Solr系列三:solr索引详解(Schema介绍、字段定义详解、Schema API 介绍)
一、Schema介绍
1. Schema 是什么?
Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段、字段的数据类型、字段该索引存储。
2. Schema 的定义方式
Solr中提供了两种方式来配置schema,两者只能选其一
2.1 默认方式,通过Schema API 来实时配置,模式信息存储在内核目录的conf/managed-schema文件中。
2.2 传统的手工编辑conf/schema.xml的方式,编辑完后需重载集合/内核才会生效。
3. schema两种配置方式切换
3.1 schema.xml 到 managed schema
只需将 solrconfig.xml中的<schemaFactory class =“ClassicIndexSchemaFactory”/> 去掉,或改为ManagedIndexSchemaFactory
Solr重启时,它发现存储schema.xml 但不存储在 managed-schema,它会备份schema.xml,然后改写schema.xml 为 managed-schema。此后就可以通过Schema API 管理schema了。
3.2 managed schema 到 schema.xml
1 将managed-schema 重命名为 schema.xml
2 将solrconfig.xml 中schemaFactory 的ManagedIndexSchemaFactory去掉(如果存在)
3 增加<schemaFactory class =“ClassicIndexSchemaFactory”/>
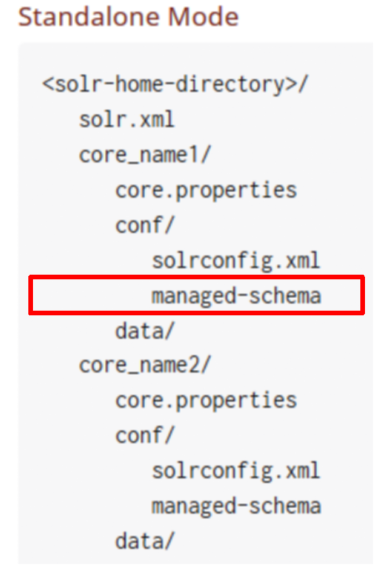
4. 查看 D:\solr-7.3.0\server\solr\mycore\conf\managed-schema文件,了解它的构成

二、字段定义详解
1. 字段定义示例
<field name="name" type="text_general" indexed="true" stored="true"/> <field name="includes" type="text_general" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
字段属性说明
name:字段名,必需。字段名可以由字母、数字、下划线构成,不能以数字开头。以下划线开头和结尾的名字为保留字段名,如 _version_
type:字段的fieldType名,必需。为 FieldType定义的name 属性值。
default:默认值,如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。非必需。
2. 字段定义详解-定义FieldType
(前面定义了字段field,这里我们就有定义字段类型fieldtype来给字段使用了)
字段类型,定义在索引时该如何分词、索引、存储字段,在查询时该如何对查询串分词
<fieldType name="managed_en" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.ManagedStopFilterFactory" managed="english" /> <filter class="solr.ManagedSynonymGraphFilterFactory" managed="english" /> <filter class="solr.FlattenGraphFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.ManagedStopFilterFactory" managed="english" /> <filter class="solr.ManagedSynonymGraphFilterFactory" managed="english" /> </analyzer> </fieldType>
