
Solr系列六:solr搜索详解优化查询结果(分面搜索、搜索结果高亮、查询建议、折叠展开结果、结果分组、其他搜索特性介绍)
一、分面搜索
1. 什么是分面搜索?
分面搜索:在搜索结果的基础上进行按指定维度的统计,以展示搜索结果的另一面信息。类似于SQL语句的group by
分面搜索的示例:
http://localhost:8983/solr/techproducts/browse
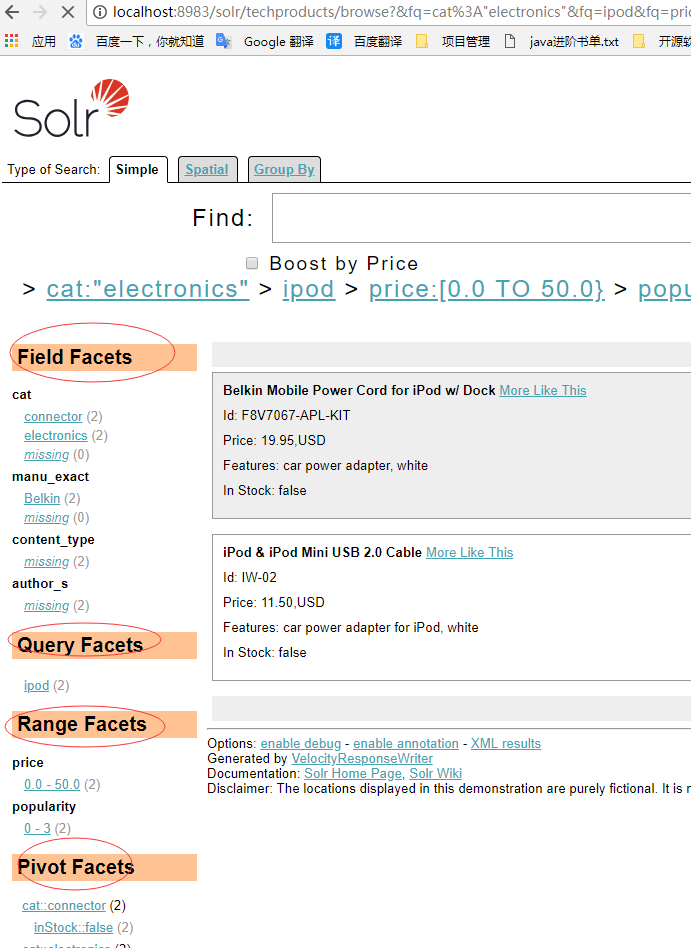
2. Solr中支持的分面查询
字段分面、区间分面、决策树分面、查询分面
2.1 字段分面
执行搜索时,根据查询请求返回特定分面字段中找到的唯一值以及找到的文档数。
通用查询参数:
facet:true/false 对当前搜索是否启用分面
facet.query:指定一个额外的分面查询语句
字段分面查询参数:
facet.field:指定对哪个字段进行分面计算。该参数可以多次指定以返回多个字段方面。字段需是索引字段。
facet.sort:分面结果的排序方式:count:根据统计数量排,index: 索引的词典顺序
facet.limit:确定每个分面返回多少个唯一分面值。可取值:整数>=-1,-1表示不限制,默认100。
facet.offset:对分面值进行分页,指定页偏移。 >=0 默认0。
facet.prefix:指定限制字段分面值必须以xxx开头,用以筛选分面值。
facet.missing:true/false,是否在分面字段中返回所有不包含值(值为缺失)的文档计数。
facet.mincount:指定分面结果中的分面值的统计数量>=mincount的才返回
示例:
sort、limit、offset、prefix、missing、mincount 可根据字段指定: f.filedname.facet.sort=count
2.2 区间分面
区间分面将数值或时间字段值分成一些区间段,按区间段进行统计。
区间分面查询参数:
facet.range:指定对哪个字段计算区间分面。可多次用该参数指定多个字段。 facet.range=price&facet.range=age facet.range.start:起始值 f.price.facet.range.start=0.0&f.age.facet.range.start=10 f.lastModified_dt.facet.range.start=NOW/DAY-30DAYS facet.range.end:结束值 f.price.facet.range.end=1000.0&f.age.facet.range.start=99 f.lastModified_dt.facet.range.end=NOW/DAY+30DAYS facet.range.gap:间隔值,创建子区间。对于数值字段,间隔值是数值,对于时间字段,用时间数学表达式(如+1DAY、+2MONTHS、+1HOUR等) f.price.facet.range.gap=100&f.age.facet.range.gap=10 f.lastModified_dt.facet.range.gap=+1DAY facet.range.hardend:如果间隔在下限和上限之间不是均匀分布,最后一个区间的大小要小于其他区间,当该参数为true时,最后区间的最大值就是上限值,如果为false,则最后区间会自动上扩,与其他区间等长。 facet.range.other 区间外的值是否统计,可选值: before: 统计<start的文档数 after:统计>end的文档数 between:统计区间内的 none:不统计 all:统计before、after、between的数量 facet.range.include:区间的边界是如何包含的,默认是包含下边界值,不包含上边界值 (最后一个区间包含) 。可选值: lower:所有区间包含下边界 upper:所有区间包含上边界 edge:第一个区间包含下边界,最后一个区间包含上边界。 outer:范围前“before” 和 后 “after”的统计区间将包含范围的下边界、上边界。即使范围内的区间包含了上、下边界。 all:选择所有选项:lower、upper、edge、outer Facet.mincount 也可使用。 注意:避免重复统计,不要同时选择lower和upper、outer、all 可根据字段来指定: f.<fieldname>.facet.range.include
