
InterV 7:算法(怎样提高算法能力、基础算法题、几道常见的子符串算法题、剑指offer部分编程题)
怎样提高算法能力:
刷题是可以锻炼的,千万不要让算法成为自己的短板。
1. 刷题是没有技巧的,就是多做题多练多总结,对于很多新手不要去想是不是还有最优解什么的,你做的就是暴力法求解,刷题是很枯燥的,你需要给自己一点鼓励,当把题目解决以后再去考虑其他的,在你不能很快的解决问题的时候,可是试着写点伪代码或者画个流程图。当你经过大量的练习,会形成条件反射知道这是什么类型的题,用什么方法解决。
LeetCode刷题系列是按照某个专题进行的,这样对比着刷题效果是比较好的。千万不要耍小聪明用一些奇巧淫技,思路不对再怎么绕都是浪费时间。
遇到问题多找轮子,一定有人跟你一样菜遇到过同样的问题,同样不要想着自己造轮子,绝大多数问题前辈一定有更好更完善的方案在,自己造轮子费时费事又没太大意义。
2. 一定要自己动手实现,看答案和自己做是两回事,自己做一遍以后会加深对问题的理解。没必要把所有算法都精通,但起码在遇到问题时可以找到最优算法解决问题。即知道算法的存在及其用途,按需深入学习。
3. 最重要的一点坚持下去,最简单且最难的事情就是坚持,每天刷一个题保持良好的手感,时间不用长了,一个月你会有非常大的进步。
4. 先写思路,再写代码
在A题的过程中,我从没用过IDE编译代码看输出,基本上都是肉眼debug,然后改错。这个方法是我在A题时别人建议的,这样可以锻炼自己的思维能力,也可以慢慢提高自己写代码的全局观和对异常输出的处理。
一开始刷题时,我都是有一点思路就尝试开始写代码,写着写着发现这种方法不可行,又全部删掉。后来慢慢变成了先在纸上写好完整的思路,甚至包括需要声明几个变量。这样虽然一开始可能觉得速度有点慢,但这样会让你在真正写代码时思路清晰,从而少犯错误,并且我觉得这种写代码的状态更好。到后来我在写算法的时候甚至不是从上到下的编写,而是先写算法的框架,再写每一个部分要完成的功能。自我认为,这是比较好的敲代码的方法,并且可以增加自己纸上代码的能力。
5. 一定不要满足自己的算法,尽可能写出最简单的代码,即使是相同的思路,也一定要将代码减至无法再减为止。这样可以增加自己的代码质量,久而久之,你对这门语言的掌控能力也会得到提升。
刷算法的网站:
力扣:https://leetcode-cn.com/problemset/all/
牛客网:https://www.nowcoder.com/ta/job-code-high
一、基础算法题
1. 判断身份证:要么是15位,要么是18位,最后一位可以为字母,并写程序提出其中的年月日。
参考知识点:java正则表达式http://www.cnblogs.com/leeSmall/p/7627327.html
正则表达式(\\d{17}[0-9a-zA-Z]|\\d{14}[0-9a-zA-Z])判断是否为合法的15位或18位身份证号码。
正则表达式\\d{6}(\\d{8}).*提取出生日字符串
正则表达式(\\d{4})(\\d{2})(\\d{2})将生日字符串进行分解为年月日
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexTest {
/**
*
* @param args
*
*/
public static void main(String[] args) {
// 测试是否为合法的身份证号码
String[] strs = { "130681198712092019", "13068119871209201x",
"13068119871209201", "123456789012345", "12345678901234x",
"1234567890123" };
Pattern p1 = Pattern.compile("(\\d{17}[0-9a-zA-Z]|\\d{14}[0-9a-zA-Z])");
for (int i = 0; i < strs.length; i++) {
Matcher matcher = p1.matcher(strs[i]);
System.out.println(strs[i] + ":" + matcher.matches());
}
System.out.println("-------------------------------");
Pattern p2 = Pattern.compile("\\d{6}(\\d{8}).*"); // 用于提取出生日字符串
Pattern p3 = Pattern.compile("(\\d{4})(\\d{2})(\\d{2})");// 用于将生日字符串进行分解为年月日
for (int i = 0; i < strs.length; i++) {
Matcher matcher = p2.matcher(strs[i]);
boolean b = matcher.find();
if (b) {
String s = matcher.group(1);
Matcher matcher2 = p3.matcher(s);
if (matcher2.find()) {
System.out.println("生日为" + matcher2.group(1) + "年"
+ matcher2.group(2) + "月"
+ matcher2.group(3) + "日");
}
}
}
}
}
2. 写一个Singleton出来
Singleton模式主要作用是保证在Java应用程序中,一个类Class只有一个实例存在。
一般Singleton模式通常有几种种形式:
第一种形式: 定义一个类,它的构造函数为private的,它有一个static的private的该类变量,在类初始化时实例化,通过一个public的getInstance方法获取对它的引用,继而调用其中的方法。
饱汉模式:
public class Singleton {
//定义私有构造函数
private Singleton() {
}
// 在自己内部定义自己一个实例,是不是很奇怪?
