
elasticsearch系列七:ES Java客户端-Elasticsearch Java client(ES Client 简介、Java REST Client、Java Client、Spring Data Elasticsearch)
一、ES Client 简介
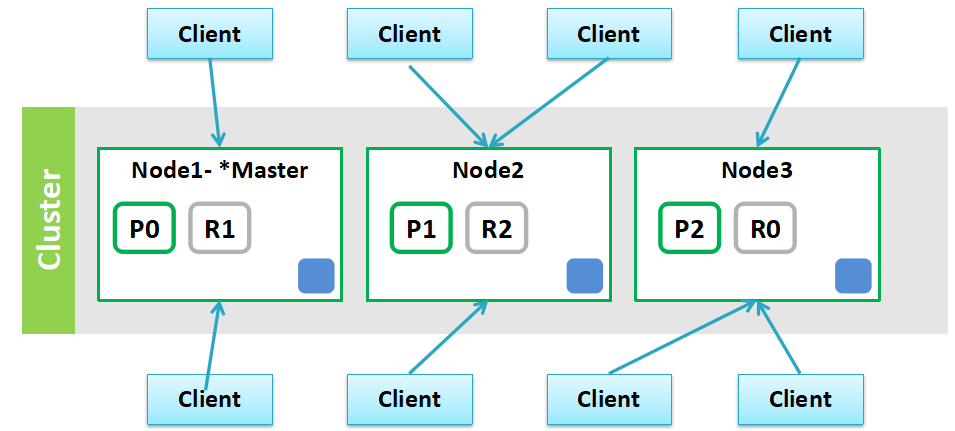
1. ES是一个服务,采用C/S结构
2. 回顾 ES的架构
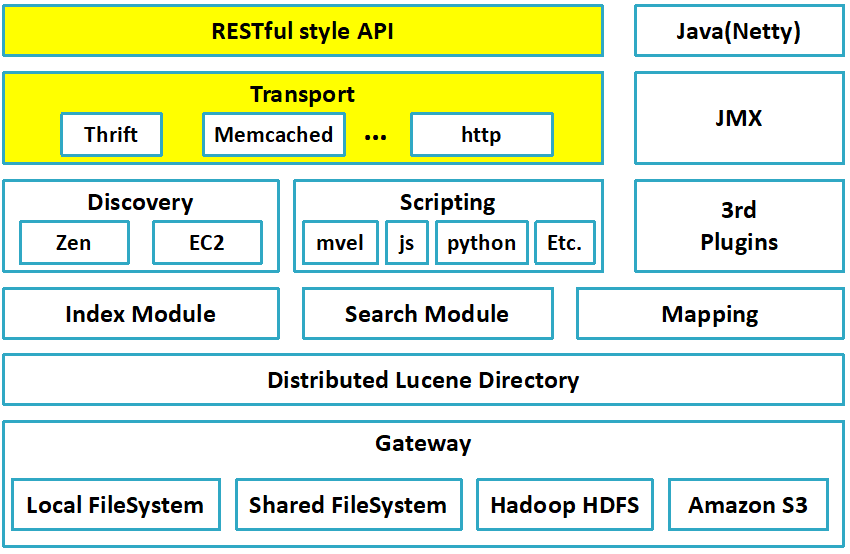
3. ES支持的客户端连接方式
3.1 REST API ,端口 9200
这种连接方式对应于架构图中的RESTful style API这一层,这种客户端的连接方式是RESTful风格的,使用http的方式进行连接

3.2 Transport 连接 端口 9300
这种连接方式对应于架构图中的Transport这一层,这种客户端连接方式是直接连接ES的节点,使用TCP的方式进行连接

4. ES提供了多种编程语言客户端

官网可以了解详情:
https://www.elastic.co/guide/en/elasticsearch/client/index.html
二、Java REST Client介绍
1. ES提供了两个JAVA REST client 版本
Java Low Level REST Client: 低级别的REST客户端,通过http与集群交互,用户需自己编组请求JSON串,及解析响应JSON串。兼容所有ES版本。
Java High Level REST Client: 高级别的REST客户端,基于低级别的REST客户端,增加了编组请求JSON串、解析响应JSON串等相关api。使用的版本需要保持和ES服务端的版本一致,否则会有版本问题。
2. Java Low Level REST Client 说明
特点,maven 引入、使用介绍: https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-low.html
API doc :https://artifacts.elastic.co/javadoc/org/elasticsearch/client/elasticsearch-rest-client/6.2.4/index.html.
3. Java High Level REST Client 说明
从6.0.0开始加入的,目的是以java面向对象的方式来进行请求、响应处理。
每个API 支持 同步/异步 两种方式,同步方法直接返回一个结果对象。异步的方法以async为后缀,通过listener参数来通知结果。
高级java REST 客户端依赖Elasticsearch core project
兼容性说明:
依赖 java1.8 和 Elasticsearch core project
请使用与服务端ES版本一致的客户端版本
4. Java High Level REST Client maven 集成
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.2.4</version> </dependency>
5. Java High Level REST Client 初始化
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http")));
给定集群的多个节点地址,将客户端负载均衡地向这个节点地址集发请求
Client 不再使用了,记得关闭它:
client.close();
API及用法示例,请参考:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-supported-apis.html
三、Java High Level REST Client 使用示例
准备:
编写示例之前首先在maven工程里面引入和ES服务端版本一样的Java客户端
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>6.2.4</version> </dependency>
给定集群的多个节点地址,将客户端负载均衡地向这个节点地址集发请求:
InitDemo.java
package com.study.es_hrset_client; import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; /** * * @Description: 获取Java High Level REST Client客户端 * @author lgs * @date 2018年6月23日 * */ public class InitDemo { public static RestHighLevelClient getClient() { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http"))); return client; } }
注意使用ES的客户端时类比之前我们在Kibana进行的ES的相关操作,这样使用起来更加有效果
1. Create index 创建索引
CreateIndexDemo.java
package com.study.es_hrset_client; import java.io.IOException; import org.elasticsearch.action.admin.indices.alias.Alias; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.xcontent.XContentType; /** * * @Description: 创建索引 * @author lgs * @date 2018年6月23日 * */ public class CreateIndexDemo { public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建 创建索引request 参数:索引名mess CreateIndexRequest request = new CreateIndexRequest("mess"); // 2、设置索引的settings request.settings(Settings.builder().put("index.number_of_shards", 3) // 分片数 .put("index.number_of_replicas", 2) // 副本数 .put("analysis.analyzer.default.tokenizer", "ik_smart") // 默认分词器 ); // 3、设置索引的mappings request.mapping("_doc", " {\n" + " \"_doc\": {\n" + " \"properties\": {\n" + " \"message\": {\n" + " \"type\": \"text\"\n" + " }\n" + " }\n" + " }\n" + " }", XContentType.JSON); // 4、 设置索引的别名 request.alias(new Alias("mmm")); // 5、 发送请求 // 5.1 同步方式发送请求 CreateIndexResponse createIndexResponse = client.indices() .create(request); // 6、处理响应 boolean acknowledged = createIndexResponse.isAcknowledged(); boolean shardsAcknowledged = createIndexResponse .isShardsAcknowledged(); System.out.println("acknowledged = " + acknowledged); System.out.println("shardsAcknowledged = " + shardsAcknowledged); // 5.1 异步方式发送请求 /*ActionListener<CreateIndexResponse> listener = new ActionListener<CreateIndexResponse>() { @Override public void onResponse( CreateIndexResponse createIndexResponse) { // 6、处理响应 boolean acknowledged = createIndexResponse.isAcknowledged(); boolean shardsAcknowledged = createIndexResponse .isShardsAcknowledged(); System.out.println("acknowledged = " + acknowledged); System.out.println( "shardsAcknowledged = " + shardsAcknowledged); } @Override public void onFailure(Exception e) { System.out.println("创建索引异常:" + e.getMessage()); } }; client.indices().createAsync(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
运行结果:
acknowledged = true
shardsAcknowledged = true
2. index document
索引文档,即往索引里面放入文档数据.类似于数据库里面向表里面插入一行数据,一行数据就是一个文档
IndexDocumentDemo.java
package com.study.es_hrset_client; import java.io.IOException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.ElasticsearchException; import org.elasticsearch.action.DocWriteResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.support.replication.ReplicationResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.rest.RestStatus; /** * * @Description: 索引文档,即往索引里面放入文档数据.类似于数据库里面向表里面插入一行数据,一行数据就是一个文档 * @author lgs * @date 2018年6月23日 * */ public class IndexDocumentDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建索引请求 IndexRequest request = new IndexRequest( "mess", //索引 "_doc", // mapping type "1"); //文档id // 2、准备文档数据 // 方式一:直接给JSON串 String jsonString = "{" + "\"user\":\"kimchy\"," + "\"postDate\":\"2013-01-30\"," + "\"message\":\"trying out Elasticsearch\"" + "}"; request.source(jsonString, XContentType.JSON); // 方式二:以map对象来表示文档 /* Map<String, Object> jsonMap = new HashMap<>(); jsonMap.put("user", "kimchy"); jsonMap.put("postDate", new Date()); jsonMap.put("message", "trying out Elasticsearch"); request.source(jsonMap); */ // 方式三:用XContentBuilder来构建文档 /* XContentBuilder builder = XContentFactory.jsonBuilder(); builder.startObject(); { builder.field("user", "kimchy"); builder.field("postDate", new Date()); builder.field("message", "trying out Elasticsearch"); } builder.endObject(); request.source(builder); */ // 方式四:直接用key-value对给出 /* request.source("user", "kimchy", "postDate", new Date(), "message", "trying out Elasticsearch"); */ //3、其他的一些可选设置 /* request.routing("routing"); //设置routing值 request.timeout(TimeValue.timeValueSeconds(1)); //设置主分片等待时长 request.setRefreshPolicy("wait_for"); //设置重刷新策略 request.version(2); //设置版本号 request.opType(DocWriteRequest.OpType.CREATE); //操作类别 */ //4、发送请求 IndexResponse indexResponse = null; try { // 同步方式 indexResponse = client.index(request); } catch(ElasticsearchException e) { // 捕获,并处理异常 //判断是否版本冲突、create但文档已存在冲突 if (e.status() == RestStatus.CONFLICT) { logger.error("冲突了,请在此写冲突处理逻辑!