Redis系列六:redis相关功能
一、 慢查询原因分析
与mysql一样:当执行时间超过阀值,会将发生时间耗时的命令记录
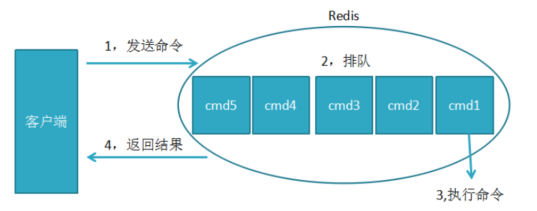
redis命令生命周期:发送 排队 执行 返回
慢查询只统计第3个执行步骤的时间
预设阀值:两种方式,默认为10毫秒
1,动态设置6379:> config set slowlog-log-slower-than 10000 //10毫秒10000微秒
使用config set完后,若想将配置持久化保存到redis.conf,要执行config rewrite
2,redis.conf修改:找到slowlog-log-slower-than 10000 ,修改保存即可
注意:slowlog-log-slower-than =0记录所有命令 -1命令都不记录
原理:慢查询记录也是存在队列里的,slow-max-len 存放的记录最大条数,比如设置的slow-max-len=10,当有第11条慢查询命令插入时,队列的第一条命令就会出列,第11条入列到慢查询队列中, 可以config set动态设置,也可以修改redis.conf完成配置。
2 命令:
获取队列里慢查询的命令:slowlog get 查询返回的结构如下
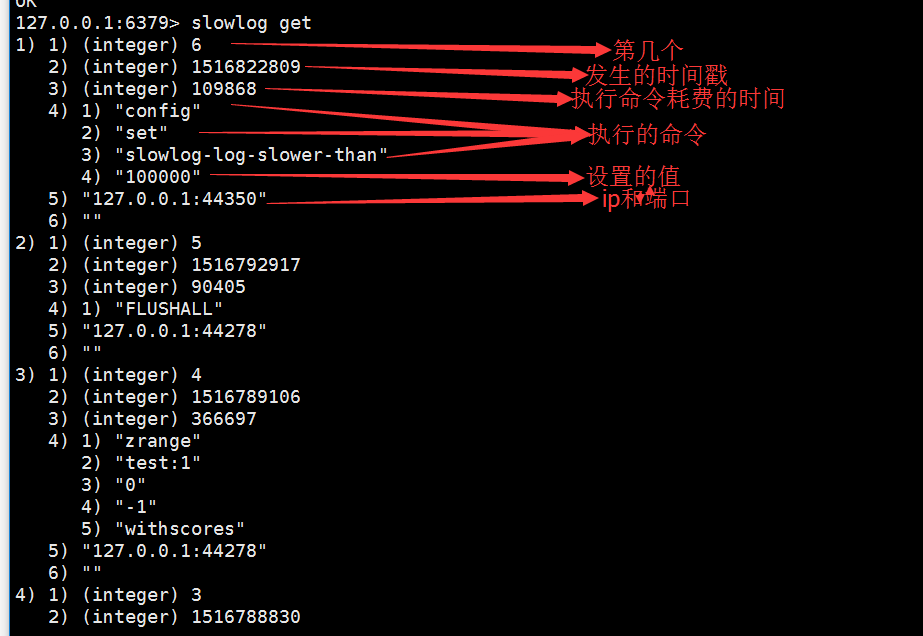
获取慢查询列表当前的长度:slowlog len //返回7

对慢查询列表清理(重置):slowlog reset //再查slowlog len 此时返回0 清空
对于线上slow-max-len配置的建议:线上可加大slow-max-len的值,记录慢查询存长命令时redis会做截断,不会占用大量内存,线上可设置1000以上
对于线上slowlog-log-slower-than配置的建议:默认为10毫秒,根据redis并发量来调整,对于高并发比建议为1毫秒
注意:
1,慢查询只记录命令在redis的执行时间,不包括排队、网络传输时间
2,慢查询是先进先出的队列,访问日志记录出列丢失,需定期执行slow get,将结果存储到其它设备中(如mysql)
二、redis-cli详解
./redis-cli -r 3 -h 192.168.1.111 -a 12345678 ping //返回pong表示127.0.0.1:6379能通,r代表次数
./redis-cli -r 100 -i 1 info |grep used_memory_human //每秒输出内存使用量,输100次,i代表执行的时间间隔
./redis-cli -p 6379 -h 192.168.1.111 -a 12345678
对于我们来说,这些常用指令以上可满足,但如果要了解更多
执行./redis-cli --help, 可百度
三、 redis-server详解
./redis-server ./redis.conf & //指定配置文件启动
./redis-server --test-memory 1024 //检测操作系统能否提供1G内存给redis, 常用于测试,想快速占满机器内存做极端条件的测试,可使用这个指令
redis上线前,做一次测试