// 注意这是private 只供内部调用
private static Singleton instance = new Singleton();
// 这里提供了一个供外部访问本class的静态方法,可以直接访问
public static Singleton getInstance() {
return instance;
}
}
用枚举-枚举类中声明的每一个枚举值代表枚举类的一个实例对象
public enum SingleTon{
ONE;
}
懒汉式:
双重检查
package com.study.design.mode.service;
public class Singleton {
private static volatile Singleton singleton;
private Singleton() {
}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
3. 排序都有哪几种方法?请列举。用JAVA实现一个快速排序。
排序:冒泡排序,快速排序,选择排序,插入排序,堆排序,归并排序,计数排序,基数排序,桶排序等
冒泡排序:
基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,由小到大或者由大到小排序后输出。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
/*
* 冒泡排序
*/
public class BubbleSort {
public static void main(String[] args) {
int[] arr={6,3,8,2,9,1};
System.out.println("排序前数组为:");
for(int num:arr){
System.out.print(num+" ");
}
for(int i=0;i<arr.length-1;i++){//外层循环控制排序趟数
for(int j=0;j<arr.length-1-i;j++){//内层循环控制每一趟排序多少次
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
System.out.println();
System.out.println("排序后的数组为:");
for(int num:arr){
System.out.print(num+" ");
}
}
}
输出:1 2 3 6 8 9
参考文章:
快速排序:
基本思想:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。
/**
* 快速排序
*
* @author lgs
*
*/
public class QuickSort {
public void quickSort(int[] arr, int left, int right) {
int middle, tempDate;
int i, j;
i = left;
j = right;
middle = arr[(i + j) / 2];
do {
// 找出左边比中间值大的数
while (String.valueOf(arr[i]).compareTo(String.valueOf(middle))<0&& i < right)
i++;
// 找出右边比中间值小的数
while (String.valueOf(arr[j]).compareTo(String.valueOf(middle))>0 && j > left)
j--;
// 将左边大的数和右边小的数进行替换
if (i <= j) {
tempDate = arr[i];
arr[i] = arr[j];
arr[j] = tempDate;
i++;
j--;
}
} while (i <= j); // 当两者交错时停止
if (i < right) {
quickSort(arr, i, right);
}
if (j > left) {
quickSort(arr, left, j);
}
}
/**
* @param args
*/
public static void main(String[] args) {
int[] arr ={ 11, 66, 22, 0, 55, 22, 0, 32};
QuickSort sort = new QuickSort();
sort.quickSort(arr, 0, arr.length - 1);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i] + " ");
}
}
}
输出:0,0,11,22,22,32,55,66
有数组a[n],用java代码将数组元素顺序颠倒
import java.util.Arrays;
/**
* 数组元素顺序颠倒
* @author lgs
*
*/
public class SwapElement {
public static void main(String[] args) {
int[] a = new int[] {1,2,3,4,5,6};
System.out.println(a);
System.out.println(Arrays.toString(a));
swap(a);
System.out.println(Arrays.toString(a));
}
public static void swap(int a[]) {
int len = a.length;
for (int i = 0; i < len / 2; i++) {
int tmp = a[i];
a[i] = a[len - 1 - i];
a[len - 1 - i] = tmp;
}
}
}
输出:
[I@15db9742
[1, 2, 3, 4, 5, 6]
[6, 5, 4, 3, 2, 1]
金额转换,阿拉伯数字的金额转换成中国传统的形式如:(¥1011)->(一千零一拾一元整)输出。
public class SwapRMB {
//阿拉伯数字对应的中文数字
private static final char[] data = new char[] {
'零', '壹', '贰', '叁', '肆', '伍', '陆', '柒', '捌', '玖'
};
//与要转换的数字的个数对应的单位对应,如:元', '拾', '佰', '仟', '万', '拾', '佰', '仟', '亿', '拾'
private static final char[] units = new char[] {
'元', '拾', '佰', '仟', '万', '拾', '佰', '仟', '亿', '拾'