区间分面-练习:
在techproduct内核上进分面查询:
1、按价格进行区间分面:10~10000 每间隔500一个区间
q=”:”&facet=true&facet.range=price&facet.range.start=10&facet.range.end=10000&facet.range.gap=500 参数说明: q=”:”-查询所有的,&facet=true-打开分面查询的开关 &facet.range=price-按照价格进行分面查询 &facet.range.start=10&facet.range.end=10000-区间10到10000 &facet.range.gap=500-每间隔500一个区间 最终在浏览器输入的地址为: http:localhost:8983/solr/techproducts?q=”:”&facet=true&facet.range=price&facet.range.start=10&facet.range.end=10000&facet.range.gap=500
2.3 查询分面
直接通过facet.query参数指定查询,来进行分面。
示例:
q=*:*&facet=true&facet.query=price:[* TO 5}&facet.query=price:[5 TO 10}&facet.query=price:[10 TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *] 说明: 通过facet.query指定需要查询的区间:*-5,5-10,10-20,20-50,50-* 最终在浏览器输入的地址为: http:localhost:8983/solr/techproducts?q=*:*&facet=true&facet.query=price:[* TO 5}&facet.query=price:[5 TO 10}&facet.query=price:[10 TO 20}&facet.query=price:[20 TO 50}&facet.query=price:[50 TO *]
2.4 决策树分面
pivot(Decision Tree)faceting:决策树分面,又称多级分面。如想看对搜中商品的按类别统计结果,在类别下又想看它的流行度构成。
决策树分面(多级分面)查询参数:
facet.pivot:指定分级字段,以逗号间隔。可多个facet.pivot参数指定多个分级分面。 facet.pivot.mincount ;最少匹配文档数,默认1。
示例:
facet.pivot=cat,popularity,inStock&facet.pivot=cat,inStock
说明:facet.pivot=cat,popularity,inStock表示先按照cat,再按照popularity分,最后按照inStock分
http://localhost:8983/solr/techproducts/select?q=*:*&facet.pivot=cat,popularity,inStock&facet.pivot=popularity,cat&facet=true&facet.field=cat&facet.limit=5&facet.pivot.mincount=2
key :Key 关键字用来对分面项进行重命名
q=*:*&facet=true&facet.query={!key="<5"}price:[* TO 5}&facet.query={!key="5-10"}price:[5 TO 10}&facet.query={!key="10-20"}price:[10 TO 20}&facet.query={!key="20-50"}price:[20 TO 50}