FieldType 的属性
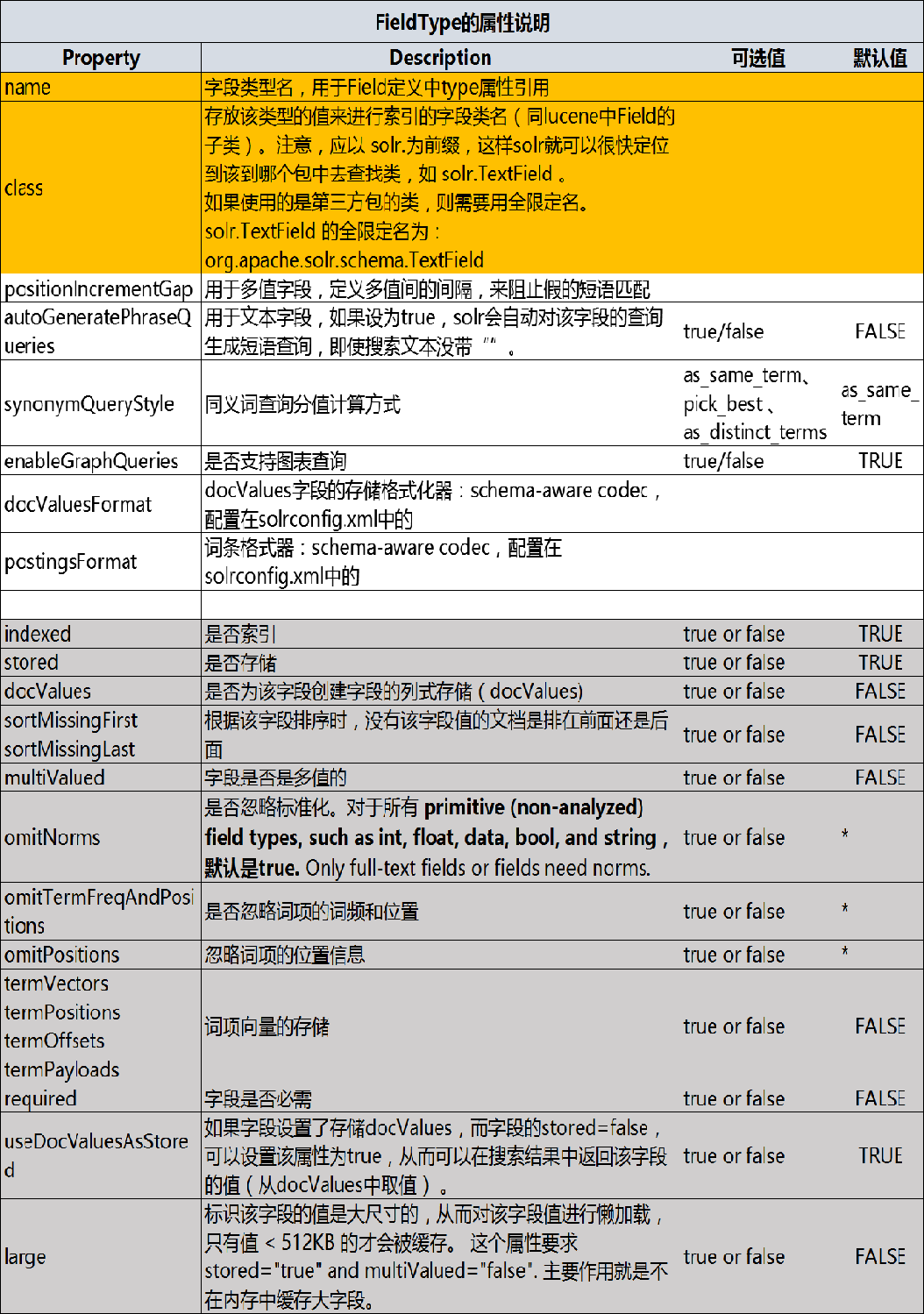
Solr中提供的 FieldType 类,在 org.apache.solr.schema 包下
http://lucene.apache.org/solr/guide/7_3/field-types-included-with-solr.html
3. FieldType 的 Analyzer
对于 solr.TextField or solr.SortableTextField 字段类型,需要为其定义分析器。
<fieldType name="nametext" class="solr.TextField"> <analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/> </fieldType>
可以直接通过class属性指定分析器类,必须继承org.apache.lucene.analysis.Analyzer 。
也可灵活地组合分词器、过滤器:
<fieldType name="nametext" class="solr.TextField"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StandardFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory"/> </analyzer> </fieldType>
注意:org.apache.solr.analysis 包下的类可以简写为 solr.xxx
如果该类型字段索引、查询时需要使用不同的分析器,则需区分配置analyzer
<fieldType name="nametext" class="solr.TextField"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/> <filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
Solr中提供的tokenizer: http://lucene.apache.org/solr/guide/7_3/tokenizers.html
Solr中提供的 fiter: http://lucene.apache.org/solr/guide/7_3/filter-descriptions.html
4. 常用的Filter
4.1 Stop Filter 停用词过滤器
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt"/> </analyzer>
words属性指定停用词文件的绝对路径或相对 conf/目录的相对路径
停用词定义语法:一行一个
4.2 Synonym Graph Filter 同义词过滤器
<analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> <filter class="solr.FlattenGraphFilterFactory"/> <!-- required on index analyzers after graph filters --> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> </analyzer>
同义词定义语法:
(1)一类一行:
couch,sofa,divan
(2)=>表示标准化为后面的:
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
提问:(1)(2)同义词的定义在索引的时候处理和查询的时候处理哪种效率更高?