};
public static void main(String[] args) {
System.out.println(convert(1356891203));
}
/**
* 思想:
* 由右到左依次获取数字对应的单位,然后把要转换的金额除以10取余数作为当前单位的数字,
* 把余数和单位拼接在一起,拼接完以后把转换金额除以10取整数,如此循环下去直到要转换的金额为0时
* 拼接完的数字即为最后的结果
* @param money 要转换的金额
* @return 转换后的中文式金额
*/
public static String convert(int money)
{
StringBuffer sbf = new StringBuffer();
int unit = 0;
while (money != 0)
{
sbf.insert(0, units[unit++]);
int number = money % 10;
sbf.insert(0, data[number]);
money /= 10;
}
return sbf.toString();
}
}
手写ajax
$.ajax({
type:"post",
dataType:"json",
url:"getList.action",
data:{name:"lgs", age:"24"},
success: function(data){
if(" "!=data){
alert(eval(data.list));
}
}
});
递归算法题:
递归算法:是一种直接或者间接地调用自身的算法。在计算机编写程序中,递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于理解。
递归的原理:其实就是一个栈(stack), 比如求5的阶乘,要知道5的阶乘,就要知道4的阶乘,4又要是到3的,以此类推,所以递归式就先把5的阶乘表示入栈, 在把4的入栈,直到最后一个,之后呢在从1开始出栈, 看起来很麻烦,确实很麻烦,他的好处就是写起代码来,十分的快,而且代码简洁,其他就没什么好处了,运行效率出奇的慢
递归算法的实质:是把问题转化为规模缩小了的同类问题的子问题。然后递归调用函数(或过程)来表示问题的解。
递归算法解决问题的特点:
(1) 递归就是在过程或函数里调用自身。
(2) 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
(3) 递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
(4) 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等。所以一般不提倡用递归算法设计程序。
1. 一个整数,大于0,不用循环和本地变量,按照n,2n,4n,8n的顺序递增,当值大于5000时,把值按照指定顺序输出来。
例:n=1237
则输出为:1237,2474,4948,9896,9896,4948,2474,1237
提示:写程序时,先只写按递增方式的代码,写好递增的以后,再增加考虑递减部分。
public class Recursion {
public static void main(String[] args) {
count(1237);
}
public static void count(int n) {
//输出递增数字
System.out.println(n);
if (n <= 5000) {
//按照两倍递增
n*=2;
count(n);
//按照两倍递减
n/=2;
}
//输出递减数字
System.out.println(n);
}
}
输出:1237,2474,4948,9896,9896,4948,2474,1237
2. 第1个人10,第2个比第1个人大2岁,依次递推,请用递归方式计算出第8个人多大?
public class Recursion
{
public static void main(String[] args)
{
System.out.println(computeAge(8));
}
public static int computeAge(int n)
{
if (n == 1)
{
return 10;
}
return computeAge(n - 1) + 2;
}
}
输出:24
二、几道常见的子符串算法题
1. KMP 算法
谈到字符串问题,不得不提的就是 KMP 算法,它是用来解决字符串查找的问题,可以在一个字符串(S)中查找一个子串(W)出现的位置。KMP 算法把字符匹配的时间复杂度缩小到 O(m+n) ,而空间复杂度也只有O(m)。因为“暴力搜索”的方法会反复回溯主串,导致效率低下,而KMP算法可以利用已经部分匹配这个有效信息,保持主串上的指针不回溯,通过修改子串的指针,让模式串尽量地移动到有效的位置。
具体算法细节:
链接:https://www.zhihu.com/question/21923021/answer/281346746
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
有些算法,适合从它产生的动机,如何设计与解决问题这样正向地去介绍。但KMP算法真的不适合这样去学。最好的办法是先搞清楚它所用的数据结构是什么,再搞清楚怎么用,最后为什么的问题就会有恍然大悟的感觉。我试着从这个思路再介绍一下。大家只需要记住一点,PMT是什么东西。然后自己临时推这个算法也是能推出来的,完全不需要死记硬背。
KMP算法的核心,是一个被称为部分匹配表(Partial Match Table)的数组。我觉得理解KMP的最大障碍就是很多人在看了很多关于KMP的文章之后,仍然搞不懂PMT中的值代表了什么意思。这里我们抛开所有的枝枝蔓蔓,先来解释一下这个数据到底是什么。
对于字符串“abababca”,它的PMT如下表所示:
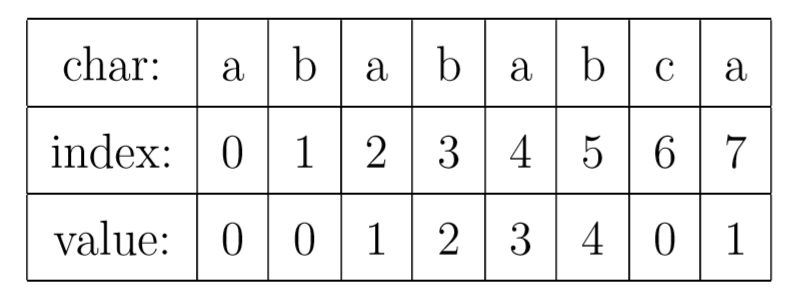
就像例子中所示的,如果待匹配的模式字符串有8个字符,那么PMT就会有8个值。
我先解释一下字符串的前缀和后缀。如果字符串A和B,存在A=BS,其中S是任意的非空字符串,那就称B为A的前缀。例如,”Harry”的前缀包括{”H”, ”Ha”, ”Har”, ”Harr”},我们把所有前缀组成的集合,称为字符串的前缀集合。同样可以定义后缀A=SB, 其中S是任意的非空字符串,那就称B为A的后缀,例如,”Potter”的后缀包括{”otter”, ”tter”, ”ter”, ”er”, ”r”},然后把所有后缀组成的集合,称为字符串的后缀集合。要注意的是,字符串本身并不是自己的后缀。