\n" + e.getDetailedMessage()); } logger.error("索引异常", e); } //5、处理响应 if(indexResponse != null) { String index = indexResponse.getIndex(); String type = indexResponse.getType(); String id = indexResponse.getId(); long version = indexResponse.getVersion(); if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) { System.out.println("新增文档成功,处理逻辑代码写到这里。"); } else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) { System.out.println("修改文档成功,处理逻辑代码写到这里。"); } // 分片处理信息 ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo(); if (shardInfo.getTotal() != shardInfo.getSuccessful()) { } // 如果有分片副本失败,可以获得失败原因信息 if (shardInfo.getFailed() > 0) { for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) { String reason = failure.reason(); System.out.println("副本失败原因:" + reason); } } } //异步方式发送索引请求 /*ActionListener<IndexResponse> listener = new ActionListener<IndexResponse>() { @Override public void onResponse(IndexResponse indexResponse) { } @Override public void onFailure(Exception e) { } }; client.indexAsync(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
运行结果:
新增文档成功,处理逻辑代码写到这里。
3. get document
获取文档数据
GetDocumentDemo.java
package com.study.es_hrset_client; import java.io.IOException; import java.util.Map; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.ElasticsearchException; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.Strings; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.fetch.subphase.FetchSourceContext; /** * * @Description: 获取文档数据 * @author lgs * @date 2018年6月23日 * */ public class GetDocumentDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建获取文档请求 GetRequest request = new GetRequest( "mess", //索引 "_doc", // mapping type "1"); //文档id // 2、可选的设置 //request.routing("routing"); //request.version(2); //request.fetchSourceContext(new FetchSourceContext(false)); //是否获取_source字段 //选择返回的字段 String[] includes = new String[]{"message", "*Date"}; String[] excludes = Strings.EMPTY_ARRAY; FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes); request.fetchSourceContext(fetchSourceContext); //也可写成这样 /*String[] includes = Strings.EMPTY_ARRAY; String[] excludes = new String[]{"message"}; FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes); request.fetchSourceContext(fetchSourceContext);*/ // 取stored字段 /*request.storedFields("message"); GetResponse getResponse = client.get(request); String message = getResponse.getField("message").getValue();*/ //3、发送请求 GetResponse getResponse = null; try { // 同步请求 getResponse = client.get(request); } catch (ElasticsearchException e) { if (e.status() == RestStatus.NOT_FOUND) { logger.error("没有找到该id的文档" ); } if (e.status() == RestStatus.CONFLICT) { logger.error("获取时版本冲突了,请在此写冲突处理逻辑!" ); } logger.error("获取文档异常", e); } //4、处理响应 if(getResponse != null) { String index = getResponse.getIndex(); String type = getResponse.getType(); String id = getResponse.getId(); if (getResponse.isExists()) { // 文档存在 long version = getResponse.getVersion(); String sourceAsString = getResponse.getSourceAsString(); //结果取成 String Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); // 结果取成Map byte[] sourceAsBytes = getResponse.getSourceAsBytes(); //结果取成字节数组 logger.info("index:" + index + " type:" + type + " id:" + id); logger.info(sourceAsString); } else { logger.error("没有找到该id的文档" ); } } //异步方式发送获取文档请求 /* ActionListener<GetResponse> listener = new ActionListener<GetResponse>() { @Override public void onResponse(GetResponse getResponse) { } @Override public void onFailure(Exception e) { } }; client.getAsync(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
4. Bulk
批量索引文档,即批量往索引里面放入文档数据.类似于数据库里面批量向表里面插入多行数据,一行数据就是一个文档
BulkDemo.java
package com.study.es_hrset_client; import java.io.IOException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.DocWriteRequest; import org.elasticsearch.action.DocWriteResponse; import org.elasticsearch.action.bulk.BulkItemResponse; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; /** * * @Description: 批量索引文档,即批量往索引里面放入文档数据.类似于数据库里面批量向表里面插入多行数据,一行数据就是一个文档 * @author lgs * @date 2018年6月23日 * */ public class BulkDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建批量操作请求 BulkRequest request = new BulkRequest(); request.add(new IndexRequest("mess", "_doc", "1") .source(XContentType.JSON,"field", "foo")); request.add(new IndexRequest("mess", "_doc", "2") .source(XContentType.JSON,"field", "bar")); request.add(new IndexRequest("mess", "_doc", "3") .source(XContentType.JSON,"field", "baz")); /* request.add(new DeleteRequest("mess", "_doc", "3")); request.add(new UpdateRequest("mess", "_doc", "2") .doc(XContentType.JSON,"other", "test")); request.add(new IndexRequest("mess", "_doc", "4") .source(XContentType.JSON,"field", "baz")); */ // 2、可选的设置 /* request.timeout("2m"); request.setRefreshPolicy("wait_for"); request.waitForActiveShards(2); */ //3、发送请求 // 同步请求 BulkResponse bulkResponse = client.bulk(request); //4、处理响应 if(bulkResponse != null) { for (BulkItemResponse bulkItemResponse : bulkResponse) { DocWriteResponse itemResponse = bulkItemResponse.getResponse(); if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX || bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) { IndexResponse indexResponse = (IndexResponse) itemResponse; //TODO 新增成功的处理 } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) { UpdateResponse updateResponse = (UpdateResponse) itemResponse; //TODO 修改成功的处理 } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) { DeleteResponse deleteResponse = (DeleteResponse) itemResponse; //TODO 删除成功的处理 } } } //异步方式发送批量操作请求 /* ActionListener<BulkResponse> listener = new ActionListener<BulkResponse>() { @Override public void onResponse(BulkResponse bulkResponse) { } @Override public void onFailure(Exception e) { } }; client.bulkAsync(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
5. search
搜索数据
SearchDemo.java