答:一类一行的在查询的时候进行处理效率更高,原因是如果在索引的时候处理话要存储的字段更多,并且在查询的时候可扩展性更高,如果有新词出现直接在同义词文件里面增加新词,然后重载即可。
标准化的方式在索引的时候处理的性能更高,原因是存储的字段更少
练习1:自定义字段过滤停用词和同义词
步骤1:
在D:\solr-7.3.0\server\solr\mycore\conf目录下的停用词stopwords.txt和同义词synonyms.txt的txt文件里面分别加入
停用词:
hello
like
同义词:
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny

步骤2:
在D:\solr-7.3.0\server\solr\mycore\conf目录下的模式文件managed-schema里面自定义一个字段来进行分词索引并配置停用词和同义词
<!--自定义字段过滤停用词和同义词 begin--> <fieldType name="myTestField" class="solr.SortableTextField" positionIncrementGap="100" multiValued="true"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> <!--自定义字段过滤停用词和同义词 end-->
步骤3:
重启solr,在web控制台就可以进行测试查看效果了
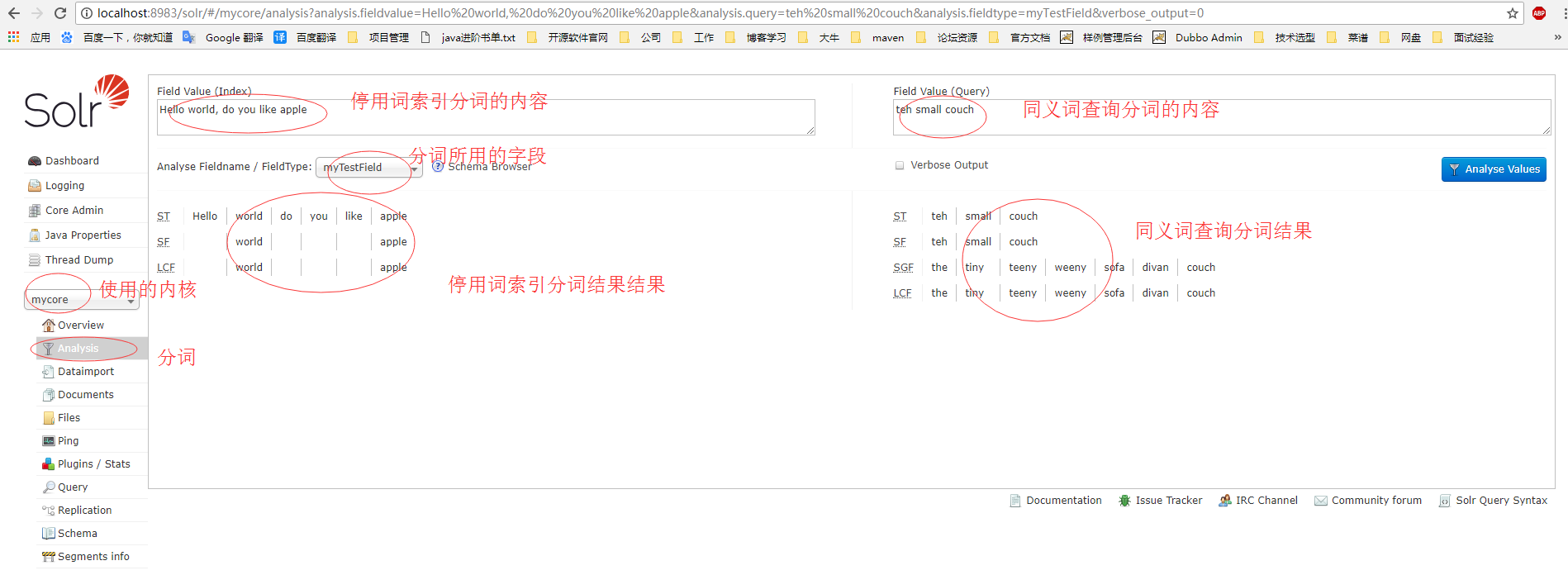
练习2:在solr里面集成IKAnalyzer 中文分词器
步骤1:
在原来学习lucene集成IKAnalyzer的基础上,为IkAnalyzer实现一个TokenizerFactory(继承它),接收useSmart参数。
步骤2:
将这三个类打成jar,如 IKAnalyzer-lucene7.3.jar
步骤3:
将这个IKAnalyzer-lucene7.3.jar和 IKAnalyzer的jar 拷贝到web应用的lib目录下

步骤4:
将停用词和扩展词的三个配置文件拷贝到应用的classes目录下
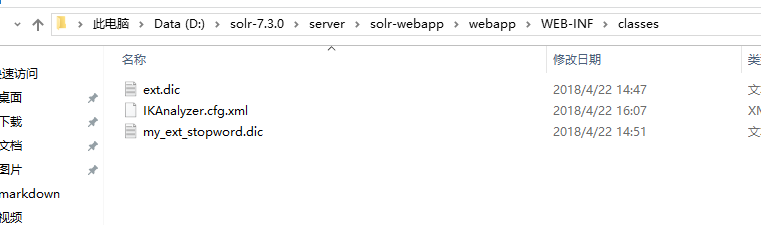
步骤5:
在schema中定义一个FieldType,使用IKAnalyzer适配类
<!--集成IK中文分词器 里面有停用词和扩展词 begin--> <fieldType name="ik_zh_CN" class="solr.TextField"> <analyzer> <tokenizer class="com.study.lucene.demo.analizer.ik.IKTokenizer4Lucene7Factory" useSmart="true" /> </analyzer> </fieldType> <!--集成IK中文分词器 里面有停用词和扩展词 end-->
步骤6.:
重启solr,在web控制台就可以进行测试查看效果了

5. 时间字段类型
5.1 Solr中提供的时间字段类型( DatePointField-单个日期, DateRangeField-日期范围,废除的TrieDateField )是以时间毫秒数来存储时间的。要求字段值以ISO-8601标准格式来表示时间:
YYYY-MM-DDThh:mm:ssZ
示例:
1999-05-20T17:33:18Z
Z表示是UTC时间(注意:就没有时区了)
秒上可以带小数来表示毫秒,超出精度(3位小数)部分会被忽略:
1972-05-20T17:33:18.772Z
1972-05-20T17:33:18.77Z