四、redis-benchmark:基准性测试,测试redis的性能
100个客户端同时请求redis,共执行10000次,会对各类数据结构的命令进行测试:
./redis-benchmark -h 127.0.0.1 -c 100 -n 10000 //100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性能
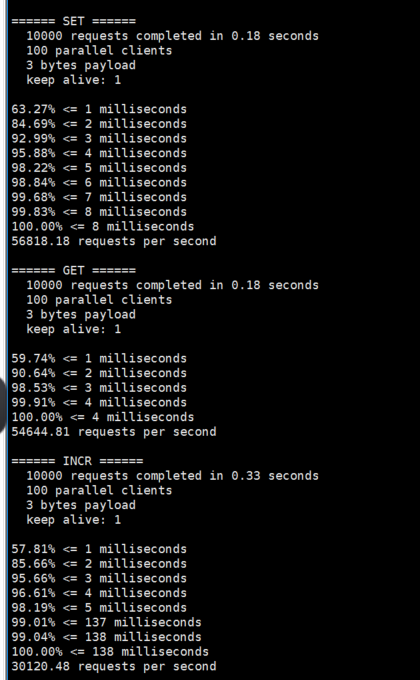
测试存取大小为100字节的数据包的性能:
./redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100
只测试 set,lpush操作的性能,-q只显示每秒钟能处理多少请求数结果:
./redis-benchmark -h 127.0.0.1 -t set,lpush -n 100000 -q
只测试某些数值存取的性能, 比如说我在慢查询中发现,大部分为set语句比较慢,我们自己可以测一下Set是不是真的慢:
./redis-benchmark -h 192.168.1.111 -n 100000 -q script load "redis.call('set','foo','bar')"
五、Pipeline(管道)
1.背景:
没有pipeline之前,一般的redis命令的执行过程都是:发送命令-〉命令排队-〉命令执行-〉返回结果。
多条命令的时候就会产生更多的网络开销
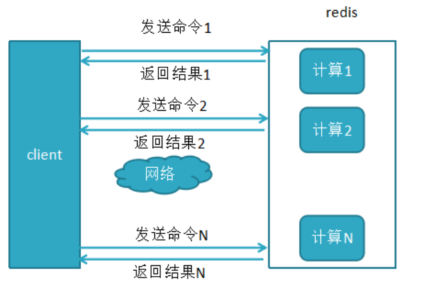
这个时候需要pipeline来解决这个问题:使用pipeline来打包执行N条命令,这样的话就只需简历一次网络连接,网络开销就少了
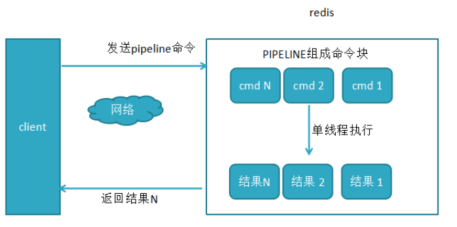
2. 使用pipeline和未使用pipeline的性能对比:
使用Pipeline执行速度与逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显
3.原生批命令(mset, mget)与Pipeline对比
1) 原生批命令是原子性,pipeline是非原子性, (原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功要么都失败,其实也引用了生物里概念,分子-〉原子,原子不可拆分)
2) 原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
3) 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
4. pipeline正确使用方式:
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成
如:有300个命令需要执行,可以拆分成每30个一个pipeline执行
六、redis事务
pipeline是多条命令的组合,为了保证它的原子性,redis提供了简单的事务;redis的事物与mysql事物的最大区别是redis事物不支持事物回滚
事务:事务是指一组动作的执行,这一组动作要么都成功,要么都失败。
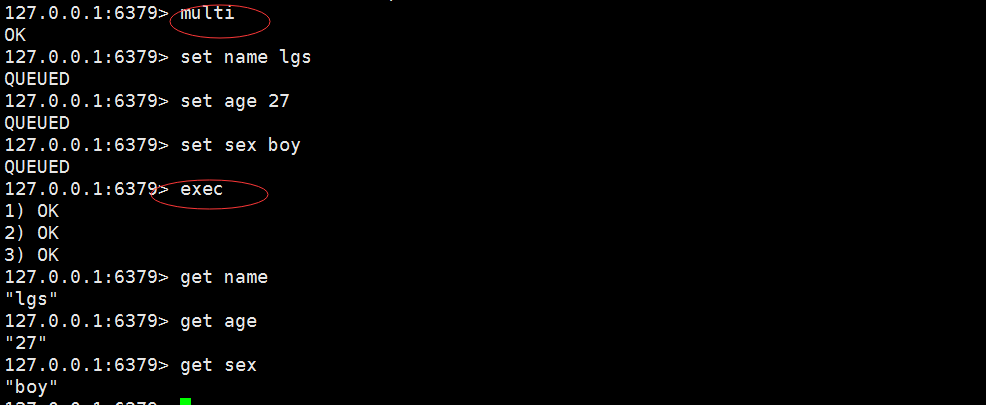
1. redis的简单事务,将一组需要一起执行的命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束
2.停止事务discard
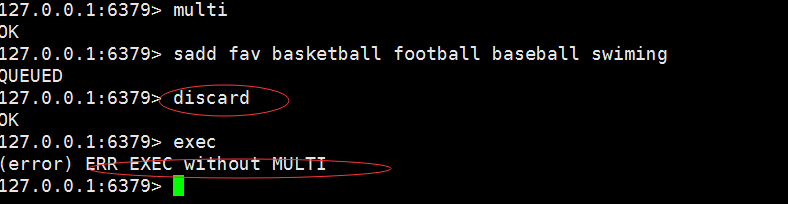
3. 命令错误,语法不正确,导致事务不能正常执行,即事物的原子性

