性能优化系列六:数据库设计
一、为优化而设计
1. 数据库设计
数据库设计,一个软件项目成功的基石。数据库设计也是门学问。
在项目早期由开发者进行数据库设计(后期调优需要DBA)。一个精通OOP和ORM的开发者,设计的数据库往往更为合理,更能适应需求的变化。因为数据库的规范化,与OO的部分思想雷同(如内聚)。而DBA,设计的数据库的优势是能将DBMS的能力发挥到极致,能够使用SQL和DBMS实现很多程序实现的逻辑,与开发者相比,DBA优化过的数据库更为高效和稳定。
2. 数据库设计与程序设计的差异
有如下的一个系统:
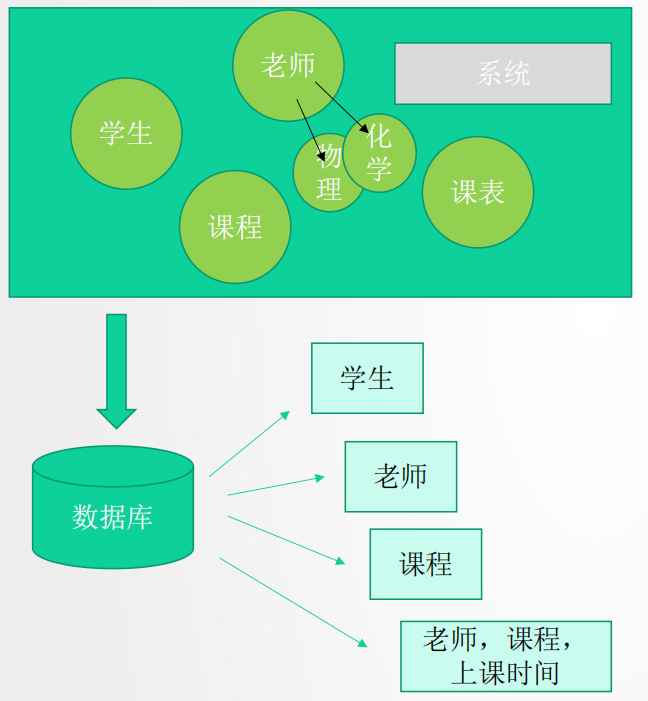
面向对象设计思路:
封装
多态
IOC
AOP…
数据库的设计思路:
关注存储
关注效率
二维表关系
关注完整性
3. 数据库设计早期优化
不要把它仅仅当成一个存储的功能
1、关系明确:各个表之间的关系一定要先例清楚
2、节省空间:原则合适的类型,不要浪费存储空间
3、提高效率:比如现在的操作系统都是64位的,我们选择主键的类型为beginint,因为beginint也是64位的,和cpu寄存器匹配,这样就能一次计算拿到值,效率更高
二、设计原则
1. 数据库种类

说明:我们这里所说的数据库都是指关系型数据库
2. 数据库特点
文件系统和数据库系统之间的区别:
(1)文件系统用文件将数据长期保存在外存上,数据库系统用数据库统一存储数据;
(2)文件系统中的程序和数据有一定的联系,数据库系统中的程序和数据分离;
(3)文件系统用操作系统中的存取方法对数据进行管理,数据库系统用DBMS统一管理和控制数据;
(4)文件系统实现以文件为单位的数据共享,数据库系统实现以记录和字段为单位的数据共享。
文件系统和数据库系统之间的联系:
(1)均为数据组织的管理技术;
(2)均由数据管理软件管理数据,程序与数据之间用存取方法进行转换;
(3)数据库系统是在文件系统的基础上发展而来的。
3. 优化设计第一步
精通数据类型
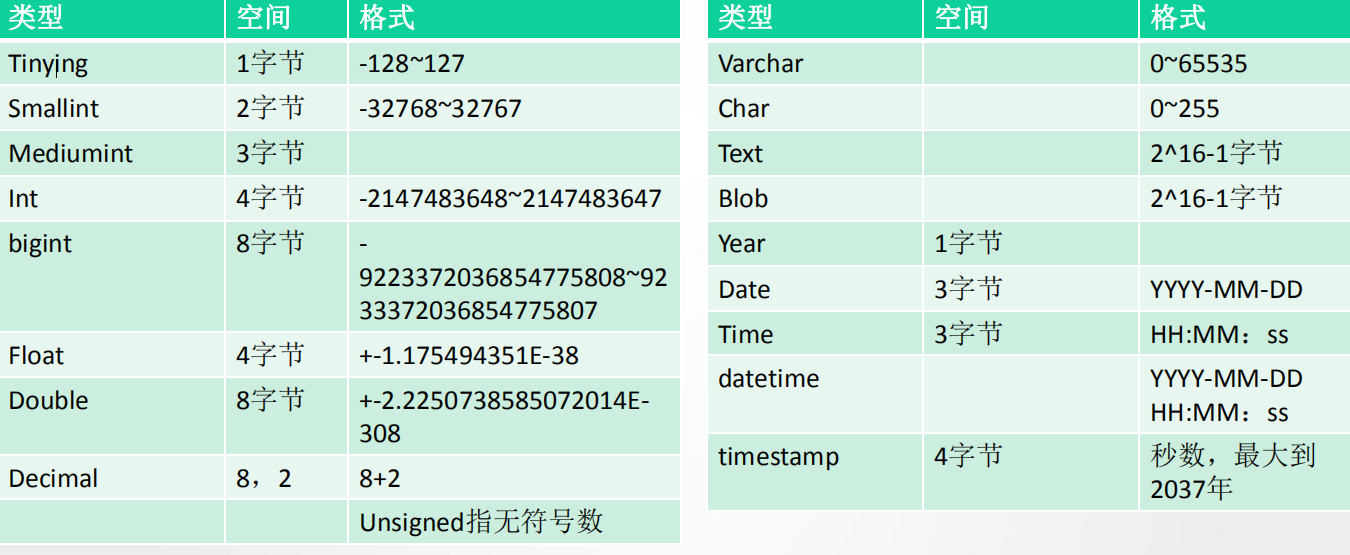
4. 优化设计第二步
了解范式1NF,2NF,3NF。。。
4.1 第一范式
1NF:列不可分。每一列都是不可分割的基本数据项
反例:某列:姓名=(小李,小张)
4.2 第二范式
2NF:1NF的基础上面,非主属性完全依赖于主关键字