package com.study.es_hrset_client; import java.io.IOException; import java.util.List; import java.util.Map; import java.util.concurrent.TimeUnit; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.search.ShardSearchFailure; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.suggest.Suggest; import org.elasticsearch.search.suggest.term.TermSuggestion; /** * * @Description: 搜索数据 * @author lgs * @date 2018年6月23日 * */ public class SearchDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("_doc"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //构造QueryBuilder /*QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy") .fuzziness(Fuzziness.AUTO) .prefixLength(3) .maxExpansions(10); sourceBuilder.query(matchQueryBuilder);*/ sourceBuilder.query(QueryBuilders.termQuery("age", 24)); sourceBuilder.from(0); sourceBuilder.size(10); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //是否返回_source字段 //sourceBuilder.fetchSource(false); //设置返回哪些字段 /*String[] includeFields = new String[] {"title", "user", "innerObject.*"}; String[] excludeFields = new String[] {"_type"}; sourceBuilder.fetchSource(includeFields, excludeFields);*/ //指定排序 //sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC)); //sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); // 设置返回 profile //sourceBuilder.profile(true); //将请求体加入到请求中 searchRequest.source(sourceBuilder); // 可选的设置 //searchRequest.routing("routing"); // 高亮设置 /* HighlightBuilder highlightBuilder = new HighlightBuilder(); HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title"); highlightTitle.highlighterType("unified"); highlightBuilder.field(highlightTitle); HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user"); highlightBuilder.field(highlightUser); sourceBuilder.highlighter(highlightBuilder);*/ //加入聚合 /*TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company") .field("company.keyword"); aggregation.subAggregation(AggregationBuilders.avg("average_age") .field("age")); sourceBuilder.aggregation(aggregation);*/ //做查询建议 /*SuggestionBuilder termSuggestionBuilder = SuggestBuilders.termSuggestion("user").text("kmichy"); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder);*/ //3、发送请求 SearchResponse searchResponse = client.search(searchRequest); //4、处理响应 //搜索结果状态信息 RestStatus status = searchResponse.status(); TimeValue took = searchResponse.getTook(); Boolean terminatedEarly = searchResponse.isTerminatedEarly(); boolean timedOut = searchResponse.isTimedOut(); //分片搜索情况 int totalShards = searchResponse.getTotalShards(); int successfulShards = searchResponse.getSuccessfulShards(); int failedShards = searchResponse.getFailedShards(); for (ShardSearchFailure failure : searchResponse.getShardFailures()) { // failures should be handled here } //处理搜索命中文档结果 SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits(); float maxScore = hits.getMaxScore(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { // do something with the SearchHit String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); //取_source字段值 String sourceAsString = hit.getSourceAsString(); //取成json串 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 取成map对象 //从map中取字段值 /* String documentTitle = (String) sourceAsMap.get("title"); List<Object> users = (List<Object>) sourceAsMap.get("user"); Map<String, Object> innerObject = (Map<String, Object>) sourceAsMap.get("innerObject"); */ logger.info("index:" + index + " type:" + type + " id:" + id); logger.info(sourceAsString); //取高亮结果 /*Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField highlight = highlightFields.get("title"); Text[] fragments = highlight.fragments(); String fragmentString = fragments[0].string();*/ } // 获取聚合结果 /* Aggregations aggregations = searchResponse.getAggregations(); Terms byCompanyAggregation = aggregations.get("by_company"); Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic"); Avg averageAge = elasticBucket.getAggregations().get("average_age"); double avg = averageAge.getValue(); */ // 获取建议结果 /*Suggest suggest = searchResponse.getSuggest(); TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user"); for (TermSuggestion.Entry entry : termSuggestion.getEntries()) { for (TermSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); } } */ //异步方式发送获查询请求 /* ActionListener<SearchResponse> listener = new ActionListener<SearchResponse>() { @Override public void onResponse(SearchResponse getResponse) { //结果获取 } @Override public void onFailure(Exception e) { //失败处理 } }; client.searchAsync(searchRequest, listener); */ } catch (IOException e) { logger.error(e); } } }
6. highlight 高亮
HighlightDemo.java
package com.study.es_hrset_client; import java.io.IOException; import java.util.Map; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.text.Text; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightField; /** * * @Description: 高亮 * @author lgs * @date 2018年6月23日 * */ public class HighlightDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建search请求 SearchRequest searchRequest = new SearchRequest("hl_test"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //构造QueryBuilder QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "lucene solr"); sourceBuilder.query(matchQueryBuilder); //分页设置 /*sourceBuilder.from(0); sourceBuilder.size(5); ;*/ // 高亮设置 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false).field("title").field("content") .preTags("<strong>").postTags("</strong>"); //不同字段可有不同设置,如不同标签 /*HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title"); highlightTitle.preTags("<strong>").postTags("</strong>"); highlightBuilder.field(highlightTitle); HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("content"); highlightContent.preTags("<b>").postTags("</b>"); highlightBuilder.field(highlightContent).requireFieldMatch(false);*/ sourceBuilder.highlighter(highlightBuilder); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest); //4、处理响应 if(RestStatus.OK.equals(searchResponse.status())) { //处理搜索命中文档结果 SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); //取_source字段值 //String sourceAsString = hit.getSourceAsString(); //取成json串 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 取成map对象 //从map中取字段值 /*String title = (String) sourceAsMap.get("title"); String content = (String) sourceAsMap.get("content"); */ logger.info("index:" + index + " type:" + type + " id:" + id); logger.info("sourceMap : " + sourceAsMap); //取高亮结果 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField highlight = highlightFields.get("title"); if(highlight != null) { Text[] fragments = highlight.fragments(); //多值的字段会有多个值 if(fragments != null) { String fragmentString = fragments[0].string(); logger.info("title highlight : " + fragmentString); //可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用 //sourceAsMap.put("title", fragmentString); } } highlight = highlightFields.get("content"); if(highlight != null) { Text[] fragments = highlight.fragments(); //多值的字段会有多个值 if(fragments != null) { String fragmentString = fragments[0].string(); logger.info("content highlight : " + fragmentString); //可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用 //sourceAsMap.put("content", fragmentString); } } } } } catch (IOException e) { logger.error(e); } } }