&facet.query={!key=">50"}price:[50 TO *]&facet.field={!key="类别"}ca
二、搜索结果高亮
1. 什么是搜索结果高亮
在搜索结果展示中突出显示搜索的关键字。下图是在百度中输入solr进行搜索的一条结果: solr是红色高亮的

2. 高亮参数说明:
hl:是否启用高亮,默认false 。 hl.fl:要高亮处理的字段列表,可以逗号、空格间隔,可以使用通配符* hl.fl=name,feauts hl.tag.pre :高亮前缀,可以是任意字符串,一般为html、xml标签,默认是<em> . (hl.simple.pre for the Original Highlighter) hl.tag.post:高亮后缀,默认是</em> hl.encoder :对字段值进行何种编码处理,默认空,不做处理。如果指定为html,会对字段值中的html字符进行编码处理:如 < 转为 < & 转为 & hl.maxAnalyzedChars :对字段值的最多多少个字符进行高亮处理,默认值51200 个字符。 hl.snippets :一个字段中可以有几个高亮片段,默认1。 hl.fragsize :高亮片段的最大字符数,默认100,无上限。 hl.method:指定高亮的实现方式,可选值: unified, original, fastVector。默认是 original。 hl.q:如果你要高亮的词不是主查询中的词,可通过此参数指定 hl.qparser:指定hl.q的查询解析器 hl.requireFieldMatch:是否只是查询用到的字段才高亮,默认false(hl.fl中指定的字段进行高亮处理)。 hl.usePhraseHighlighter:使用短语高亮,默认true。 hl.highlightMultiTerm:对于通配符查询(多词项查询)是否高亮,默认true。
3. 高亮响应结果
高亮在响应结果中是独立的一部分。
{ "response": { "numFound": 1, "start": 0, "docs": [{ "id": "MA147LL/A", "name": "Apple 60 GB iPod with Video Playback Black", "manu": "Apple Computer Inc.", }] }, "highlighting": { "MA147LL/A": { "manu": [ "<em>Apple</em> Computer Inc." ] } } }
4. 高亮的示例
http://localhost:8983/solr/techproducts/select?q=ipod&hl=true&hl.fl=name&hl.simple.pre=<span style='colr:red;font-size:20px'>&hl.simple.post=</span>
参数说明: q=ipod-查询字段ipod,&hl=true-开启高亮,&hl.fl=name-指定高亮的名称为name,hl.simple.pre=<span style='colr:red;font-size:20px'>-指定高亮字段前缀的html样式,&hl.simple.post=</span>-指定高亮字段后缀的样式
高亮的特殊需求,请详细参考官网的介绍:
https://lucene.apache.org/solr/guide/7_3/highlighting.html#usage
三、查询建议
1. 拼写检查
拼写检查解决因查询词拼写错误导致搜索结果不佳的问题。
拼写检查是搜索引擎的一个重要特征,帮助那些不想花时间构造查询表达式的用户,特别是移动环境中用户。 针对用户拼写错误或关键字生僻,而搜索结果不佳,提供相近的词建议。

1.1 拼写检查分析
拼写检查在什么情况下使用?
用户输入错误的,输入的词很生僻,命中结果很少
拼写检查组件应推荐什么样的词?
输入相近的词
拼写检查组件推荐的这些词从哪来?