ID,学号,姓名,帐号,年级
姓名、年龄这些非主属性依赖于主关键字学号、账号
4.3 第三范式
3NF:属性不依赖于其它非主属性 , 消除传递依赖
课程表:学员ID,学号,年级
这里的学号就和4.2中的学号存在传递依赖,因为4.2中的学号变更了,这里的学号也要跟着变更
4.4 BCNF:符合3NF,每个表中只有一个候选键
4.5 4NF:没有多值依赖
说明:在设计表的时候满足第一二三范式
5. 优化设计第三步
设计之前要有一些想法
1、选择小的数据类型——节省空间
2、单独设计主键,并考虑分布式扩展
3、外键设计
4、索引设计——提高性能
5、关联关系表设计,多对一,多对多
6、读写频繁的信息,与不频繁的信息分开
7、配置表,日志表,定时任务表等
8、汇总表设计——解决大数据性能问题时根据业务场景汇总数据
6. 优化设计第四步
要有一些套路
1、通用型设计
例:人员,部门,角色
这里指的通用型设计是指适用性,比如最开始做的是一个小公司的OA系统的数据库设计,后面切换到一个国际型的大公司以后,这一套设计是否还能用
2、特别设计
附件,日志,配置,监控等
3、存储设计
类型划分便于分区
4、一些附加字段
创建日期,修改日期,排序
5、流水表
类似于日志,但由业务处理结果组成,帐户变动或业务处理的中间值
7. Codd的RDBMS12法则
Edgar Frank Codd(埃德加·弗兰克·科德)被誉为“关系数据库之父”,并因为在数据库管理系统的理论和实践方面的杰出贡献于1981年获图灵奖。在1985年,Codd博士发布了12条规则,这些规则简明的定义出一个关系型数据库的理念,它们被作为所有关系数据库系统的设计指导性方针。
1.信息法则 关系数据库中的所有信息都用唯一的一种方式表示——表中的值。
2.保证访问法则 依靠表名、主键值和列名的组合,保证能访问每个数据项。
3.空值的系统化处理 支持空值(NULL),以系统化的方式处理空值,空值不依赖于数据类型。
4.基于关系模型的动态联机目录 数据库的描述应该是自描述的,在逻辑级别上和普通数据采用同样的表示方式,即数据库必须含有描述该数据库结构的系统表或者数据库描述信息应该包含在用户可以访问的表中。
5.统一的数据子语言法则 一个关系数据库系统可以支持几种语言和多种终端使用方式,但必须至少有一种语言,它的语句能够一某种定义良好的语法表示为字符串,并能全面地支持以下所有规则:数据定义、视图定义、数据操作、约束、授权以及事务。(这种语言就是SQL)