7. suggest 查询建议
SuggestDemo.java
package com.study.es_hrset_client; import java.io.IOException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.suggest.Suggest; import org.elasticsearch.search.suggest.SuggestBuilder; import org.elasticsearch.search.suggest.SuggestBuilders; import org.elasticsearch.search.suggest.SuggestionBuilder; import org.elasticsearch.search.suggest.completion.CompletionSuggestion; import org.elasticsearch.search.suggest.term.TermSuggestion; /** * * @Description: 查询建议 * @author lgs * @date 2018年6月23日 * */ public class SuggestDemo { private static Logger logger = LogManager.getRootLogger(); //词项建议拼写检查,检查用户的拼写是否错误,如果有错给用户推荐正确的词,appel->apple public static void termSuggest() { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("mess"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //做查询建议 //词项建议 SuggestionBuilder termSuggestionBuilder = SuggestBuilders.termSuggestion("user").text("kmichy"); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取建议结果 Suggest suggest = searchResponse.getSuggest(); TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user"); for (TermSuggestion.Entry entry : termSuggestion.getEntries()) { logger.info("text: " + entry.getText().string()); for (TermSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); logger.info(" suggest option : " + suggestText); } } } /* "suggest": { "my-suggestion": [ { "text": "tring", "offset": 0, "length": 5, "options": [ { "text": "trying", "score": 0.8, "freq": 1 } ] }, { "text": "out", "offset": 6, "length": 3, "options": [] }, { "text": "elasticsearch", "offset": 10, "length": 13, "options": [] } ] }*/ } catch (IOException e) { logger.error(e); } } //自动补全,根据用户的输入联想到可能的词或者短语 public static void completionSuggester() { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("music"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //做查询建议 //自动补全 /*POST music/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "lucene s", "completion" : { "field" : "suggest" , "skip_duplicates": true } } } }*/ SuggestionBuilder termSuggestionBuilder = SuggestBuilders.completionSuggestion("suggest").prefix("lucene s") .skipDuplicates(true); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("song-suggest", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取建议结果 Suggest suggest = searchResponse.getSuggest(); CompletionSuggestion termSuggestion = suggest.getSuggestion("song-suggest"); for (CompletionSuggestion.Entry entry : termSuggestion.getEntries()) { logger.info("text: " + entry.getText().string()); for (CompletionSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); logger.info(" suggest option : " + suggestText); } } } } catch (IOException e) { logger.error(e); } } public static void main(String[] args) { termSuggest(); logger.info("--------------------------------------"); completionSuggester(); } }
8. aggregation 聚合分析
AggregationDemo.java
package com.study.es_hrset_client; import java.io.IOException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.Aggregations; import org.elasticsearch.search.aggregations.BucketOrder; import org.elasticsearch.search.aggregations.bucket.terms.Terms; import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.aggregations.metrics.avg.Avg; import org.elasticsearch.search.builder.SearchSourceBuilder; /** * * @Description: 聚合分析 * @author lgs * @date 2018年6月23日 * */ public class AggregationDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (RestHighLevelClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("bank"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //加入聚合 //字段值项分组聚合 TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_age") .field("age").order(BucketOrder.aggregation("average_balance", true)); //计算每组的平均balance指标 aggregation.subAggregation(AggregationBuilders.avg("average_balance") .field("balance")); sourceBuilder.aggregation(aggregation); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms byAgeAggregation = aggregations.get("by_age"); logger.info("aggregation by_age 结果"); logger.info("docCountError: " + byAgeAggregation.getDocCountError()); logger.info("sumOfOtherDocCounts: " + byAgeAggregation.getSumOfOtherDocCounts()); logger.info("------------------------------------"); for(Bucket buck : byAgeAggregation.getBuckets()) { logger.info("key: " + buck.getKeyAsNumber()); logger.info("docCount: " + buck.getDocCount()); logger.info("docCountError: " + buck.getDocCountError()); //取子聚合 Avg averageBalance = buck.getAggregations().get("average_balance"); logger.info("average_balance: " + averageBalance.getValue()); logger.info("------------------------------------"); } //直接用key 来去分组 /*Bucket elasticBucket = byCompanyAggregation.getBucketByKey("24"); Avg averageAge = elasticBucket.getAggregations().get("average_age"); double avg = averageAge.getValue();*/ } } catch (IOException e) { logger.error(e); } } }
9. 官网资料
各种查询对应的QueryBuilder:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-query-builders.html
各种聚合对应的AggregationBuilder:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-aggregation-builders.html
四、Java Client
1. Java Client 说明
java client 使用 TransportClient,各种操作本质上都是异步的(可以用 listener,或返回 Future )。
注意:ES的发展规划中在7.0版本开始将废弃 TransportClient,8.0版本中将完全移除 TransportClient,取而代之的是High Level REST Client。
High Level REST Client 中的操作API和java client 大多是一样的。
2. 官方学习链接
https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html
3. 兼容性说明
请使用与服务端ES版本一致的客户端版本
4. Java Client maven 集成
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>6.2.4</version> </dependency>
5. Java Client logger 日志器说明
使用的是 log4j2 日志组件。
如果要使用其他的日志组件,可使用slf4j作桥
6. Init Client

Init Client setting 可用参数说明:
cluster.name
指定集群的名字,如果集群的名字不是默认的elasticsearch,需指定。
client.transport.sniff
设置为true,将自动嗅探整个集群,自动加入集群的节点到连接列表中。
client.transport.ignore_cluster_name
Set to true to ignore cluster name validation of connected nodes. (since 0.19.4)
client.transport.ping_timeout
The time to wait for a ping response from a node. Defaults to 5s.