1972-05-20T17:33:18.7Z
公元前:在前面加减号 -
9999后,在前面加加号 +
注意:查询时如果是直接的时间串,需要用转移符转义
datefield:1972-05-20T17\:33\:18.772Z
datefield:"1972-05-20T17:33:18.772Z"
datefield:[1972-05-20T17:33:18.772Z TO *]
5.2 DateRangeField 时间段类型特别说明
DateRangeField用来支持对时间段数据的索引,它遵守时间格式:YYYY-MM-DDThh:mm:ssZ,支持两种时间段表示方式:
方式一:截断日期,它表示整个日期跨度的精确指示。
2000-11 表示2000年11月整个月.
2000-11T13 表示2000年11月每天的13点这一个小时
-0009 公元前10年,0000是公元前1年。
方式二:范围语法 [ TO ] { TO }
[2000-11-01 TO 2014-12-01] 日到日
[2014 TO 2014-12-01] 2014年开始到2014-12-01止.
[* TO 2014-12-01] 2014-12-01(含)前.
5.3 时间数学表达式
Solr中还支持用 NOW +- 时间的数学表达式来灵活表示时间。语法 NOW +- 带单位的时间数,/单位 截断。可用来表示时间段。
NOW+2MONTHS:现在的时间加上2个月
NOW-1DAY:现在的时间减去1天
NOW/HOUR:当前时间取整到小时
NOW+6MONTHS+3DAYS/DAY:当前时间+6个月+3天,然后取整到天
1972-05-20T17:33:18.772Z+6MONTHS+3DAYS/DAY
注意:运算顺序是从左往右,只有加减取整运算,没有乘除运算
NOW在查询中使用时,可为NOW指定值:
q=solr&fq=start_date:[* TO NOW]&NOW=1384387200000
没有&后面的赋值NOW就是当前时间
6. EnumFieldType 枚举字段类别说明
EnumFieldType 用于字段值是一个枚举集,且排序顺序可预定的情况,如新闻分类这样的字段。定义非常简单:
<fieldType name="priorityLevel" class="solr.EnumFieldType" docValues="true" enumsConfig="enumsConfig.xml" enumName="priority"/>
说明:
enumsConfig:指定枚举值的配置文件,绝对路径或相对内核conf/的相对路径
enumName:指定配置文件的枚举名。排序顺序是按配置的顺序。
docValues : 枚举类型字段必须设置 true;
枚举配置示例:
<?xml version="1.0" ?> <enumsConfig> <enum name="priority"> <value>Not Available</value> <value>Low</value> <value>Medium</value> <value>High</value> <value>Urgent</value> </enum> <enum name="risk"> <value>Unknown</value> <value>Very Low</value> <value>Low</value> <value>Medium</value> <value>High</value> <value>Critical</value> </enum> </enumsConfig>
7. dynamic Field 动态字段
问:如果模式中有近百个字段需要定义,其中有很多字段的定义是相同,重复地定义是不是很烦?