从索引里面来
1.2 拼写检查组件配置
如需在查询中使用拼写检查,我们需要在solrconfig.xml中配置拼写检查组件,并在查询请求处理器中配置使用拼写检查组件(往往作为最后一个组件)。
配置示例:
<searchComponent name="spellcheck" class="solr.SpellCheckComponent"> <!-- 如有需要,可为拼写检查指定单独的分词器(通过fieldType指定) --> <str name="queryAnalyzerFieldType">text_general</str> <!-- 在该组件中可定义多个拼写检查器(字典)--> <!-- a spellchecker built from a field of the main index --> <lst name="spellchecker"> <str name="name">default</str> <str name="field">text</str> <str name="classname">solr.DirectSolrSpellChecker</str> ... </lst> <!-- a spellchecker that can break or combine words. --> <lst name="spellchecker"> <str name="name">wordbreak</str> <str name="classname">solr.WordBreakSolrSpellChecker</str> <str name="field">name</str> ... </lst> </searchComponent>
说明:
1.一个拼写检查器就是一种拼写检查实现方式。由name、classname、field、其他参数构成。
2. 在一个组件中可定义拼写检查器(字典),供查询处理器选择使用(可同时选择多个,推荐结果为多个的执行结果的合并)。
1.3 Solr中提供的拼写检查实现类
IndexBasedSpellChecker 独立拼写检查索引的实现方式
DirectSolrSpellChecker 使用solr主索引进行拼写检查
FileBasedSpellChecker 通过文件来提供拼写检查推荐词的实现方式
WordBreakSolrSpellChecker 可灵活拆分、组合词,基于主索引的实现方式。如多个英文单词少了空格的情况:solrspell checker,它可以进行拆分、组合尝试来推荐词。
DirectSolrSpellChecker配置参数说明
<lst name="spellchecker"> <str name="name">default</str> <!-- 通过查询哪个字段的词项来提供推荐词 --> <str name="field">text</str> <str name="classname">solr.DirectSolrSpellChecker</str> <!-- 使用的拼写检查度量方法, 默认值internal 使用的是 levenshtein距离算法--> <str name="distanceMeasure">internal</str> <!-- 一个词被认定为推荐词需满足的最低精确度。 0-1之间的浮点数,值越大精确度越高,推荐的词越少 --> <float name="accuracy">0.5</float> <!-- 允许的最大编辑数(即最多多少个字符不同),可取值:1、2. --> <int name="maxEdits">2</int> <!-- 枚举词项来推荐时,要求的最低相同前缀字符数。--> <int name="minPrefix">1</int> <!-- 返回的最大推荐词数。默认5 --> <int name="maxInspections">5</int> <!-- 要求的查询词项的最低字符数,默认4. 查询的词的字符数小于这个数就不进行拼写检查推荐。--> <int name="minQueryLength">4</int> <!-- 最大文档频率,高于该值的查询词不进行拼写检查的。可以是百分比或绝对值 --> <float name="maxQueryFrequency">0.01</float> <!-- 要求推荐词的文档频率高于这个值。可以是百分比或绝对值 <float name="thresholdTokenFrequency">.01</float> --> </lst>
1.4 在查询请求处理器中配置使用拼写检查
<requestHandler name="/spell" class="solr.SearchHandler" startup="lazy"> <!-- 拼写检查请求参数的默认值配置。--> <lst name="defaults"> <str name="spellcheck.dictionary">default</str> <str name="spellcheck.dictionary">wordbreak</str> <str name="spellcheck">on</str> <str name="spellcheck.extendedResults">true</str> <str name="spellcheck.count">10</str> <str name="spellcheck.alternativeTermCount">5</str> <str name="spellcheck.maxResultsForSuggest">5</str> <str name="spellcheck.collate">true</str> <str name="spellcheck.collateExtendedResults">true</str> <str name="spellcheck.maxCollationTries">10</str> <str name="spellcheck.maxCollations">5</str> </lst> <!-- 将拼写检查组件加到最后--> <arr name="last-components"> <str>spellcheck</str> </arr> </requestHandler>