client.transport.nodes_sampler_interval
How often to sample / ping the nodes listed and connected. Defaults to 5s.
五、Java Client使用示例
注意:TransPort客户端的使用和RESTful风格的使用基本一致,除了获取客户端不一样,还有发送请求有的不一样外
准备:
编写示例之前首先在maven工程里面引入和ES服务端版本一样的Java客户端
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>6.2.4</version> </dependency>
给定集群的多个节点地址,将客户端负载均衡地向这个节点地址集发请求:
InitDemo.java
package com.study.es_java_client; import java.net.InetAddress; import java.net.UnknownHostException; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.transport.TransportAddress; import org.elasticsearch.transport.client.PreBuiltTransportClient; public class InitDemo { private static TransportClient client; public static TransportClient getClient() throws UnknownHostException { if(client == null) { //client = new PreBuiltTransportClient(Settings.EMPTY) // 连接集群的设置 Settings settings = Settings.builder() //.put("cluster.name", "myClusterName") //如果集群的名字不是默认的elasticsearch,需指定 .put("client.transport.sniff", true) //自动嗅探 .build(); client = new PreBuiltTransportClient(settings) //.addTransportAddress(new TransportAddress(InetAddress.getByName("localhost"), 9300)); .addTransportAddress(new TransportAddress(InetAddress.getByName("127.0.0.1"), 9300)); //可用连接设置参数说明 /* cluster.name 指定集群的名字,如果集群的名字不是默认的elasticsearch,需指定。 client.transport.sniff 设置为true,将自动嗅探整个集群,自动加入集群的节点到连接列表中。 client.transport.ignore_cluster_name Set to true to ignore cluster name validation of connected nodes. (since 0.19.4) client.transport.ping_timeout The time to wait for a ping response from a node. Defaults to 5s. client.transport.nodes_sampler_interval How often to sample / ping the nodes listed and connected. Defaults to 5s. */ } return client; } }
注意使用ES的客户端时类比之前我们在Kibana进行的ES的相关操作,这样使用起来更加有效果
1. Create index 创建索引
CreateIndexDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.concurrent.ExecutionException; import org.elasticsearch.action.admin.indices.alias.Alias; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.xcontent.XContentType; public class CreateIndexDemo { public static void main(String[] args) { //这里和RESTful风格不同 try (TransportClient client = InitDemo.getClient();) { // 1、创建 创建索引request CreateIndexRequest request = new CreateIndexRequest("mess"); // 2、设置索引的settings request.settings(Settings.builder().put("index.number_of_shards", 3) // 分片数 .put("index.number_of_replicas", 2) // 副本数 .put("analysis.analyzer.default.tokenizer", "ik_smart") // 默认分词器 ); // 3、设置索引的mappings request.mapping("_doc", " {\n" + " \"_doc\": {\n" + " \"properties\": {\n" + " \"message\": {\n" + " \"type\": \"text\"\n" + " }\n" + " }\n" + " }\n" + " }", XContentType.JSON); // 4、 设置索引的别名 request.alias(new Alias("mmm")); // 5、 发送请求 这里和RESTful风格不同 CreateIndexResponse createIndexResponse = client.admin().indices() .create(request).get(); // 6、处理响应 boolean acknowledged = createIndexResponse.isAcknowledged(); boolean shardsAcknowledged = createIndexResponse .isShardsAcknowledged(); System.out.println("acknowledged = " + acknowledged); System.out.println("shardsAcknowledged = " + shardsAcknowledged); // listener方式发送请求 /*ActionListener<CreateIndexResponse> listener = new ActionListener<CreateIndexResponse>() { @Override public void onResponse( CreateIndexResponse createIndexResponse) { // 6、处理响应 boolean acknowledged = createIndexResponse.isAcknowledged(); boolean shardsAcknowledged = createIndexResponse .isShardsAcknowledged(); System.out.println("acknowledged = " + acknowledged); System.out.println( "shardsAcknowledged = " + shardsAcknowledged); } @Override public void onFailure(Exception e) { System.out.println("创建索引异常:" + e.getMessage()); } }; client.admin().indices().create(request, listener); */ } catch (IOException | InterruptedException | ExecutionException e) { e.printStackTrace(); } } }
2. index document
索引文档,即往索引里面放入文档数据.类似于数据库里面向表里面插入一行数据,一行数据就是一个文档
IndexDocumentDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.ElasticsearchException; import org.elasticsearch.action.DocWriteResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.support.replication.ReplicationResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.rest.RestStatus; public class IndexDocumentDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { //这里和RESTful风格不同 try (TransportClient client = InitDemo.getClient();) { // 1、创建索引请求 IndexRequest request = new IndexRequest( "mess", //索引 "_doc", // mapping type "11"); //文档id // 2、准备文档数据 // 方式一:直接给JSON串 String jsonString = "{" + "\"user\":\"kimchy\"," + "\"postDate\":\"2013-01-30\"," + "\"message\":\"trying out Elasticsearch\"" + "}"; request.source(jsonString, XContentType.JSON); // 方式二:以map对象来表示文档 /* Map<String, Object> jsonMap = new HashMap<>(); jsonMap.put("user", "kimchy"); jsonMap.put("postDate", new Date()); jsonMap.put("message", "trying out Elasticsearch"); request.source(jsonMap); */ // 方式三:用XContentBuilder来构建文档 /* XContentBuilder builder = XContentFactory.jsonBuilder(); builder.startObject(); { builder.field("user", "kimchy"); builder.field("postDate", new Date()); builder.field("message", "trying out Elasticsearch"); } builder.endObject(); request.source(builder); */ // 方式四:直接用key-value对给出 /* request.source("user", "kimchy", "postDate", new Date(), "message", "trying out Elasticsearch"); */ //3、其他的一些可选设置 /* request.routing("routing"); //设置routing值 request.timeout(TimeValue.timeValueSeconds(1)); //设置主分片等待时长 request.setRefreshPolicy("wait_for"); //设置重刷新策略 request.version(2); //设置版本号 request.opType(DocWriteRequest.OpType.CREATE); //操作类别 */ //4、发送请求 IndexResponse indexResponse = null; try { //方式一: 用client.index 方法,返回是 ActionFuture<IndexResponse>,再调用get获取响应结果 indexResponse = client.index(request).get(); //方式二:client提供了一个 prepareIndex方法,内部为我们创建IndexRequest /*IndexResponse indexResponse = client.prepareIndex("mess","_doc","11") .setSource(jsonString, XContentType.JSON) .get();*/ //方式三:request + listener //client.index(request, listener); } catch(ElasticsearchException e) { // 捕获,并处理异常 //判断是否版本冲突、create但文档已存在冲突 if (e.status() == RestStatus.CONFLICT) { logger.error("冲突了,请在此写冲突处理逻辑!\n" + e.getDetailedMessage()); } logger.error("索引异常", e); }catch (InterruptedException | ExecutionException e) { logger.error("索引异常", e); } //5、处理响应 if(indexResponse != null) { String index = indexResponse.getIndex(); String type = indexResponse.getType(); String id = indexResponse.getId(); long version = indexResponse.getVersion(); if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) { System.out.println("新增文档成功,处理逻辑代码写到这里。"); } else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) { System.out.println("修改文档成功,处理逻辑代码写到这里。"); } // 分片处理信息 ReplicationResponse.ShardInfo shardInfo = indexResponse.getShardInfo(); if (shardInfo.getTotal() != shardInfo.getSuccessful()) { } // 如果有分片副本失败,可以获得失败原因信息 if (shardInfo.getFailed() > 0) { for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) { String reason = failure.reason(); System.out.println("副本失败原因:" + reason); } } } //listener 方式 /*ActionListener<IndexResponse> listener = new ActionListener<IndexResponse>() { @Override public void onResponse(IndexResponse indexResponse) { } @Override public void onFailure(Exception e) { } }; client.index(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