有了这个定义,就可以说明PMT中的值的意义了。PMT中的值是字符串的前缀集合与后缀集合的交集中最长元素的长度。例如,对于”aba”,它的前缀集合为{”a”, ”ab”},后缀 集合为{”ba”, ”a”}。两个集合的交集为{”a”},那么长度最长的元素就是字符串”a”了,长 度为1,所以对于”aba”而言,它在PMT表中对应的值就是1。再比如,对于字符串”ababa”,它的前缀集合为{”a”, ”ab”, ”aba”, ”abab”},它的后缀集合为{”baba”, ”aba”, ”ba”, ”a”}, 两个集合的交集为{”a”, ”aba”},其中最长的元素为”aba”,长度为3。
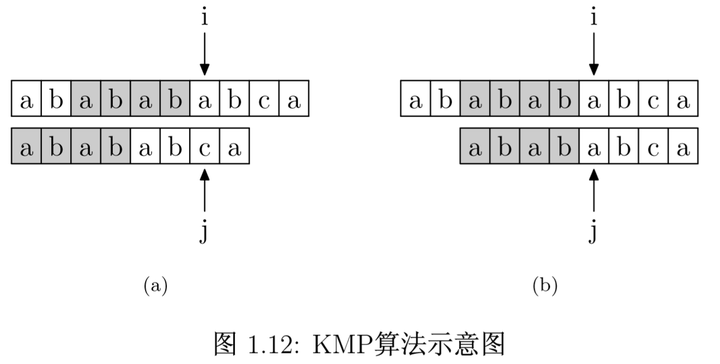
好了,解释清楚这个表是什么之后,我们再来看如何使用这个表来加速字符串的查找,以及这样用的道理是什么。如图 1.12 所示,要在主字符串"ababababca"中查找模式字符串"abababca"。如果在 j 处字符不匹配,那么由于前边所说的模式字符串 PMT 的性质,主字符串中 i 指针之前的 PMT[j −1] 位就一定与模式字符串的第 0 位至第 PMT[j−1] 位是相同的。这是因为主字符串在 i 位失配,也就意味着主字符串从 i−j 到 i 这一段是与模式字符串的 0 到 j 这一段是完全相同的。而我们上面也解释了,模式字符串从 0 到 j−1 ,在这个例子中就是”ababab”,其前缀集合与后缀集合的交集的最长元素为”abab”, 长度为4。所以就可以断言,主字符串中i指针之前的 4 位一定与模式字符串的第0位至第 4 位是相同的,即长度为 4 的后缀与前缀相同。这样一来,我们就可以将这些字符段的比较省略掉。具体的做法是,保持i指针不动,然后将j指针指向模式字符串的PMT[j −1]位即可。
简言之,以图中的例子来说,在 i 处失配,那么主字符串和模式字符串的前边6位就是相同的。又因为模式字符串的前6位,它的前4位前缀和后4位后缀是相同的,所以我们推知主字符串i之前的4位和模式字符串开头的4位是相同的。就是图中的灰色部分。那这部分就不用再比较了。
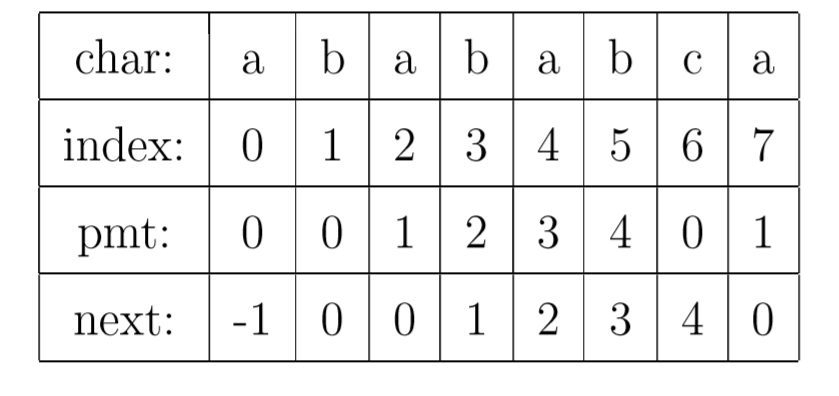
有了上面的思路,我们就可以使用PMT加速字符串的查找了。我们看到如果是在 j 位 失配,那么影响 j 指针回溯的位置的其实是第 j −1 位的 PMT 值,所以为了编程的方便, 我们不直接使用PMT数组,而是将PMT数组向后偏移一位。我们把新得到的这个数组称为next数组。下面给出根据next数组进行字符串匹配加速的字符串匹配程序。其中要注意的一个技巧是,在把PMT进行向右偏移时,第0位的值,我们将其设成了-1,这只是为了编程的方便,并没有其他的意义。在本节的例子中,next数组如下表所示。
具体的程序如下所示:
int KMP(char * t, char * p)
{
int i = 0;
int j = 0;
while (i < strlen(t) && j < strlen(p))
{
if (j == -1 || t[i] == p[j])
{
i++;
j++;
}
else
j = next[j];
}
if (j == strlen(p))
return i - j;
else
return -1;
}
好了,讲到这里,其实KMP算法的主体就已经讲解完了。你会发现,其实KMP算法的动机是很简单的,解决的方案也很简单。远没有很多教材和算法书里所讲的那么乱七八糟,只要搞明白了PMT的意义,其实整个算法都迎刃而解。
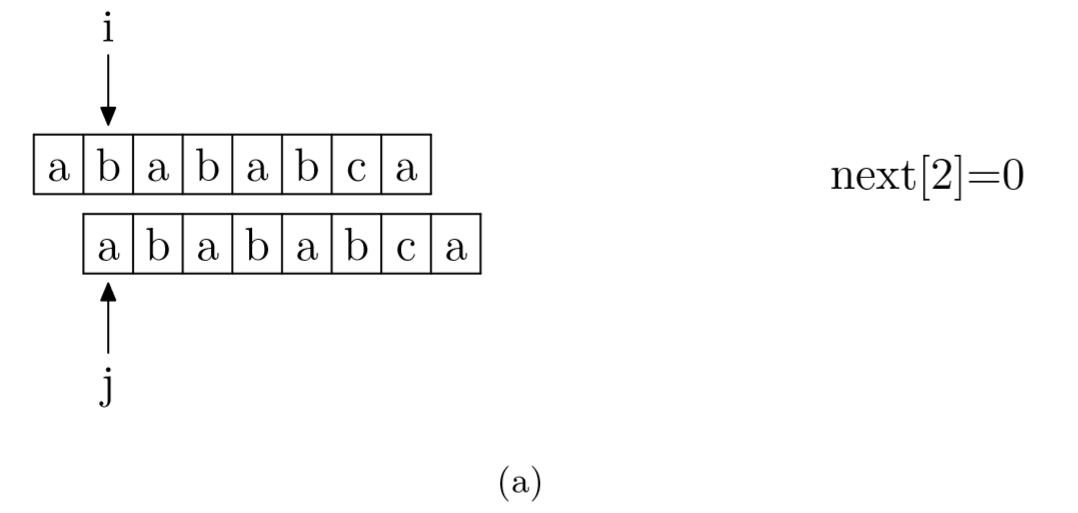
现在,我们再看一下如何编程快速求得next数组。其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。
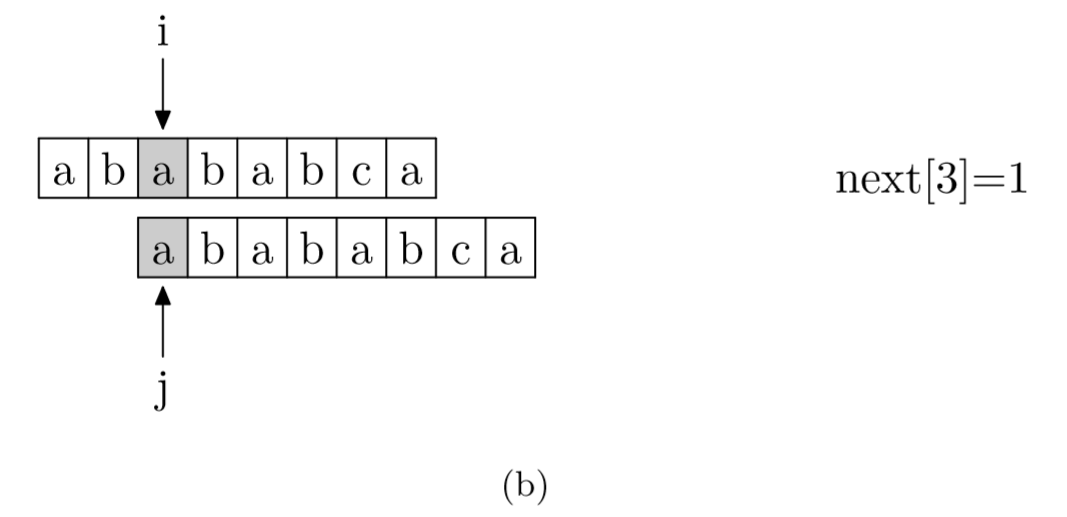
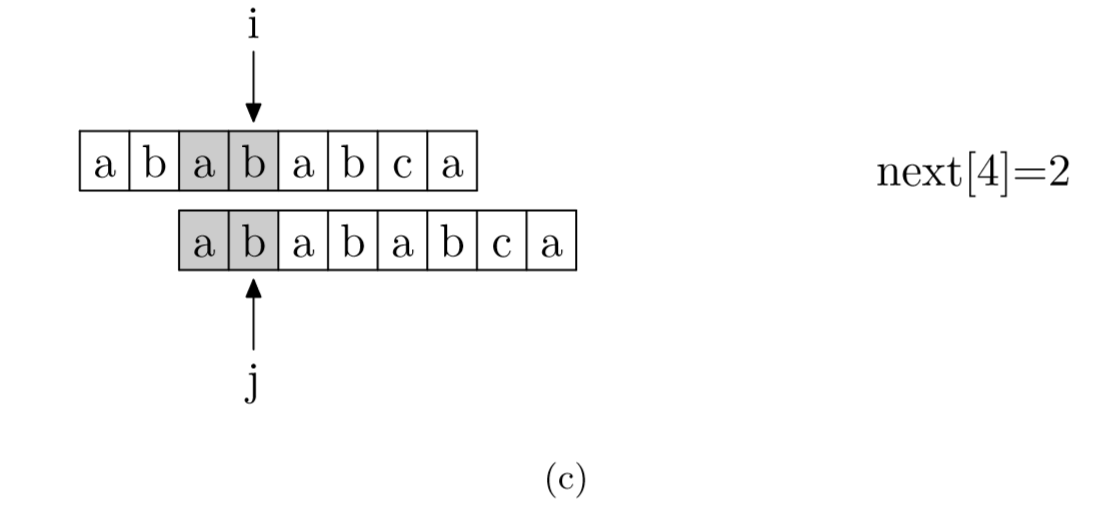
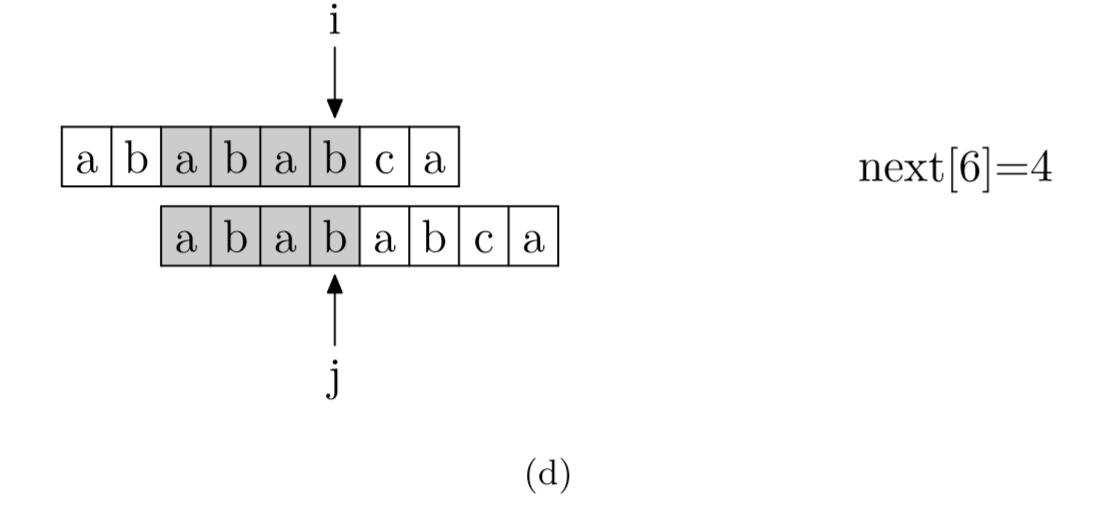
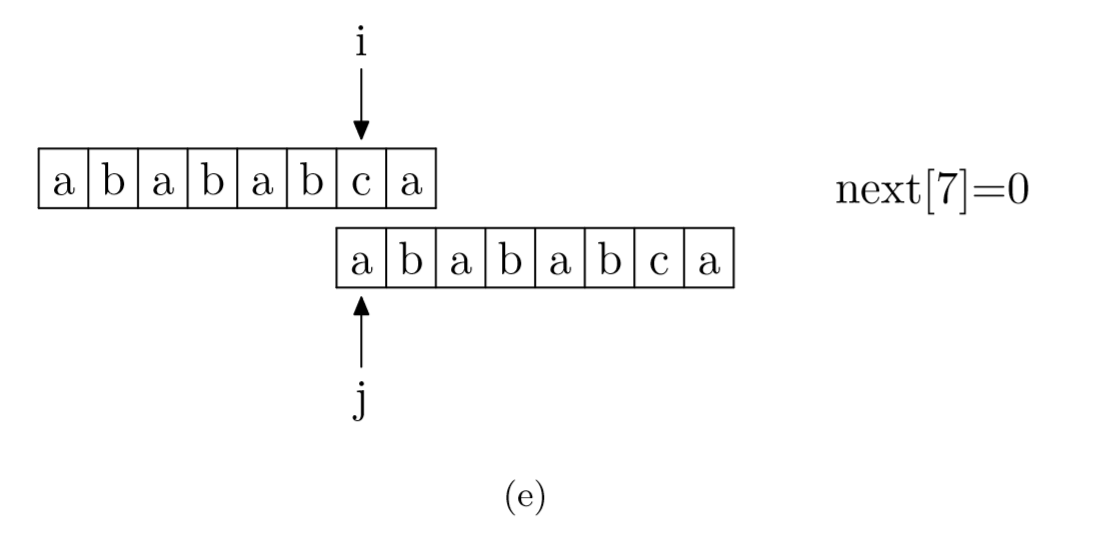
求next数组值的程序如下所示:
void getNext(char * p, int * next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(p))
{
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j];
}
}
至此,KMP算法就全部介绍完了
2. 替换空格
剑指offer:请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
这里我提供了两种方法:①常规方法;②利用 API 解决。
//https://www.weiweiblog.cn/replacespace/ public class Solution { /** * 第一种方法:常规方法。利用String.charAt(i)以及String.valueOf(char).equals(" " * )遍历字符串并判断元素是否为空格。是则替换为"%20",否则不替换 */ public static String replaceSpace(StringBuffer str) { int length = str.length(); // System.out.println("length=" + length); StringBuffer result = new StringBuffer(); for (int i = 0; i < length; i++) { char b = str.charAt(i); if (String.valueOf(b).equals(" ")) { result.append("%20"); } else { result.append(b); } } return result.toString(); } /** * 第二种方法:利用API替换掉所用空格,一行代码解决问题 */ public static String replaceSpace2(StringBuffer str) { return str.toString().replaceAll("\\s", "%20"); } }
3. 最长公共前缀
Leetcode: 编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
思路很简单!先利用Arrays.sort(strs)为数组排序,再将数组第一个元素和最后一个元素的字符从前往后对比即可!