可不可以定一个规则,字段名以某前缀开头或结尾的是相同的定义配置,那这些重复字段就只需要配置一个,保证提交的字段名称遵守这个前缀、后缀即可。 这就是动态字段。
如:整型字段都是一样的定义,则可以定义一个动态字段如下:
<dynamicField name="*_i" type=“my_int" indexed="true" stored="true"/>
也可以是前缀,如 name=“i_*”
8. CopyField 复制字段
复制字段允许将一个或多个字段的值填充到一个字段中。它的用途有两种:
1、将多个字段内容填充到一个字段,来进行搜索。如用户输入了多个搜索字段,程序就把这些字段放入一个字段里面进行搜索
2、对同一个字段内容进行不同的分词过滤,创建一个新的可搜索字段
定义方式:
1、先定义一个普通字段
<field name="cc_all" type="zh_CN_text" indexed="true" stored="false" multiValued="false" />
2、定义复制字段
<copyField source="cat" dest="cc_all"/> <copyField source="name" dest="cc_all"/>
把cat和name这两个字段都复制到cc_all这个字段里面
问:复制字段时,source可以是动态字段吗?
答:可以
8. uniqueKey 唯一键
指定用作唯一键的字段,非必需。
<uniqueKey>id</uniqueKey>
唯一键字段不可以是保留字段、复制字段,且不能分词。
注意:唯一键是业务的唯一字段,不是document的id
9. Similarity 相关性计算类配置
问:什么是相关性计算?
答:相关性计算指的是根据某个字段进行搜索时,把与搜索最匹配的排在前面
如果默认的相关性计算模型BM25Similarity不满足你应用的特殊需要,你可在schema中指定全局的或字段类型局部的相关性计算类
示例:
<similarity class="solr.SchemaSimilarityFactory"> <str name="defaultSimFromFieldType">text_dfr</str> </similarity> <fieldType name="text_dfr" class="solr.TextField"> <analyzer ... /> <similarity class="solr.DFRSimilarityFactory"> <str name="basicModel">I(F)</str> <str name="afterEffect">B</str> <str name="normalization">H3</str> <float name="mu">900</float> </similarity> </fieldType>
10. 小结:字段定义详解

三、Schema API 介绍
前面我们都是采用自己在schema模式配置文件里面自己编写配置文件的方式来定义模式,其实我们还可以使用schema API的方式来动态的定义模式,不用自己手工编写配置文件,这样更加方便

1、Schema操作API总体介绍
Solr中强烈推荐使用Schema API来管理集合/内核的模式信息,可以读、写模式信息。通过API来更新模式信息,solr将自动重载内核。但是请注意:模式修改并不会自动重索引已索引的文档,只会对后续的文档起作用,如果必要,你需要手动重索引(删除原来的,重新提交文档)。
1.1 更新Schema:
发送 post请求到 /collection/schema ,以JSON格式提交数据,在json中说明你要进行的更新操作及对应的数据(一次请求可进行多个操作)
1.2 更新操作定义
add-field: 添加一个新字段.
delete-field: 删除一个字段.
replace-field: 替换一个字段,修改.
add-dynamic-field: 添加一个新动态字段.
delete-dynamic-field: 删除一个动态字段
replace-dynamic-field: 替换一个已存在的动态字段
add-field-type: 添加一个fieldType.
delete-field-type: 删除一个fieldType.
replace-field-type: 更新一个存在的fieldType
add-copy-field: 添加一个复制字段规则.
delete-copy-field: 删除一个复制字段规则.