6.视图更新法则 所有理论上可以更新的视图也可以由系统更新。
7.高级的插入、更新和删除操作 把一个基础关系或派生关系作为单个操作对象处理的能力不仅适应于数据的检索,还适用于数据的插入、修改个删除,即在插入、修改和删除操作中数据行被视作集合。
8.数据的物理独立性 不管数据库的数据在存储表示或访问方式上怎么变化,应用程序和终端活动都保持着逻辑上的不变性。
9.数据的逻辑独立性 当对表做了理论上不会损害信息的改变时,应用程序和终端活动都会保持逻辑上的不变性。
10.数据完整性的独立性 专用于某个关系型数据库的完整性约束必须可以用关系数据库子语言定义,而且可以存储在数据目录中,而非程序中。
11.分布独立性 不管数据在物理是否分布式存储,或者任何时候改变分布策略,RDBMS的数据操纵子语言必须能使应用程序和终端活动保持逻辑上的不变性。
12.非破坏性法则 如果一个关系数据库系统支持某种低级(一次处理单个记录)语言,那么这个低级语言不能违反或绕过更高级语言(一次处理多个记录)规定的完整性法则或约束,即用户不能以任何方式违反数据库的约束
落实这些原则:
(一)降低对数据库功能的依赖
(二)定义实体关系的原则
牵涉到的实体 识别出关系所涉及的所有实体。
所有权 考虑一个实体“拥有”另一个实体的情况。
基数 考量一个实体的实例和另一个实体实例关联的数量。
(三)列意味着唯一的值
如果表示坐标(0,0),应该使用两列表示,而不是将“0,0”放在1个列中。
(四)列的顺序,可读性问题
(五)定义主键和外键
数据表必须定义主键和外键(如果有外键)。
(六)选择键
(七)是否允许NULL
任何值和NULL拼接后都为NULL。
所有与NULL进行的数学操作都返回NULL。
引入NULL后,逻辑不易处理。
(八)规范化——范式
1NF
包含分隔符类字符的字符串数据。
名字尾端有数字的属性。
没有定义键或键定义不好的表。
2NF
多个属性有同样的前缀。
重复的数据组。
汇总的数据,所引用的数据在一个完全不同的实体中。
BCNF- “每个键必须唯一标识实体,每个非键熟悉必须描述实体。
4NF
三元关系(实体:实体:实体)。
潜伏的多值属性。(如多个手机号。)
临时数据或历史值。(需要将历史数据的主体提出,否则将存在大量冗余。)
(九)选择数据类型
(十)优化并行
