Dynamic Set kNN Self-Join概述
一.问题
源于生活的问题
许多应用程序中, 数据对象可以表示为集(set)。例如, 在视频点播和社交网络服务中,用户数据由一组分别已观看的电影和一组用户 (朋友) 组成, 它们可用于推荐和信息提取。因此, 集相似自联接问题得到了广泛的研究。现有的研究假定集是静态的,但在上述应用程序中, 集是动态更新的, 这需要不断更新联接结果。如果采用原始的静态集合更新方法去更新动态集合,代价无疑是巨大的,因此我们需要寻求一种更高效,更适用于动态集合更新的方法.
简而言之,根据集合元素来确定集合的相似性;在集合元素处于动态变化时我们需要高效的算法来重新计算集合之间相似性.
问题的形式定义
-
给定一个用户集合:
-
每个拥有多个元素:
-
给定一个相似度计算方法:通常考虑的雅Jaccard 相似性 和 Cosine相似性.
其中
- 再给定最近邻的数目k,求出每个的最近的前k个集合(kNN结果).
问题的简单示例:

假设
则有
那么,
然后, 添加一个新的元素 重新计算相似度,则有
二.解决问题的思想
为了应对这一挑战, 我们首先研究动态集knn自联接问题的属性, 以观察从集更新派生的搜索空间。然后, 在这一观察的基础上, 提出了一种有效的算法。该算法采用了一种索引技术, 实现了增量相似度计算,并避免了不必要的相似度计算。
- 假设s 有一个新的元素e,则s的knn 结果可能会更改。这就提出了两个问题: 哪些集合可以新成为s的knn 结果, 我们必须更新哪些 k nn 结果?为了回答这些问题,并有效地访问它们, 我们使用了一个倒排索引和反向kNN 列表 .
- Dynamic set kNN self-join 的主要瓶颈是集合之间的相似性计算. 为了消除瓶颈并更快的更新相似度 (即在 O(1) 时间内),我们设计一中算法,我们为每个集合设定指标index, 指标为集合s和s’的差 (|s\s’|). 更进一步,我们提供了一个cost model 去决定 index的阈值, 即再确保正确性的前提下更有效率的更新kNN结果.
三.算法的描述
我们针对这个问题使用的算法是: LI-DSN-Join (Local-Index-based dynamic set kNN self-join)
符号定义
| 符号 | 描述 |
|---|---|
| 一个元素 | |
| 元素的集合 | |
| s的集合 | |
| 在集合s中插入元素e | |
| 在集合s中删除元素e | |
| s.A | s的kNN结果的集合 |
| 阈值,为kNN结果中最后一个集合(即第k个)与s的相似度 | |
| l临时的阈值 | |
| 一个反转列表,,即那些集合的kNN结果包含s | |
| s所有与有公共元素的其他集合 | |
| 倒排索引,所有I(e)的集合 | |
| s所有包含元素e的集合 | |
| $ | |
| A local-index (collection of ) of s |
具体算法
算法分为两步:
- 插入和删除之后,根据倒排索引更新所有的
- 对于,用IF-Sacn或者更新
算法1(第一步)

算法2(第一步)

算法3(第二步)

四.算法分析的结论
由于这是动态kNN集相似性自联接问题的第一个工作,因此不存在算法。因此,我们将 LI-DSN-Join 与最先进的精确集相似性联接算法 ALL 和最先进的 top-k 集相似性搜索算法Tree进行了比较.
通过理论分析,我们发现相比于ALL算法和TREE算法,LI-DSN-Join算法在动态集合更新时更快,但由于我们为每个集合增加了一些额外的信息,导致算法的空间复杂度高于其他两种算法.
LI-DSN-Join算法的时间性能
- 对于算法1,其中的每一步操作都可以在O(1)时间内完成,故其时间复杂度为
- 对于算法2,同样每一步执行时间都是常数,但需要遍历的集合与算法1不一样,我们需要遍历所有与si在执行删除操作前相交不为空集的集合,即$S’ = \left{s_j|s_j \in S,s_i\cap s_j \ne \empty \ \or e \in s_j \right} $,即算法二的时间复杂度为O(S’)
- 对于Δ-Scan,我们仅仅需要的时间,但对于IF-scan,我们需要检索所有与有公共元素的集合,并且计算其中每一个元素与,而这需要等时间,因此我们需要尽量避免IF-Scan
可见主要时间花费在第二步的更新KNN结果上.
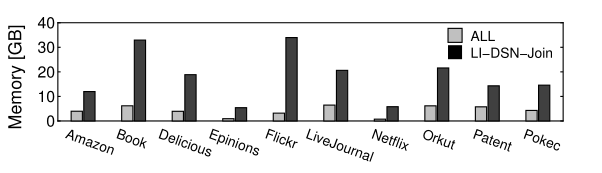
LI-DSN-Join算法的空间性能
其空间性能相比于其他两种较低, 因为本算需要额外的空间来储存倒排索引等辅助数据.
通过实验数据,验证了我们的上述结论:
1.不同应用下,随着操作规模的增加,各个算法的耗费时间:

2.不同应用下,各个算法的耗费空间:
五.举例说明算法
- 网易云音乐的音乐推荐(在线协同过滤算法):网易云音乐根据用户喜欢的音乐集合,找到和该用户相似的其他用户,再根据这些相似用户喜欢的歌来确定推荐内容,但网易云音乐并没有采用动态更新,而是等到指定时间之后对所有用户的所有改变用静态的更新方法,静态更新方法执行一次的时间消耗较大,因此我猜测这是网易云音乐一天才更新一次推荐音乐的原因
- qq的好友推荐(在线社交网络分析):在此设置中, 集和元素分别对应于他所属的用户和组, 并且显然, 新的 (某些) 元素被动态地插入 (从)相应的集合中。此分析是根据相似联接结果完成的。为了使社会网络分析有效, 必须反映最新的网络结构 , 因此动态集knn自联接是有用的。这是因为它根据最新的网络结构不断更新联接结果。结果被利用为集群相似的集合到矿人类社区和推荐潜在的朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号