3. get document
获取文档数据
GetDocumentDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.Map; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.ElasticsearchException; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.Strings; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.fetch.subphase.FetchSourceContext; public class GetDocumentDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { //这里和RESTful风格不同 try (TransportClient client = InitDemo.getClient();) { // 1、创建获取文档请求 GetRequest request = new GetRequest( "mess", //索引 "_doc", // mapping type "11"); //文档id // 2、可选的设置 //request.routing("routing"); //request.version(2); //request.fetchSourceContext(new FetchSourceContext(false)); //是否获取_source字段 //选择返回的字段 String[] includes = new String[]{"message", "*Date"}; String[] excludes = Strings.EMPTY_ARRAY; FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes); request.fetchSourceContext(fetchSourceContext); //也可写成这样 /*String[] includes = Strings.EMPTY_ARRAY; String[] excludes = new String[]{"message"}; FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes); request.fetchSourceContext(fetchSourceContext);*/ // 取stored字段 /*request.storedFields("message"); GetResponse getResponse = client.get(request); String message = getResponse.getField("message").getValue();*/ //3、发送请求 GetResponse getResponse = null; try { getResponse = client.get(request).get(); } catch (ElasticsearchException e) { if (e.status() == RestStatus.NOT_FOUND) { logger.error("没有找到该id的文档" ); } if (e.status() == RestStatus.CONFLICT) { logger.error("获取时版本冲突了,请在此写冲突处理逻辑!" ); } logger.error("获取文档异常", e); }catch (InterruptedException | ExecutionException e) { logger.error("索引异常", e); } //4、处理响应 if(getResponse != null) { String index = getResponse.getIndex(); String type = getResponse.getType(); String id = getResponse.getId(); if (getResponse.isExists()) { // 文档存在 long version = getResponse.getVersion(); String sourceAsString = getResponse.getSourceAsString(); //结果取成 String Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); // 结果取成Map byte[] sourceAsBytes = getResponse.getSourceAsBytes(); //结果取成字节数组 logger.info("index:" + index + " type:" + type + " id:" + id); logger.info(sourceAsString); } else { logger.error("没有找到该id的文档" ); } } //异步方式发送获取文档请求 /* ActionListener<GetResponse> listener = new ActionListener<GetResponse>() { @Override public void onResponse(GetResponse getResponse) { } @Override public void onFailure(Exception e) { } }; client.getAsync(request, listener); */ } catch (IOException e) { e.printStackTrace(); } } }
4. Bulk
批量索引文档,即批量往索引里面放入文档数据.类似于数据库里面批量向表里面插入多行数据,一行数据就是一个文档
BulkDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.DocWriteRequest; import org.elasticsearch.action.DocWriteResponse; import org.elasticsearch.action.bulk.BulkItemResponse; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.xcontent.XContentType; public class BulkDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { //这里和RESTful风格不同 try (TransportClient client = InitDemo.getClient();) { // 1、创建批量操作请求 BulkRequest request = new BulkRequest(); request.add(new IndexRequest("mess", "_doc", "1") .source(XContentType.JSON,"field", "foo")); request.add(new IndexRequest("mess", "_doc", "2") .source(XContentType.JSON,"field", "bar")); request.add(new IndexRequest("mess", "_doc", "3") .source(XContentType.JSON,"field", "baz")); /* request.add(new DeleteRequest("mess", "_doc", "3")); request.add(new UpdateRequest("mess", "_doc", "2") .doc(XContentType.JSON,"other", "test")); request.add(new IndexRequest("mess", "_doc", "4") .source(XContentType.JSON,"field", "baz")); */ // 2、可选的设置 /* request.timeout("2m"); request.setRefreshPolicy("wait_for"); request.waitForActiveShards(2); */ //3、发送请求 // 同步请求 BulkResponse bulkResponse = client.bulk(request).get(); //4、处理响应 if(bulkResponse != null) { for (BulkItemResponse bulkItemResponse : bulkResponse) { DocWriteResponse itemResponse = bulkItemResponse.getResponse(); if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX || bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) { IndexResponse indexResponse = (IndexResponse) itemResponse; //TODO 新增成功的处理 } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) { UpdateResponse updateResponse = (UpdateResponse) itemResponse; //TODO 修改成功的处理 } else if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) { DeleteResponse deleteResponse = (DeleteResponse) itemResponse; //TODO 删除成功的处理 } } } //异步方式发送批量操作请求 /* ActionListener<BulkResponse> listener = new ActionListener<BulkResponse>() { @Override public void onResponse(BulkResponse bulkResponse) { } @Override public void onFailure(Exception e) { } }; client.bulkAsync(request, listener); */ } catch (IOException | InterruptedException | ExecutionException e) { e.printStackTrace(); } } }
5. search
搜索数据
SearchDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.Map; import java.util.concurrent.ExecutionException; import java.util.concurrent.TimeUnit; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.search.ShardSearchFailure; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; public class SearchDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (TransportClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("_doc"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //构造QueryBuilder /*QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy") .fuzziness(Fuzziness.AUTO) .prefixLength(3) .maxExpansions(10); sourceBuilder.query(matchQueryBuilder);*/ sourceBuilder.query(QueryBuilders.termQuery("age", 24)); sourceBuilder.from(0); sourceBuilder.size(10); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //是否返回_source字段 //sourceBuilder.fetchSource(false); //设置返回哪些字段 /*String[] includeFields = new String[] {"title", "user", "innerObject.*"}; String[] excludeFields = new String[] {"_type"}; sourceBuilder.fetchSource(includeFields, excludeFields);*/ //指定排序 //sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC)); //sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); // 设置返回 profile //sourceBuilder.profile(true); //将请求体加入到请求中 searchRequest.source(sourceBuilder); // 可选的设置 //searchRequest.routing("routing"); // 高亮设置 /* HighlightBuilder highlightBuilder = new HighlightBuilder(); HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title"); highlightTitle.highlighterType("unified"); highlightBuilder.field(highlightTitle); HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user"); highlightBuilder.field(highlightUser); sourceBuilder.highlighter(highlightBuilder);*/ //加入聚合 /*TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company") .field("company.keyword"); aggregation.subAggregation(AggregationBuilders.avg("average_age") .field("age")); sourceBuilder.aggregation(aggregation);*/ //做查询建议 /*SuggestionBuilder termSuggestionBuilder = SuggestBuilders.termSuggestion("user").text("kmichy"); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder);*/ //3、发送请求 SearchResponse searchResponse = client.search(searchRequest).get(); //4、处理响应 //搜索结果状态信息 RestStatus status = searchResponse.status(); TimeValue took = searchResponse.getTook(); Boolean terminatedEarly = searchResponse.isTerminatedEarly(); boolean timedOut = searchResponse.isTimedOut(); //分片搜索情况 int totalShards = searchResponse.getTotalShards(); int successfulShards = searchResponse.getSuccessfulShards(); int failedShards = searchResponse.getFailedShards(); for (ShardSearchFailure failure : searchResponse.getShardFailures()) { // failures should be handled here } //处理搜索命中文档结果 SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits(); float maxScore = hits.getMaxScore(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { // do something with the SearchHit String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); //取_source字段值 String sourceAsString = hit.getSourceAsString(); //取成json串 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 取成map对象 //从map中取字段值 /* String documentTitle = (String) sourceAsMap.get("title"); List<Object> users = (List<Object>) sourceAsMap.get("user"); Map<String, Object> innerObject = (Map<String, Object>) sourceAsMap.get("innerObject"); */ logger.info("index:" + index + " type:" + type + " id:" + id); logger.info(sourceAsString); //取高亮结果 /*Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField highlight = highlightFields.get("title"); Text[] fragments = highlight.fragments(); String fragmentString = fragments[0].string();*/ } // 获取聚合结果 /* Aggregations aggregations = searchResponse.getAggregations(); Terms byCompanyAggregation = aggregations.get("by_company"); Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic"); Avg averageAge = elasticBucket.getAggregations().get("average_age"); double avg = averageAge.getValue(); */ // 获取建议结果 /*Suggest suggest = searchResponse.getSuggest(); TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user"); for (TermSuggestion.Entry entry : termSuggestion.getEntries()) { for (TermSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); } } */ //异步方式发送获查询请求 /* ActionListener<SearchResponse> listener = new ActionListener<SearchResponse>() { @Override public void onResponse(SearchResponse getResponse) { //结果获取 } @Override public void onFailure(Exception e) { //失败处理 } }; client.searchAsync(searchRequest, listener); */ } catch (IOException | InterruptedException | ExecutionException e) { logger.error(e); } } }
6. highlight 高亮
HighlightDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.Map; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.text.Text; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.SearchHits; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.fetch.subphase.highlight.HighlightField; public class HighlightDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (TransportClient client = InitDemo.getClient();) { // 1、创建search请求 SearchRequest searchRequest = new SearchRequest("hl_test"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //构造QueryBuilder QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "lucene solr"); sourceBuilder.query(matchQueryBuilder); //分页设置 /*sourceBuilder.from(0); sourceBuilder.size(5); ;*/ // 高亮设置 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.requireFieldMatch(false).field("title").field("content") .preTags("<strong>").postTags("</strong>"); //不同字段可有不同设置,如不同标签 /*HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title"); highlightTitle.preTags("<strong>").postTags("</strong>"); highlightBuilder.field(highlightTitle); HighlightBuilder.Field highlightContent = new HighlightBuilder.Field("content"); highlightContent.preTags("<b>").postTags("</b>"); highlightBuilder.field(highlightContent).requireFieldMatch(false);*/ sourceBuilder.highlighter(highlightBuilder); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest).get(); //4、处理响应 if(RestStatus.OK.equals(searchResponse.status())) { //处理搜索命中文档结果 SearchHits hits = searchResponse.getHits(); long totalHits = hits.getTotalHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { String index = hit.getIndex(); String type = hit.getType(); String id = hit.getId(); float score = hit.getScore(); //取_source字段值 //String sourceAsString = hit.getSourceAsString(); //取成json串 Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 取成map对象 //从map中取字段值 /*String title = (String) sourceAsMap.get("title"); String content = (String) sourceAsMap.get("content"); */ logger.info("index:" + index + " type:" + type + " id:" + id); logger.info("sourceMap : " + sourceAsMap); //取高亮结果 Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField highlight = highlightFields.get("title"); if(highlight != null) { Text[] fragments = highlight.fragments(); //多值的字段会有多个值 if(fragments != null) { String fragmentString = fragments[0].string(); logger.info("title highlight : " + fragmentString); //可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用 //sourceAsMap.put("title", fragmentString); } } highlight = highlightFields.get("content"); if(highlight != null) { Text[] fragments = highlight.fragments(); //多值的字段会有多个值 if(fragments != null) { String fragmentString = fragments[0].string(); logger.info("content highlight : " + fragmentString); //可用高亮字符串替换上面sourceAsMap中的对应字段返回到上一级调用 //sourceAsMap.put("content", fragmentString); } } } } } catch (IOException | InterruptedException | ExecutionException e) { logger.error(e); } } }