设计DB时就应该考虑到对并行进行优化,比如,timestamp类型。
8. 命名规则
表名规则
1、要用前缀,但不要用无意义的前缀,一般是根据业务模块设置前缀
2、下划线分隔
3、全小写
列名规则
1、一般不用前缀
2、下划线分隔
3、全小写
三、设计案例
1. 键设计
物理主键,好建索引,消除传递依赖
主键类型,普通系统是int或bigint,效率问题,目前的操作系统基本都是64位的,建议使用bigint
Uuid,容量问题,防碰撞
取消所有的联合主键(课程表中:年级+课程名)
2. 索引设计
2.1. B-Tree 索引
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持B-Tree 索引。不仅仅在MySQL中是如此,实际上在其他的很多数据库管理系统中B-Tree索引也同样是作为最主要的索引类型,这主要是因为B-Tree索引的存储结构在数据库的数据检索中有非常优异的表现
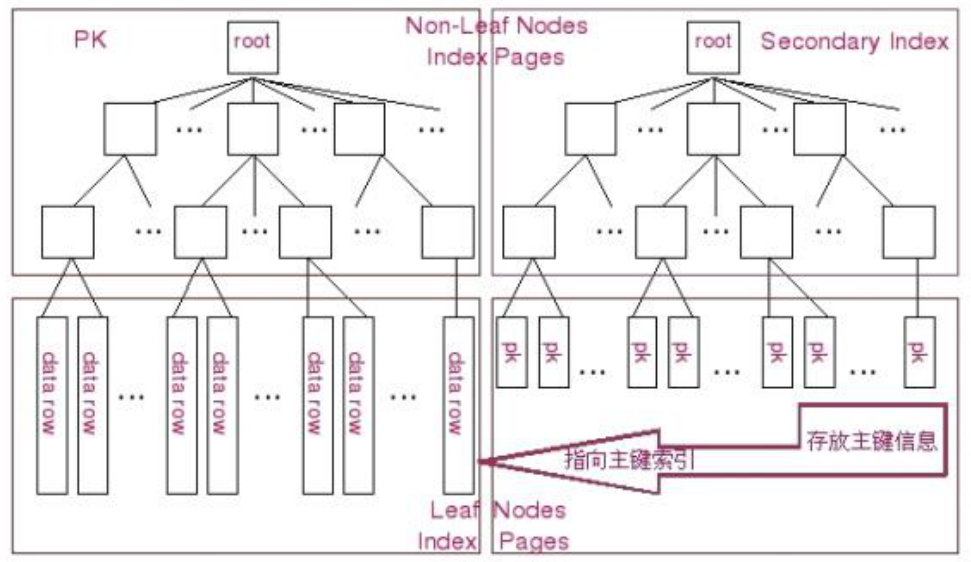
2.2. Hash 索引
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引。
示例:
Hash值:1111对应的有 记录1,记录2,记录3
Hash值:2222对应的记录有 记录4,记录5,记录6
说明:
根据字段计算hash值,把记录放在一个格子里,索引的时候只需要找到hash值就能获取到里面的记录了
2.3. 索引的类型
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
覆盖索引(Covering Indexes):查询的列正好是索引列就叫做覆盖索引,如select id from table_a
聚簇索引(Clustered Indexes)
聚簇索引保证关键字的值相近的元组存储的物理位置也相同(所以字符串类型不宜建立聚簇索引,特别是随机字符串,会使得系统进行大量的移动操作),且一个表只能有一个聚簇索引。因为由存储引擎实现引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。
非聚簇索引
二级索引叶子节点保存的不是指行的物理位置的指针,而是行的主键值。这意味着通过二级索引查找行。
InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
2.4 什么时候可以建索引
1)列无重复值,可以建索引:唯一索引和普通索引
2)聚集索引和非聚集索引都可以是唯一的。因此,只要列中的数据是唯一的,就可以在同一个表上创建一个唯一的聚集索引和多个唯一的非聚集索引。
3)建了索引性能得到提高
4)区分度高的列可以建索引,比如表示男和女的列区分度就不高,就不能建索引
说明:
唯一索引一定要小心,它带有唯一约束。
查询区分度:SELECT COUNT(DISTINCT 列_xx)/COUNT(*) FROM 表
2.5 什么时候不可以建索引
1.频繁更新的字段不适合建立索引
2.where条件中用不到的字段不适合建立索引
3.表数据可以确定比较少的不需要建索引
4.数据重复且发布比较均匀的的字段不适合建索引(唯一性太差的字段不适合建立索引),例如性别,真假值
5. 参与列计算的列不适合建索引,如select * from where amount+1>10
6. 查询返回的记录数不适合建立索引
7. 查询的排序表记录小于40%不适合建立索引
8. 查询非排序表的记录小于 7%不适合建立索引
9. 表的碎片较多(频繁增加、删除)不适合建立索引
说明:
基础表维护时,系统要同时维护索引,不合理的索引将严重影响系统资源,主要表现在CPU和I/O上;
插入、更新、删除数据产生大量db file sequential read锁等待;
2.6 建索引的目的
加快查询速度,当然了,使用索引后查询有迹可循。
减少I/O操作,通过索引的路径来检索数据,不是在磁盘中随机检索。
消除磁盘排序,索引是排序的,走完索引就排序完成
2.7 存储引擎及文件格式比较
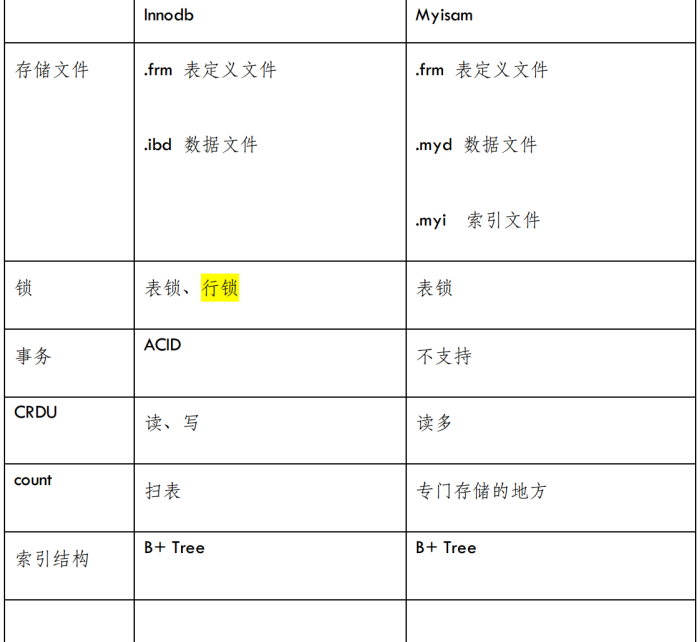
只需要记住Innodb和Myisam的锁和事物的区别就可以了:
Innodb支持表锁和行锁,Myisam只支持表锁
Innodb支持事物,Myisam不支持事物
2.8 各存储引擎的区别
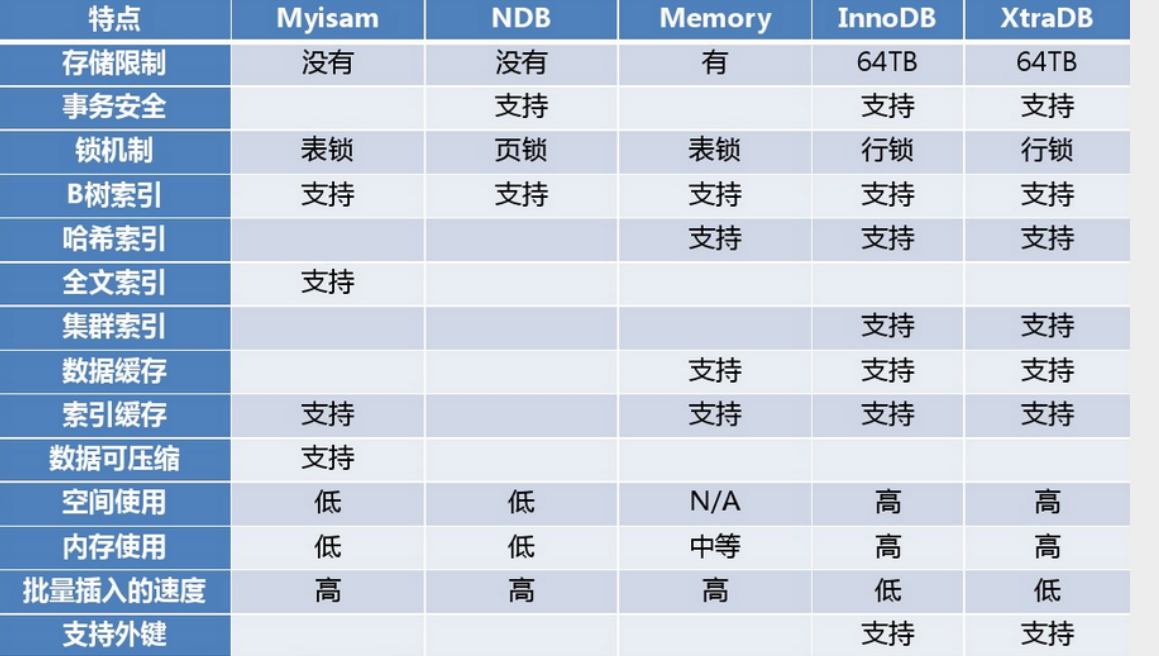
说明:
Innod的存储最大限制64TB
3. 表附加字段设计
常用:
创建时间:create_at
修改时间:update_at
排序:sn
有时用:
说明:desc,remark
备选字段:opts_1,opts_2….