public class Main { public static String replaceSpace(String[] strs) { // 如果检查值不合法及就返回空串 if (!chechStrs(strs)) { return ""; } // 数组长度 int len = strs.length; // 用于保存结果 StringBuilder res = new StringBuilder(); // 给字符串数组的元素按照升序排序(包含数字的话,数字会排在前面) Arrays.sort(strs); int m = strs[0].length(); int n = strs[len - 1].length(); int num = Math.min(m, n); for (int i = 0; i < num; i++) { if (strs[0].charAt(i) == strs[len - 1].charAt(i)) { res.append(strs[0].charAt(i)); } else break; } return res.toString(); } private static boolean chechStrs(String[] strs) { boolean flag = false; // 注意:=是赋值,==是判断 if (strs != null) { // 遍历strs检查元素值 for (int i = 0; i < strs.length; i++) { if (strs[i] != null && strs[i].length() != 0) { flag = true; } else { flag = false; } } } return flag; } // 测试 public static void main(String[] args) { String[] strs = { "customer", "car", "cat" }; // String[] strs = { "customer", "car", null };//空串 // String[] strs = {};//空串 // String[] strs = null;//空串 System.out.println(Main.replaceSpace(strs));// c } }
4. 回文串
4.1. 最长回文串
LeetCode: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。在构造过程中,请注意区分大小写。比如"Aa"不能当做一个回文字符串。注 意:假设字符串的长度不会超过 1010。
回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin
示例 1:
输入:
"abccccdd"
输出:
7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
我们上面已经知道了什么是回文串?现在我们考虑一下可以构成回文串的两种情况:
- 字符出现次数为双数的组合
- 字符出现次数为双数的组合+一个只出现一次的字符
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在hashset中,如果不在就加进去,如果在就让count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
//https://leetcode-cn.com/problems/longest-palindrome/description/ class Solution { public int longestPalindrome(String s) { if (s.length() == 0) return 0; // 用于存放字符 HashSet<Character> hashset = new HashSet<Character>(); char[] chars = s.toCharArray(); int count = 0; for (int i = 0; i < chars.length; i++) { if (!hashset.contains(chars[i])) {// 如果hashset没有该字符就保存进去 hashset.add(chars[i]); } else {// 如果有,就让count++(说明找到了一个成对的字符),然后把该字符移除 hashset.remove(chars[i]); count++; } } return hashset.isEmpty() ? count * 2 : count * 2 + 1; } }
4.2. 验证回文串
LeetCode: 给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。 说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false//https://leetcode-cn.com/problems/valid-palindrome/description/ class Solution { public boolean isPalindrome(String s) { if (s.length() == 0) return true; int l = 0, r = s.length() - 1; while (l < r) { // 从头和尾开始向中间遍历 if (!Character.isLetterOrDigit(s.charAt(l))) {// 字符不是字母和数字的情况 l++; } else if (!Character.isLetterOrDigit(s.charAt(r))) {// 字符不是字母和数字的情况 r--; } else { // 判断二者是否相等 if (Character.toLowerCase(s.charAt(l)) != Character.toLowerCase(s.charAt(r))) return false; l++; r--; } } return true; } }
4.3. 最长回文子串
Leetcode: LeetCode: 最长回文子串 给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba"也是一个有效答案。
示例 2:
输入: "cbbd"
输出: "bb"
以某个元素为中心,分别计算偶数长度的回文最大长度和奇数长度的回文最大长度。给大家大致花了个草图,不要嫌弃!