4. watch命令:使用watch后, multi失效,事务失效,其他的线程任然可以对值进行修改

在客户端1设置值使用watch监听key并使用multi开启事物,在客户端2追加完c之后再来客户端1追加redis,然后执行事物,可以看到在客户端1追加的redis没有起效果:
客户端1:

客户端2:

七、LUA语言与Redis配合使用
1. LUA脚本语言是C开发的,类似存储过程
1).减少网络开销:本来5次网络请求的操作,可以用一个请求完成,原先5次请求的逻辑放在redis服务器上完成。使用脚本,减少了网络往返时延。
2).原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。
3).复用:客户端发送的脚本会永久存储在Redis中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑
语法:
eval+脚本+KEYS[1]+键个数+键——》eval script numkeys key [key ...]
eval "return redis.call('get',KEYS[1])" 1 name
语法示例1:
1 local int sum = 0 2 local int i =0 3 while i <= 100 4 do sum = sum+i 5 i = i+1 6 end 7 print(sum)
语法示例2:
1 local tables myArray={“james”,”java”,false,34} //定义 2 local int sum = 0 3 print(myArray[3]) //返回false 4 for i = 1,100 5 do 6 sum = sum+1 7 end 8 print(sum) 9 for j = 1,#myArray //遍历数组 10 do 11 print(myArray[j]) 12 if myArray[j] == “james” 13 then 14 print(“true”) 15 break 16 else 17 print(“false”) 18 end 19 end
2. 案例:
实现访问频率限制: 实现访问者 $ip 127.0.0.1在一定的时间 $time 20S内只能访问 $limit 10次.
a)使用JAVA语言实现:
1 private boolean accessLimit(String ip, int limit, 2 int time, Jedis jedis) { 3 boolean result = true; 4 5 String key = "rate.limit:" + ip; 6 if (jedis.exists(key)) { 7 long afterValue = jedis.incr(key); 8 if (afterValue > limit) { 9 result = false; 10 } 11 } else { 12 Transaction transaction = jedis.multi(); 13 transaction.incr(key); 14 transaction.expire(key, time); 15 transaction.exec(); 16 } 17 return result; 18 }
以上代码有两点缺陷 :
可能会出现竞态条件: 解决方法是用 WATCH 监控 rate.limit:$IP 的变动, 但较为麻烦;
以上代码在不使用 pipeline 的情况下最多需要向Redis请求5条指令, 传输过多.
b)使用lua脚本来处理,包括了原子性
lua脚本:
ipAccessCount.lua