拼写检查请求参数说明:
spellcheck:是否使用拼写检查,true/false
spellcheck.q:进行拼写检查的查询表达式,如未指定则使用q。
spellcheck.count:返回最多多少个推荐词。默认1。
spellcheck.dictionary:指定使用的拼写检查器(字典)名,默认default,同时使用多个则多次传参指定。
spellcheck.accuracy:一个词被认定为推荐词需满足的最低精确度。0-1之间的浮点数,值越大精确度越高,推荐的词越少 spellcheck.onlyMorePopular:如果设置为true,只返回比原始查询词文档频率更高的推荐词。
spellcheck.maxResultsForSuggest:原始查询匹配的文档数低于多少时才应该进行推荐,这个参数指定这个阀值。
spellcheck.extendedResults:true,获取推荐词的其他信息,如文档频次。
spellcheck.collate:true、指示solr为原始查询生成一个最佳的校对查询供用户使用。如输入“jawa class lording”,校对推荐"java class loading“
spellcheck.maxCollations:最多生成多少个校对查询。默认1
spellcheck.build:true,则solr会为拼写检查建立字典(如未建立)。directSolrSpellCheck不需要此选项。
spellcheck.reload:是否重新加载spellchecker(以重新加载拼写检查字典)
1.5 拼写检查请求示例
尝试下面的查询请求,请看推荐结果在哪里,都有些什么推荐词。
http://localhost:8983/solr/techproducts/spell?df=text&spellcheck.q=delll+ultra+sharp&spellcheck=true&spellcheck.collateParam.q.op=AND&wt=xml

2. 自动建议查询词
拼写检查是查询后推荐,自动建议查询词则在用户输入查询词就根据用户的输入给出建议查询词,从最开始就避免拼写错误,提供更好的用户体验,特别是在在移动设备上。
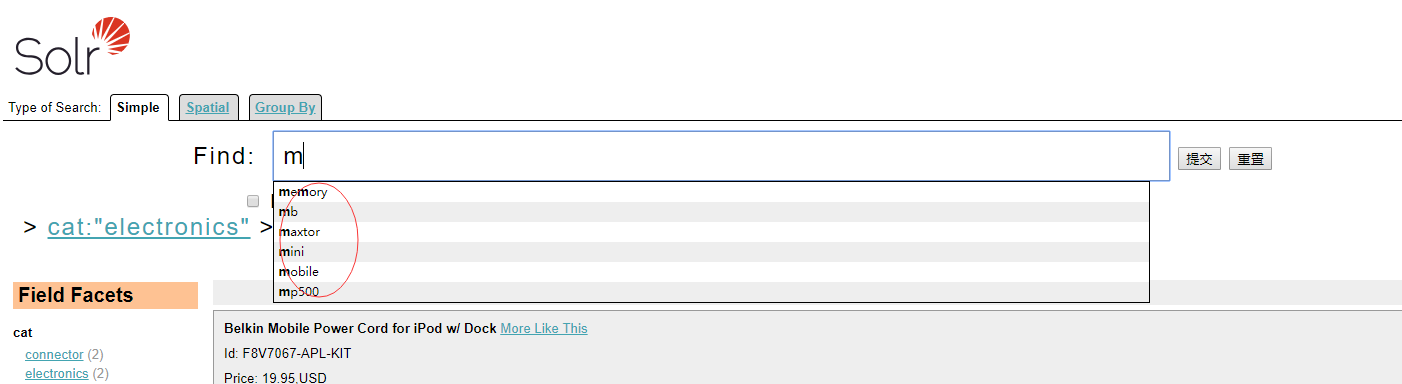
2.1 自动建议查询词组件
Solr中可以基于拼写检查组件实现自动建议查询词。也提供了专门的建议查询词组件solr.SuggestComponent。在techproducts示例的内核配置文件solrconfig.xml中配置有建议查询词组件和请求处理器,可直接参考。
自动建议查询词组件配置-示例
<searchComponent name="suggest" class="solr.SuggestComponent"> <!-- 可以定义多个建议器 --> <lst name="suggester"> <!-- 建议器名称 --> <str name="name">mySuggester</str> <!-- 建议字典的查找实现类,默认 JaspellLookupFactory --> <str name="lookupImpl">FuzzyLookupFactory</str> <!-- 建议字典的实现类,默认 HighFrequencyDictionaryFactory --> <str name="dictionaryImpl">DocumentDictionaryFactory</str> <!-- 基于哪个字段来提供建议查询词 --> <str name="field">cat</str> <!-- 指定权重字段 --> <str name="weightField">price</str> <!-- 指定要使用的分词器(通过fieldType) <str name="suggestAnalyzerFieldType">string</str> <!-- 是否在solr启动时就构建字典 --> <str name="buildOnStartup">false</str> </lst> </searchComponent>
详细参数、参数选项请参考:http://lucene.apache.org/solr/guide/7_3/suggester.html
自动建议查询请求处理器配置-示例
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <str name="suggest">true</str> <str name="suggest.count">10</str> </lst> <arr name="components"> <str>suggester</str> </arr> </requestHandler>
建议查询词请求参数说明:
suggest :是否使用建议查询词,true/false
suggest.q:进行建议查询词用的查询表达式。
suggest.count:返回最多多少个推荐词。
suggest.dictionary:指定使用的建议器(字典)名,必需。
suggest.build:true,构建建议字典索引,在初次请求时构建,后续请求不需要带这个参数。
suggest.reload:是否重新加载建议查询词索引。
2.2 自动建议查询请求-示例
http://localhost:8983/solr/techproducts/suggest?suggest=true&suggest.build=true&suggest.dictionary=mySuggester&suggest.q=elec
使用多重suggest.dictionary:
http://localhost:8983/solr/techproducts/suggest?suggest=true&suggest.dictionary=mySuggester&suggest.dictionary=altSuggester&suggest.q=elec
四、折叠展开结果
1. 什么是折叠展开结果?