4. 字典表设计
字典表与系统配置表的区别
字典表示例
常用数据的常量化,消费类型,支付类型,物品类型(含层级)
系统配置表示例
各模块功能参数的常量化,key-value
字典表:
CREATE TABLE dict_content ( dcc_id bigint NOT NULL, dct_id bigint, dcc_no character varying(20), dcc_name character varying(30), extend_no character varying(50), remarks character varying(400), sort bigint, parent_id bigint, is_leaf smallint, path character varying(400), CONSTRAINT dict_content_pkey PRIMARY KEY (dcc_id) )
系统表:
CREATE TABLE sys_config_data ( id bigint NOT NULL, create_date timestamp without time zone NOT NULL, modify_date timestamp without time zone NOT NULL, catalog character varying(255), content character varying(255), description character varying(255), sn character varying(255), CONSTRAINT sys_config_data_pkey PRIMARY KEY (id) )
5. 附件表设计
存储位置
类型
用途
使用次数
下载次数
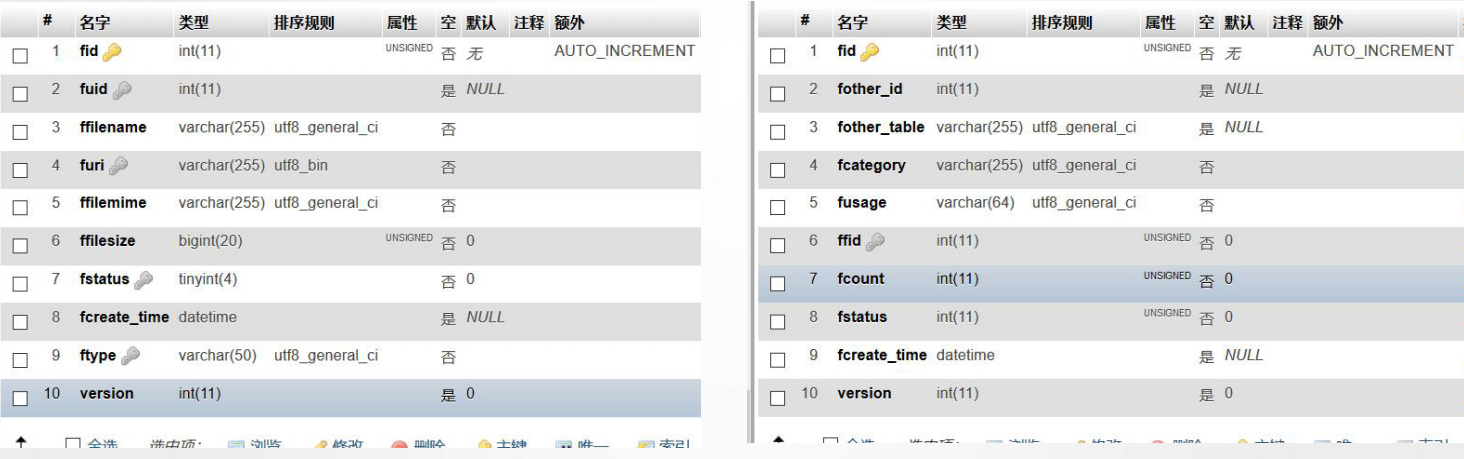
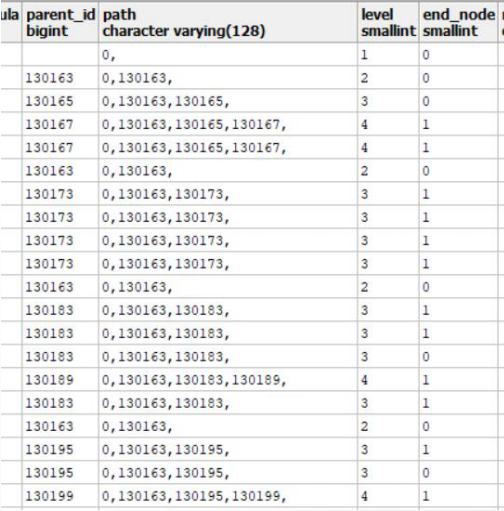
6. 层级结构表设计
父子层级,parent_id
表内划分层级
表外划分层级
最快检索设计
CREATE TABLE public.ihp_boq_tpl ( boq_id bigint NOT NULL, -- 清单id boq_no character varying(32), -- 清单编号 ext_no character varying(32), -- 扩展编号 boq_name character varying(64), -- 清单名称 unit_id bigint, -- 计量单位 boq_kind smallint, -- 清单类型 boq_mode smallint, -- 清单模式 boq_rate numeric(18,2), -- 计量率 formula character varying(32), -- 计算公式 use_formula smallint, -- 是否启用公式 parent_id bigint, -- 父节点 path character varying(128), -- 路径 level smallint, -- 层次 end_node smallint, -- 最终节点 remarks character varying(256), -- 备注 status smallint, -- 状态 feature character varying(128), frequency character varying(32), quota_unit_id bigint, quota_tbl_no character varying(8), project_id bigint, CONSTRAINT pk_ihp_boq_tpl PRIMARY KEY (boq_id) )