2、V1、V2两个版本API说明
V1老版本的api,V2新版本的API,当前两个版本的API都支持,将来会统一到新版本。两个版本的API只是请求地址上的区别,参数没区别。
V1: http://localhost:8983/solr/mycore/schema
V2: http://localhost:8983/api/cores/mycore/schema
说明:
mycore:solr里面定义的内核或者集合的名称
3、FieldType字段类别操作
3.1 添加一个字段类别 add-field-type
使用postman来发送添加的请求:
请求地址:http://localhost:8983/solr/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
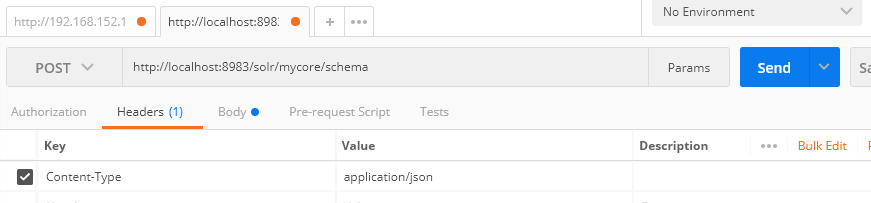
参数:json格式的参数
{
"add-field-type": {
"name": "myNewTxtField",
"class": "solr.TextField",
"positionIncrementGap": "100",
"analyzer": {
"tokenizer": {
"class": "solr.WhitespaceTokenizerFactory"
},
"filters": [
{
"class": "solr.WordDelimiterFilterFactory",
"preserveOriginal": "0"
}
]
}
}
}
postman模拟请求:

在solr的web控制台查看添加的字段

添加字段时包含索引分析器和查询分析器:
{
"add-field-type": {
"name": "myNewTextField",
"class": "solr.TextField",
"indexAnalyzer": {
"tokenizer": {
"class": "solr.PathHierarchyTokenizerFactory",
"delimiter": "/"
}
},
"queryAnalyzer": {
"tokenizer": {
"class": "solr.KeywordTokenizerFactory"
}
}
}
}
3.2 删除一个字段类别 delete-field-type
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"delete-field-type": {
"name": "myNewTxtField"
}
}
3.3 替换一个字段类别 replace-field-type
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"replace-field-type": {
"name": "myNewTxtField",
"class": "solr.TextField",
"positionIncrementGap": "100",
"analyzer": {
"tokenizer": {
"class": "solr.StandardTokenizerFactory"
}
}
}
}
4、Field 字段操作
4.1 添加一个字段 add-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"add-field": {
"name": "sell_by",
"type": "myNewTxtField",
"stored": true
}
}
4.2 删除一个字段 delete-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"delete-field": {
"name": "sell_by"
}
}
4.3 替换一个字段 replace-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"replace-field": {
"name": "sell_by",
"type": "date",
"stored": false
}
}
5、dynamicField 动态字段操作
5.1 添加一个动态字段 add-dynamic-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"add-dynamic-field": {
"name": "*_s",
"type": "string",
"stored": true
}
}
5.2 删除一个动态字段 delete-dynamic-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"delete-dynamic-field": {
"name": "*_s"
}
}
5.3 替换一个动态字段 replace-dynamic-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"replace-dynamic-field":{
"name":"*_s",
"type":"text_general",
"stored":false }
}