//https://leetcode-cn.com/problems/longest-palindromic-substring/description/ class Solution { private int index, len; public String longestPalindrome(String s) { if (s.length() < 2) return s; for (int i = 0; i < s.length() - 1; i++) { PalindromeHelper(s, i, i); PalindromeHelper(s, i, i + 1); } return s.substring(index, index + len); } public void PalindromeHelper(String s, int l, int r) { while (l >= 0 && r < s.length() && s.charAt(l) == s.charAt(r)) { l--; r++; } if (len < r - l - 1) { index = l + 1; len = r - l - 1; } } }
4.4. 最长回文子序列
LeetCode: 最长回文子序列 给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。 最长回文子序列和上一题最长回文子串的区别是,子串是字符串中连续的一个序列,而子序列是字符串中保持相对位置的字符序列,例如,"bbbb"可以是字符串"bbbab"的子序列但不是子串。
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
示例 1:
输入:
"bbbab"
输出:
4
一个可能的最长回文子序列为 "bbbb"。
示例 2:
输入:
"cbbd"
输出:
2
一个可能的最长回文子序列为 "bb"。
动态规划: dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])
class Solution { public int longestPalindromeSubseq(String s) { int len = s.length(); int [][] dp = new int[len][len]; for(int i = len - 1; i>=0; i--){ dp[i][i] = 1; for(int j = i+1; j < len; j++){ if(s.charAt(i) == s.charAt(j)) dp[i][j] = dp[i+1][j-1] + 2; else dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1]); } } return dp[0][len-1]; } }
5. 括号匹配深度
爱奇艺 2018 秋招 Java: 一个合法的括号匹配序列有以下定义:
- 空串""是一个合法的括号匹配序列
- 如果"X"和"Y"都是合法的括号匹配序列,"XY"也是一个合法的括号匹配序列
- 如果"X"是一个合法的括号匹配序列,那么"(X)"也是一个合法的括号匹配序列
- 每个合法的括号序列都可以由以上规则生成。
例如: "","()","()()","((()))"都是合法的括号序列 对于一个合法的括号序列我们又有以下定义它的深度:
- 空串""的深度是0
- 如果字符串"X"的深度是x,字符串"Y"的深度是y,那么字符串"XY"的深度为max(x,y)
- 如果"X"的深度是x,那么字符串"(X)"的深度是x+1
例如: "()()()"的深度是1,"((()))"的深度是3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
输入描述:
输入包括一个合法的括号序列s,s长度length(2 ≤ length ≤ 50),序列中只包含'('和')'。
输出描述:
输出一个正整数,即这个序列的深度。
示例:
输入:
(())
输出:
2
思路草图:
代码如下:
import java.util.Scanner; /** * https://www.nowcoder.com/test/8246651/summary * * @author Snailclimb * @date 2018年9月6日 * @Description: TODO 求给定合法括号序列的深度 */ public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); String s = sc.nextLine(); int cnt = 0, max = 0, i; for (i = 0; i < s.length(); ++i) { if (s.charAt(i) == '(') cnt++; else cnt--; max = Math.max(max, cnt); } sc.close(); System.out.println(max); } }
6. 把字符串转换成整数
剑指offer: 将一个字符串转换成一个整数(实现Integer.valueOf(string)的功能,但是string不符合数字要求时返回0),要求不能使用字符串转换整数的库函数。 数值为0或者字符串不是一个合法的数值则返回0。
//https://www.weiweiblog.cn/strtoint/ public class Main { public static int StrToInt(String str) { if (str.length() == 0) return 0; char[] chars = str.toCharArray(); // 判断是否存在符号位 int flag = 0; if (chars[0] == '+') flag = 1; else if (chars[0] == '-') flag = 2; int start = flag > 0 ? 1 : 0; int res = 0;// 保存结果 for (int i = start; i < chars.length; i++) { if (Character.isDigit(chars[i])) {// 调用Character.isDigit(char)方法判断是否是数字,是返回True,否则False int temp = chars[i] - '0'; res = res * 10 + temp; } else { return 0; } } return flag == 1 ? res : -res; } public static void main(String[] args) { // TODO Auto-generated method stub String s = "-12312312"; System.out.println("使用库函数转换:" + Integer.valueOf(s)); int res = Main.StrToInt(s); System.out.println("使用自己写的方法转换:" + res); } }
三、剑指offer部分编程题
1. 斐波那契数列
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,
指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
总结:从第3个数开始,后一个数等于前两个数相加
题目描述:
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。 n<=39
问题分析:
可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用fn1和fn2保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
斐波那契数列:1、1、2、3、5、8、13、21、34、……
示例代码:
采用迭代法:
package com.study.demo.Caculate; /** * Hello world! * */ public class App { static int Fibonacci(int number) { if (number <= 0) { return 0; } if (number == 1 || number == 2) { return 1; } int first = 1, second = 1, third = 0; for (int i = 3; i <= number; i++) { third = first + second; first = second; second = third; } return third; } public static void main(String[] args) { System.out.println(Fibonacci(1)); System.out.println(Fibonacci(2)); System.out.println(Fibonacci(3)); System.out.println(Fibonacci(4)); System.out.println(Fibonacci(5)); System.out.println(Fibonacci(6)); } }
输出:
1
1
2
3
5
8
采用递归:
public int Fibonacci(int n) { if (n <= 0) { return 0; } if (n == 1||n==2) { return 1; } return Fibonacci(n - 2) + Fibonacci(n - 1); }
运行时间对比:
假设n为40我们分别使用迭代法和递归法计算,计算结果如下:
- 迭代法
- 递归法


2. 跳台阶问题
题目描述:
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
问题分析:
正常分析法: a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1); b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2) c.由a,b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2) d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2 找规律分析法: f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出f(n) = f(n-1) + f(n-2)的规律。 但是为什么会出现这样的规律呢?假设现在6个台阶,我们可以从第5跳一步到6,这样的话有多少种方案跳到5就有多少种方案跳到6,另外我们也可以从4跳两步跳到6,跳到4有多少种方案的话,就有多少种方案跳到6,其他的不能从3跳到6什么的啦,所以最后就是f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
所以这道题其实就是斐波那契数列的问题。 代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
示例代码:
int jumpFloor(int number) { if (number <= 0) { return 0; } if (number == 1) { return 1; } if (number == 2) { return 2; } int first = 1, second = 2, third = 0; for (int i = 3; i <= number; i++) { third = first + second; first = second; second = third; } return third; }
3. 变态跳台阶问题
题目描述:
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
问题分析:
假设n>=2,第一步有n种跳法:
跳1级、跳2级、到跳n级
跳1级,剩下n-1级,则剩下跳法是f(n-1)
跳2级,剩下n-2级,则剩下跳法是f(n-2) ......