7. 流程表设计
流程主表
任务子表
业务表关联
CREATE TABLE process_run ( runid bigint NOT NULL, subject character varying(256) NOT NULL, creator character varying(128), userid bigint NOT NULL, defid bigint NOT NULL, piid character varying(64), createtime timestamp without time zone NOT NULL, runstatus bigint NOT NULL, busdesc character varying(1024), entityname character varying(128), entityid bigint, formdefid bigint, CONSTRAINT pk_process_run PRIMARY KEY (runid) )
CREATE TABLE process_form ( formid bigint NOT NULL, runid bigint NOT NULL, activityname character varying(256) NOT NULL, createtime timestamp without time zone NOT NULL, endtime timestamp without time zone, durtimes bigint, creatorid bigint, creatorname character varying(256), taskid character varying(64), status bigint DEFAULT 0, preformid bigint, comments character varying(2000), entity_id bigint, entity_name character varying(128), CONSTRAINT pk_process_form PRIMARY KEY (formid) )
四、冗余设计
反范式
适当冗余
1、借鉴覆盖索引的思路,在表内直接放常用的字段
2、提取相关数据,制作汇总表
3、第3NF的违反
4、程序级别的冗余或缓存
5、不要写触发器,不要写存储过程
分表分库
•性能:能轻松面对海量数据和高并发的请求处理,好的分布式数据库能做到90%以上的线性增长能力;
•灵活性、弹性:现代的系统的业务和使用场景变化很快,用户的增长也有很多不确定因素。弹性扩容就非常重要。分布式数据库本身有Cloud-Ready的特性,能很容以通过添加设备扩容满足需求,而不需要影响开发;
•多中心、多活:这点在大型应用中很常见,分布式数据库就更容易实现这个功能,当然这里涉及到分布式数据库的同步和一致性的能力,这也是判断分布式数据库好坏的一个重要指标。
•读写分离:主从节点都能发挥作用;例如巨杉SequoiaDB数据库,能在一组三副本的复制组上实现OLTP,NoSQL应用,OLAP多种应用场景同时使用。
•低成本:x86服务器,SATA存储(部分可以用SSD),加上较好的网络带宽就可以了。
1.水平分区:基本对1个或多个键的水平哈希,增强数据的并行处理能力来提高性能;
2.垂直分区:和过去的Partition很像,对数据进行有含义的拆分;
3.混合分区:水平分区和垂直分区共同使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号