1 local key = KEYS[1] 2 local limit = tonumber(ARGV[1]) 3 local expire_time = ARGV[2] 4 5 local is_exists = redis.call("EXISTS", key) 6 if is_exists == 1 then 7 if redis.call("INCR", key) > limit then 8 return 0 9 else 10 return 1 11 end 12 else 13 redis.call("SET", key, 1) 14 redis.call("EXPIRE", key, expire_time) 15 return 1 16 end
使用redis命令获取lua脚本来执行:
./redis-cli -p 6379 -a 12345678 --eval ipAccessCount.lua rate.limit:127.0.0.1, 10 20
和lua脚本的对应关系为: keys[1] = rate.limit:127.0.0.1 argv[1]=10次, argv[2]=20S失效
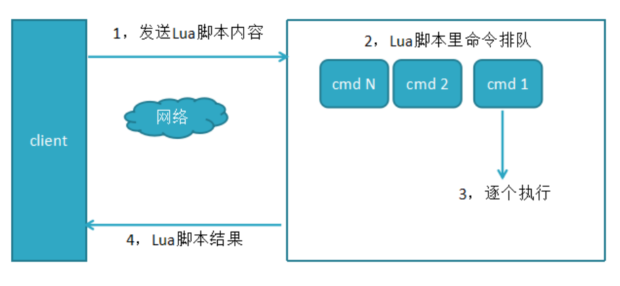
执行逻辑:使用redis-cli --eavl时,客户端把lua脚本字符串发给redis服务端,将结果返回客户端,如下图
3. redis对Lua脚本的管理
1.将Lua脚本加载到redis中,得到 返回的sha1值(类似于我们说的数字签名):afe90689cdeec602e374ebad421e3911022f47c0
redis-cli -h 192.168.1.111 -a 12345678 script load "$(cat random.lua)"
2.检查脚本加载是否成功,返回1 已加载成功
script exists afe90689cdeec602e374ebad421e3911022f47c0
3.清空Lua脚本内容
script flush
4.杀掉正在执行的Lua脚本
script kill
八、发布与订阅
redis提供了“发布、订阅”模式的消息机制,其中消息订阅者与发布者不直接通信,发布者向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以接收到消息
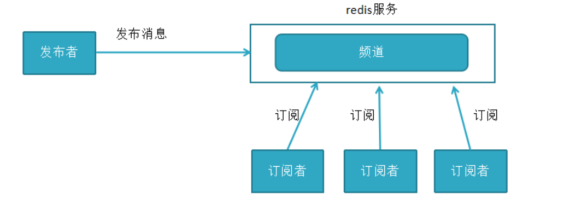
redis主要提供发布消息、订阅频道、取消订阅以及按照模式订阅和取消订阅
1.发布消息
publish channel:test "hello world"

2.订阅消息
subscrible channel:test
此时另一个客户端发布一个消息:publish channel:test "james test"
当前订阅者客户端会收到如下消息:
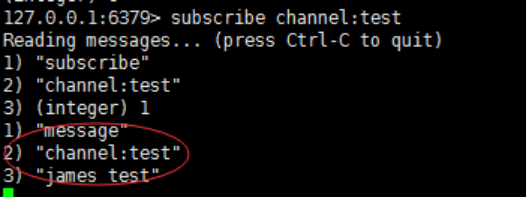
和很多专业的消息队列(kafka rabbitmq),redis的发布订阅显得很lower, 比如无法实现消息规程和回溯, 但就是简单,如果能满足应用场景,用这个也可以
3.查看订阅数:
pubsub numsub channel:test // 频道channel:test的订阅数
4.取消订阅
unsubscribe channel:test
客户端可以通过unsubscribe命令取消对指定频道的订阅,取消后,不会再收到该频道的消息
5.按模式订阅和取消订阅
psubscribe ch* //订阅以ch开头的所有频道
punsubscribe ch* //取消以ch开头的所有频道
6.应用场景:
1、今日头条订阅号、微信订阅公众号、新浪微博关注、邮件订阅系统
2、即时通信系统
3、群聊部落系统(微信群)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号