跳n-1级,剩下1级,则剩下跳法是f(1)
跳n级,剩下0级,则剩下跳法是f(0)
所以在n>=2的情况下: f(n)=f(n-1)+f(n-2)+...+f(1) 因为f(n-1)=f(n-2)+f(n-3)+...+f(1) 所以f(n)=2*f(n-1) 又f(1)=1,所以可得f(n)=2^(number-1)
示例代码:
int JumpFloorII(int number) { return 1 << --number;//2^(number-1)用位移操作进行,更快 }
补充:
java中有三种移位运算符:
- “<<” : 左移运算符,等同于乘2的n次方
- “>>”: 右移运算符,等同于除2的n次方
- “>>>” 无符号右移运算符,不管移动前最高位是0还是1,右移后左侧产生的空位部分都以0来填充。与>>类似。 例: int a = 16; int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4 int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
4. 二维数组查找
题目描述:
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
问题解析:
这一道题还是比较简单的,我们需要考虑的是如何做,效率最快。这里有一种很好理解的思路:
矩阵是有序的,从左下角来看,向上数字递减,向右数字递增, 因此从左下角开始查找,当要查找数字比左下角数字大时右移,要查找数字比左下角数字小时上移。这样找的速度最快。
示例代码:
public boolean Find(int target, int [][] array) { //基本思路从左下角开始找,这样速度最快 int row = array.length-1;//行 int column = 0;//列 //当行数大于0,当前列数小于总列数时循环条件成立 while((row >= 0)&& (column< array[0].length)){ if(array[row][column] > target){ row--; }else if(array[row][column] < target){ column++; }else{ return true; } } return false; }
5. 替换空格
题目描述:
请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
问题分析:
这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用append()方法添加追加“%20”,否则还是追加原字符。
或者最简单的方法就是利用: replaceAll(String regex,String replacement)方法了,一行代码就可以解决。
示例代码:
常规做法:
public String replaceSpace(StringBuffer str) { StringBuffer out=new StringBuffer(); for (int i = 0; i < str.toString().length(); i++) { char b=str.charAt(i); if(String.valueOf(b).equals(" ")){ out.append("%20"); }else{ out.append(b); } } return out.toString(); }
一行代码解决:
public String replaceSpace(StringBuffer str) { //return str.toString().replaceAll(" ", "%20"); //public String replaceAll(String regex,String replacement) //用给定的替换替换与给定的regular expression匹配的此字符串的每个子字符串。 //\ 转义字符. 如果你要使用 "\" 本身, 则应该使用 "\\". String类型中的空格用“\s”表示,所以我这里猜测"\\s"就是代表空格的意思 return str.toString().replaceAll("\\s", "%20"); }
6. 数值的整数次方
题目描述:
给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
问题解析:
这道题算是比较麻烦和难一点的一个了。我这里采用的是二分幂思想,当然也可以采用快速幂。 更具剑指offer书中细节,该题的解题思路如下: 1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于0,由于base为double型,所以不能直接用==判断 3.优化求幂函数(二分幂)。 当n为偶数,a^n =(a^n/2)*(a^n/2); 当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
时间复杂度:O(logn)
示例代码:
public class Solution { boolean invalidInput=false; public double Power(double base, int exponent) { //如果底数等于0并且指数小于0 //由于base为double型,不能直接用==判断 if(equal(base,0.0)&&exponent<0){ invalidInput=true; return 0.0; } int absexponent=exponent; //如果指数小于0,将指数转正 if(exponent<0) absexponent=-exponent; //getPower方法求出base的exponent次方。 double res=getPower(base,absexponent); //如果指数小于0,所得结果为上面求的结果的倒数 if(exponent<0) res=1.0/res; return res; } //比较两个double型变量是否相等的方法 boolean equal(double num1,double num2){ if(num1-num2>-0.000001&&num1-num2<0.000001) return true; else return false; } //求出b的e次方的方法 double getPower(double b,int e){ //如果指数为0,返回1 if(e==0) return 1.0; //如果指数为1,返回b if(e==1) return b; //e>>1相等于e/2,这里就是求a^n =(a^n/2)*(a^n/2) double result=getPower(b,e>>1); result*=result; //如果指数n为奇数,则要再乘一次底数base if((e&1)==1) result*=b; return result; } }
当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为O(n),这样没有前一种方法效率高。
// 使用累乘 public double powerAnother(double base, int exponent) { double result = 1.0; for (int i = 0; i < Math.abs(exponent); i++) { result *= base; } if (exponent >= 0) return result; else return 1 / result; }
7. 调整数组顺序使奇数位于偶数前面
题目描述:
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
问题解析:
这道题有挺多种解法的,给大家介绍一种我觉得挺好理解的方法: 我们首先统计奇数的个数假设为n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标0的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为n的元素开始把该偶数添加到新数组中。
示例代码:
时间复杂度为O(n),空间复杂度为O(n)的算法
public class Solution { public void reOrderArray(int [] array) { //如果数组长度等于0或者等于1,什么都不做直接返回 if(array.length==0||array.length==1) return; //oddCount:保存奇数个数 //oddBegin:奇数从数组头部开始添加 int oddCount=0,oddBegin=0; //新建一个数组 int[] newArray=new int[array.length]; //计算出(数组中的奇数个数)开始添加元素 for(int i=0;i<array.length;i++){ if((array[i]&1)==1) oddCount++; } for(int i=0;i<array.length;i++){ //如果数为基数新数组从头开始添加元素 //如果为偶数就从oddCount(数组中的奇数个数)开始添加元素 if((array[i]&1)==1) newArray[oddBegin++]=array[i]; else newArray[oddCount++]=array[i]; } for(int i=0;i<array.length;i++){ array[i]=newArray[i]; } } }
8. 链表中倒数第k个节点
题目描述:
输入一个链表,输出该链表中倒数第k个结点
问题分析:
一句话概括: 两个指针一个指针p1先开始跑,指针p1跑到k-1个节点后,另一个节点p2开始跑,当p1跑到最后时,p2所指的指针就是倒数第k个节点。
思想的简单理解: 前提假设:链表的结点个数(长度)为n。 规律一:要找到倒数第k个结点,需要向前走多少步呢?比如倒数第一个结点,需要走n步,那倒数第二个结点呢?很明显是向前走了n-1步,所以可以找到规律是找到倒数第k个结点,需要向前走n-k+1步。 算法开始:
- 设两个都指向head的指针p1和p2,当p1走了k-1步的时候,停下来。p2之前一直不动。
- p1的下一步是走第k步,这个时候,p2开始一起动了。至于为什么p2这个时候动呢?看下面的分析。
- 当p1走到链表的尾部时,即p1走了n步。由于我们知道p2是在p1走了k-1步才开始动的,也就是说p1和p2永远差k-1步。所以当p1走了n步时,p2走的应该是在n-(k-1)步。即p2走了n-k+1步,此时巧妙的是p2正好指向的是规律一的倒数第k个结点处。 这样是不是很好理解了呢?