问:在商品搜索中,当我们输入关键字,搜索到很多相关的商品文档,当结果中存在大量的同名商品时(不同卖家的),你是希望看到重复的商品罗列还是看到更多的不同商品(同名商品展示一个)?
折叠结果:就是对搜索结果根据某字段的值进行分组去重。
展开结果:在返回结果中附带上折叠结果的展开列表
请看下面查询的结果:
http://localhost:8983/solr/techproducts/select?q=*:*&fq={!collapse%20field=price}&expand=true
2. Solr折叠展开结果
Solr中通过Collapsing query parser 和 Expand component 的组合来提供根据某一字段对搜索结果进行折叠、展开处理。Solr中还提供的结果分组组件也能实现折叠功能,但如果仅是要做折叠展开处理,折叠展开结果性能要优些。
CollapsingQParser 其实是一个后置查询过滤器,对搜索结果根据指定的字段进行折叠处理。它需要的本地参数有:
field:指定折叠字段,必须是单值的String 、int 、float 类型的字段。
min or max:通过min或max指定的数值字段或函数查询来选择每个组的头文档(取最大或最小值的文档)。min、max、sort只可用其一。
sort:指定组内排序规则来选择排在第一的文档作为头文档。默认是选取组中相关性评分最高的文档作为头文档。
nullPolicy:对不包含折叠字段的文档采取什么处理策略:
ignore:忽略,默认选项。
expand:独立为一个组。
collapse:折叠为一个组。
折叠结果示例:
fq={!collapse field=group_field}
fq={!collapse field=group_field min=numeric_field}
fq={!collapse field=group_field max=numeric_field}
fq={!collapse field=group_field max=sum(cscore(),numeric_field)}
fq={!collapse field=group_field nullPolicy=collapse sort='numeric_field asc, score desc'}
2.1 Solr展开结果
如果你需要在结果中返回每个折叠组的展开列表,在请求中加上参数 expand=true
q=*:*&fq={!collapse%20field=price}&expand=true
展开组件还支持如下参数:
expand.sort:组内排序规则,默认是相关性评分。
expand.rows:每组返回的文档数。默认5
还有 expand.q、expand.fq
五、结果分组
1. Solr结果分组
根据某个字段对结果进行分组,每组返回一个头文档。
http://localhost:8983/solr/techproducts/select?fl=id,name&q=solr+memory&group=true&group.field=manu_exact
结果分组请求参数说明:
group :true,对搜索结果进行分组。
group.field :分组字段,必须是单值、索引的字段。
group.func:根据函数查询结果值进行分组(分布式下不可用)。
group.query:指定分组的查询语句,类似 facet.query。
rows:返回的分组数,默认10
start:分页起始行
group.limit:每组返回的文档数,默认1。
group.offset:组内返回的文档的偏移量。
sort:如何排序组。
group.sort:组内排序规则
group.main:用分组结果中的文档作为主结果返回
2. Solr结果分组-示例
2.1 Grouping Results by Field 根据字段进行分组
http://localhost:8983/solr/techproducts/select?fl=id,name&q=solr+memory&group=true&group.field=manu_exact
作为主结果返回
http://localhost:8983/solr/techproducts/select?fl=id,name,manufacturer&q=solr+memory&group=true&group.field=manu_exact&group.main=true
2.2 Grouping by Query 根据查询进行分组
http://localhost:8983/solr/techproducts/select?indent=true&fl=name,price&q=memory&group=true&group.query=price:[0+TO+99.99]&group.query=price:[100+TO+*]&group.limit=3
六、其他搜索特性介绍
1. Result clustering 结果聚合
http://lucene.apache.org/solr/guide/7_3/result-clustering.html
2. Spatial Search 地理空间搜索
http://lucene.apache.org/solr/guide/7_3/spatial-search.html
3. Parallel SQL Interface 搜索的SQL接口
http://lucene.apache.org/solr/guide/7_3/parallel-sql-interface.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号