7. suggest 查询建议
SuggestDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.elasticsearch.search.suggest.Suggest; import org.elasticsearch.search.suggest.SuggestBuilder; import org.elasticsearch.search.suggest.SuggestBuilders; import org.elasticsearch.search.suggest.SuggestionBuilder; import org.elasticsearch.search.suggest.completion.CompletionSuggestion; import org.elasticsearch.search.suggest.term.TermSuggestion; public class SuggestDemo { private static Logger logger = LogManager.getRootLogger(); //拼写检查 public static void termSuggest(TransportClient client) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("mess"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //做查询建议 //词项建议 SuggestionBuilder termSuggestionBuilder = SuggestBuilders.termSuggestion("user").text("kmichy"); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder); searchRequest.source(sourceBuilder); try{ //3、发送请求 SearchResponse searchResponse = client.search(searchRequest).get(); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取建议结果 Suggest suggest = searchResponse.getSuggest(); TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user"); for (TermSuggestion.Entry entry : termSuggestion.getEntries()) { logger.info("text: " + entry.getText().string()); for (TermSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); logger.info(" suggest option : " + suggestText); } } } } catch (InterruptedException | ExecutionException e) { logger.error(e); } /* "suggest": { "my-suggestion": [ { "text": "tring", "offset": 0, "length": 5, "options": [ { "text": "trying", "score": 0.8, "freq": 1 } ] }, { "text": "out", "offset": 6, "length": 3, "options": [] }, { "text": "elasticsearch", "offset": 10, "length": 13, "options": [] } ] }*/ } //自动补全 public static void completionSuggester(TransportClient client) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("music"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //做查询建议 //自动补全 /*POST music/_search?pretty { "suggest": { "song-suggest" : { "prefix" : "lucene s", "completion" : { "field" : "suggest" , "skip_duplicates": true } } } }*/ SuggestionBuilder termSuggestionBuilder = SuggestBuilders.completionSuggestion("suggest").prefix("lucene s") .skipDuplicates(true); SuggestBuilder suggestBuilder = new SuggestBuilder(); suggestBuilder.addSuggestion("song-suggest", termSuggestionBuilder); sourceBuilder.suggest(suggestBuilder); searchRequest.source(sourceBuilder); try { //3、发送请求 SearchResponse searchResponse = client.search(searchRequest).get(); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取建议结果 Suggest suggest = searchResponse.getSuggest(); CompletionSuggestion termSuggestion = suggest.getSuggestion("song-suggest"); for (CompletionSuggestion.Entry entry : termSuggestion.getEntries()) { logger.info("text: " + entry.getText().string()); for (CompletionSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); logger.info(" suggest option : " + suggestText); } } } } catch (InterruptedException | ExecutionException e) { logger.error(e); } } public static void main(String[] args) { try (TransportClient client = InitDemo.getClient();) { termSuggest(client); logger.info("--------------------------------------"); completionSuggester(client); } catch (IOException e) { logger.error(e); } } }
8. aggregation 聚合分析
AggregationDemo.java
package com.study.es_java_client; import java.io.IOException; import java.util.concurrent.ExecutionException; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.rest.RestStatus; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.Aggregations; import org.elasticsearch.search.aggregations.BucketOrder; import org.elasticsearch.search.aggregations.bucket.terms.Terms; import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.aggregations.metrics.avg.Avg; import org.elasticsearch.search.builder.SearchSourceBuilder; public class AggregationDemo { private static Logger logger = LogManager.getRootLogger(); public static void main(String[] args) { try (TransportClient client = InitDemo.getClient();) { // 1、创建search请求 //SearchRequest searchRequest = new SearchRequest(); SearchRequest searchRequest = new SearchRequest("bank"); // 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.size(0); //加入聚合 //字段值项分组聚合 TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_age") .field("age").order(BucketOrder.aggregation("average_balance", true)); //计算每组的平均balance指标 aggregation.subAggregation(AggregationBuilders.avg("average_balance") .field("balance")); sourceBuilder.aggregation(aggregation); searchRequest.source(sourceBuilder); //3、发送请求 SearchResponse searchResponse = client.search(searchRequest).get(); //4、处理响应 //搜索结果状态信息 if(RestStatus.OK.equals(searchResponse.status())) { // 获取聚合结果 Aggregations aggregations = searchResponse.getAggregations(); Terms byAgeAggregation = aggregations.get("by_age"); logger.info("aggregation by_age 结果"); logger.info("docCountError: " + byAgeAggregation.getDocCountError()); logger.info("sumOfOtherDocCounts: " + byAgeAggregation.getSumOfOtherDocCounts()); logger.info("------------------------------------"); for(Bucket buck : byAgeAggregation.getBuckets()) { logger.info("key: " + buck.getKeyAsNumber()); logger.info("docCount: " + buck.getDocCount()); //logger.info("docCountError: " + buck.getDocCountError()); //取子聚合 Avg averageBalance = buck.getAggregations().get("average_balance"); logger.info("average_balance: " + averageBalance.getValue()); logger.info("------------------------------------"); } //直接用key 来去分组 /*Bucket elasticBucket = byCompanyAggregation.getBucketByKey("24"); Avg averageAge = elasticBucket.getAggregations().get("average_age"); double avg = averageAge.getValue();*/ } } catch (IOException | InterruptedException | ExecutionException e) { logger.error(e); } } }
9. 官网文档
Document API 文档操作API:
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.2/java-docs.html
Search API:
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.2/java-search.html
六、Spring Data Elasticsearch
ES与Spring集成使用,可以作为了解,个人建议还是使用原生的ES的java客户端
官网链接:
https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/
代码库:
https://github.com/spring-projects/spring-data-elasticsearch
七、源代码获取地址
https://github.com/leeSmall/Elasticsearch-Java-client-api

 浙公网安备 33010602011771号
浙公网安备 33010602011771号