6、copyField 复制字段操作
6.1 添加复制字段 add-copy-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"add-copy-field": {
"source": "shelf",
"dest": [
"location",
"catchall"
]
}
}
6.2 删除复制字段 delete-copy-field
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"delete-copy-field": {
"source": "shelf",
"dest": "location"
}
}
7. 一次请求多个操作示例
7.1 同时添加字段类型和字段
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"add-field-type": {
"name": "myNewTxtField",
"class": "solr.TextField",
"positionIncrementGap": "100",
"analyzer": {
"tokenizer": {
"class": "solr.WhitespaceTokenizerFactory"
},
"filters": [
{
"class": "solr.WordDelimiterFilterFactory",
"preserveOriginal": "0"
}
]
}
},
"add-field": {
"name": "sell_by",
"type": "myNewTxtField",
"stored": true
}
}
7.2 一次添加多个字段
请求地址:http://localhost:8983/api/cores/mycore/schema
请求方式:post
设置头信息为:Content-type:application/json
参数:json格式的参数
{
"add-field": [
{
"name": "shelf",
"type": "myNewTxtField",
"stored": true
},
{
"name": "location",
"type": "myNewTxtField",
"stored": true
}
]
}
8、获取schema信息
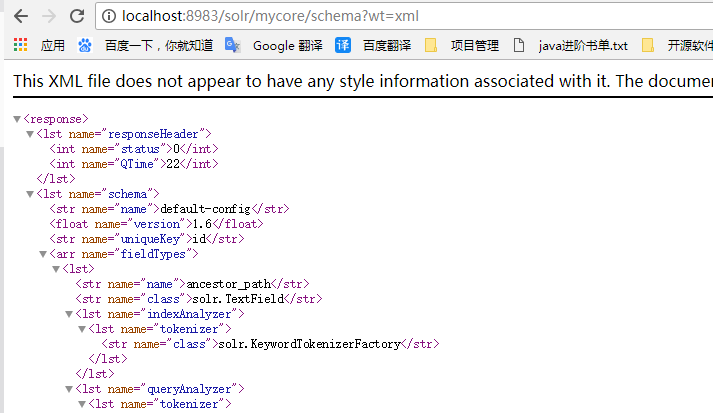
8.1 获取整个schema
GET /collection/schema
可以通过wt请求参数指定返回的格式:json,xml, schema.xml
http://localhost:8983/api/cores/mycore/schema?wt=xml
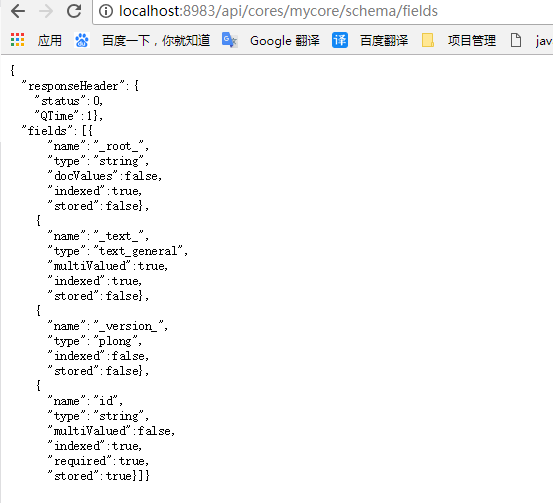
8.2 获取字段
GET /collection/schema/fields
GET /collection/schema/fields/fieldname
请求参数有:
wt: json/xml fl:指定需要返回的字段名,以逗号或空格间隔
showDefaults:true/false ,是否返回字段的默认属性
includeDynamic:true/false,在path中带有fieldname 或指定了 fl的情况下才有用。
获取所有字段:
http://localhost:8983/api/cores/mycore/schema/fields
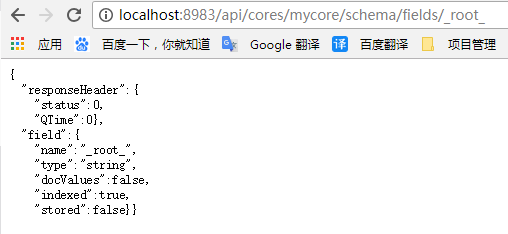
获取指定字段:
http://localhost:8983/api/cores/mycore/schema/fields/_root_
8.3 获取动态字段
GET /collection/schema/dynamicfields
GET /collection/schema/dynamicfields/name
可用请求参数:wt、showDefaults
http://localhost:8983/api/cores/mycore/schema/dynamicfields?wt=xml
8.4 获取字段类别
GET /collection/schema/fieldtypes
GET /collection/schema/fieldtypes/name
可用请求参数:wt、showDefaults
http://localhost:8983/api/cores/mycore/schema/fieldtypes?wt=xml

8.5 获取复制字段
GET /collection/schema/copyfields
可用请求参数:wt、 source.fl、 dest.fl
8.6 获取其他信息
GET /collection/schema/name 获取schema的name
GET /collection/schema/version 获取schema的版本
GET /collection/schema/uniquekey 获取唯一键字段
GET /collection/schema/similarity 获取全局相关性计算类
可用请求参数:wt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号