通过创建一定数量的线程服务DB请求,相对于one-conection-per-thread的一个线程服务一个连接的方式,线程池服务的最小单位是语句,即一个线程可以对应多个活跃的连接。
7. 慢查询日志
slow_query_log
是否开启慢查询日志,1表示开启,0表示关闭。
log-slow-queries
旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
slow-query-log-file
新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
long_query_time
慢查询阈值,当查询时间多于设定的阈值时,记录日志。
log_queries_not_using_indexes
未使用索引的查询也被记录到慢查询日志中(可选项)。
log_output
日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
二、监控工具
1. innotop工具
安装:yum install innotop
启动:innotop -u root -p ‘123’
帮助:?
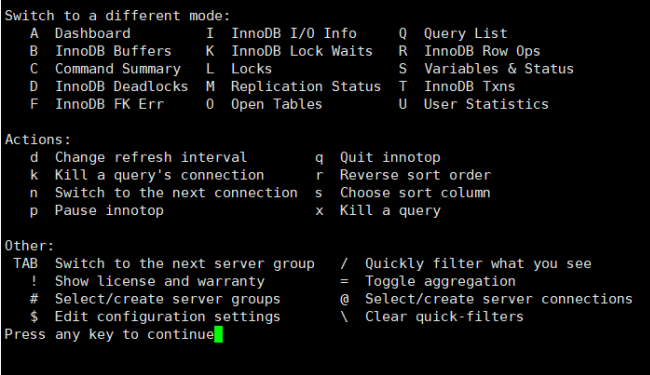
说明:
innotop是一个实时工具,只能查看当前的情况,不能记录历史情况
查看帮助的时候输入一个 ?
帮助里面的ABCD.....U就是可以查看对应的指标的情况,如查询列表输入Q、查询缓冲区输入B、命令统计输入C
2. lepus工具
http://www.lepus.cc/page/product
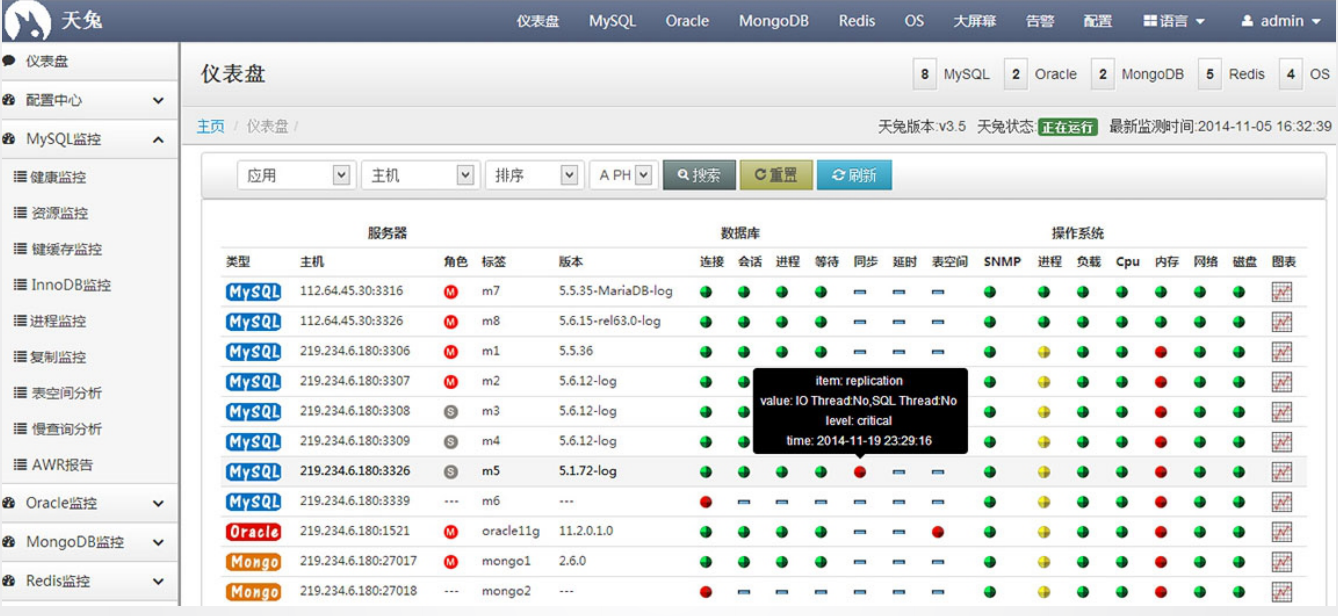
说明:
lepus是一款开源的数据库监控工具,能监控各种数据库,能监控多台数据库,能查看历史情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号