考察内容:
链表+代码的鲁棒性
示例代码:
/* //链表类 public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }*/ //时间复杂度O(n),一次遍历即可 public class Solution { public ListNode FindKthToTail(ListNode head,int k) { ListNode pre=null,p=null; //两个指针都指向头结点 p=head; pre=head; //记录k值 int a=k; //记录节点的个数 int count=0; //p指针先跑,并且记录节点数,当p指针跑了k-1个节点后,pre指针开始跑, //当p指针跑到最后时,pre所指指针就是倒数第k个节点 while(p!=null){ p=p.next; count++; if(k<1){ pre=pre.next; } k--; } //如果节点个数小于所求的倒数第k个节点,则返回空 if(count<a) return null; return pre; } }
9. 反转链表
题目描述:
输入一个链表,反转链表后,输出链表的所有元素。
问题分析:
链表的很常规的一道题,这一道题思路不算难,但自己实现起来真的可能会感觉无从下手,我是参考了别人的代码。 思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。 就比如下图:我们把1节点和2节点互换位置,然后再将3节点指向2节点,4节点指向3节点,这样以来下面的链表就被反转了。
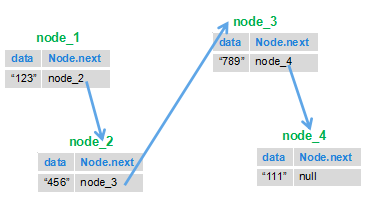
考察内容:
链表+代码的鲁棒性
示例代码:
/* public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }*/ public class Solution { public ListNode ReverseList(ListNode head) { ListNode next = null; ListNode pre = null; while (head != null) { //保存要反转到头来的那个节点 next = head.next; //要反转的那个节点指向已经反转的上一个节点 head.next = pre; //上一个已经反转到头部的节点 pre = head; //一直向链表尾走 head = next; } return pre; } }
10. 合并两个排序的链表
题目描述:
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
问题分析:
我们可以这样分析:
- 假设我们有两个链表 A,B;
- A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
- A2再和B1比较,假设B1小,则,A1指向B1;
- A2再和B2比较。。。。。。。 就这样循环往复就行了,应该还算好理解。
考察内容:
链表+代码的鲁棒性
示例代码:
非递归版本:
/* public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }*/ public class Solution { public ListNode Merge(ListNode list1,ListNode list2) { //list1为空,直接返回list2 if(list1 == null){ return list2; } //list2为空,直接返回list1 if(list2 == null){ return list1; } ListNode mergeHead = null; ListNode current = null; //当list1和list2不为空时 while(list1!=null && list2!=null){ //取较小值作头结点 if(list1.val <= list2.val){ if(mergeHead == null){ mergeHead = current = list1; }else{ current.next = list1; //current节点保存list1节点的值因为下一次还要用 current = list1; } //list1指向下一个节点 list1 = list1.next; }else{ if(mergeHead == null){ mergeHead = current = list2; }else{ current.next = list2; //current节点保存list2节点的值因为下一次还要用 current = list2; } //list2指向下一个节点 list2 = list2.next; } } if(list1 == null){ current.next = list2; }else{ current.next = list1; } return mergeHead; } }
递归版本:
public ListNode Merge(ListNode list1,ListNode list2) { if(list1 == null){ return list2; } if(list2 == null){ return list1; } if(list1.val <= list2.val){ list1.next = Merge(list1.next, list2); return list1; }else{ list2.next = Merge(list1, list2.next); return list2; } }
11. 用两个栈实现队列
题目描述:
用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
问题分析:
先来回顾一下栈和队列的基本特点: **栈:**后进先出(LIFO) 队列: 先进先出 很明显我们需要根据JDK给我们提供的栈的一些基本方法来实现。先来看一下Stack类的一些基本方法:
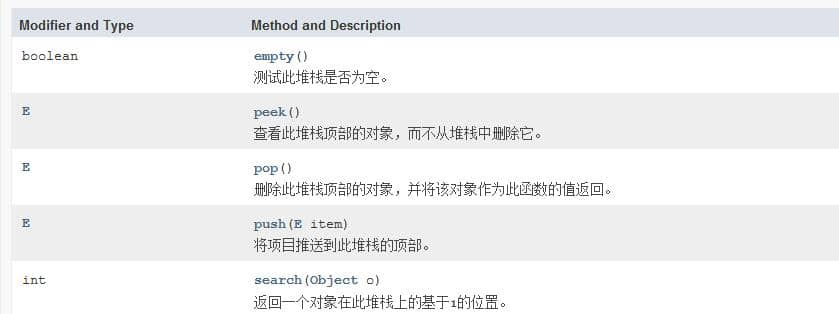
既然题目给了我们两个栈,我们可以这样考虑当push的时候将元素push进stack1,pop的时候我们先把stack1的元素pop到stack2,然后再对stack2执行pop操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
考察内容:
队列+栈
示例代码:
//左程云的《程序员代码面试指南》的答案 import java.util.Stack; public class Solution { Stack<Integer> stack1 = new Stack<Integer>(); Stack<Integer> stack2 = new Stack<Integer>(); //当执行push操作时,将元素添加到stack1 public void push(int node) { stack1.push(node); } public int pop() { //如果两个队列都为空则抛出异常,说明用户没有push进任何元素 if(stack1.empty()&&stack2.empty()){ throw new RuntimeException("Queue is empty!"); } //如果stack2不为空直接对stack2执行pop操作, if(stack2.empty()){ while(!stack1.empty()){ //将stack1的元素按后进先出push进stack2里面 stack2.push(stack1.pop()); } } return stack2.pop(); } }
12. 栈的压入,弹出序列
题目描述:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
题目分析:
这道题想了半天没有思路,参考了Alias的答案,他的思路写的也很详细应该很容易看懂。 作者:Aliashttps://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106 来源:牛客网
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
举例:
入栈1,2,3,4,5
出栈4,5,3,2,1
首先1入辅助栈,此时栈顶1≠4,继续入栈2
此时栈顶2≠4,继续入栈3
此时栈顶3≠4,继续入栈4
此时栈顶4=4,出栈4,弹出序列向后一位,此时为5,,辅助栈里面是1,2,3
此时栈顶3≠5,继续入栈5
此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
…. 依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
考察内容:
栈
示例代码:
import java.util.ArrayList; import java.util.Stack; //这道题没想出来,参考了Alias同学的答案:https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106 public class Solution { public boolean IsPopOrder(int [] pushA,int [] popA) { if(pushA.length == 0 || popA.length == 0) return false; Stack<Integer> s = new Stack<Integer>(); //用于标识弹出序列的位置 int popIndex = 0; for(int i = 0; i< pushA.length;i++){ s.push(pushA[i]); //如果栈不为空,且栈顶元素等于弹出序列 while(!s.empty() &&s.peek() == popA[popIndex]){ //出栈 s.pop(); //弹出序列向后一位 popIndex++; } } return s.empty(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号