MySQL实战45讲-04 深入浅出索引(上)
为什么会有索引?索引是什么?
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。
索引的常见模型
- 哈希表
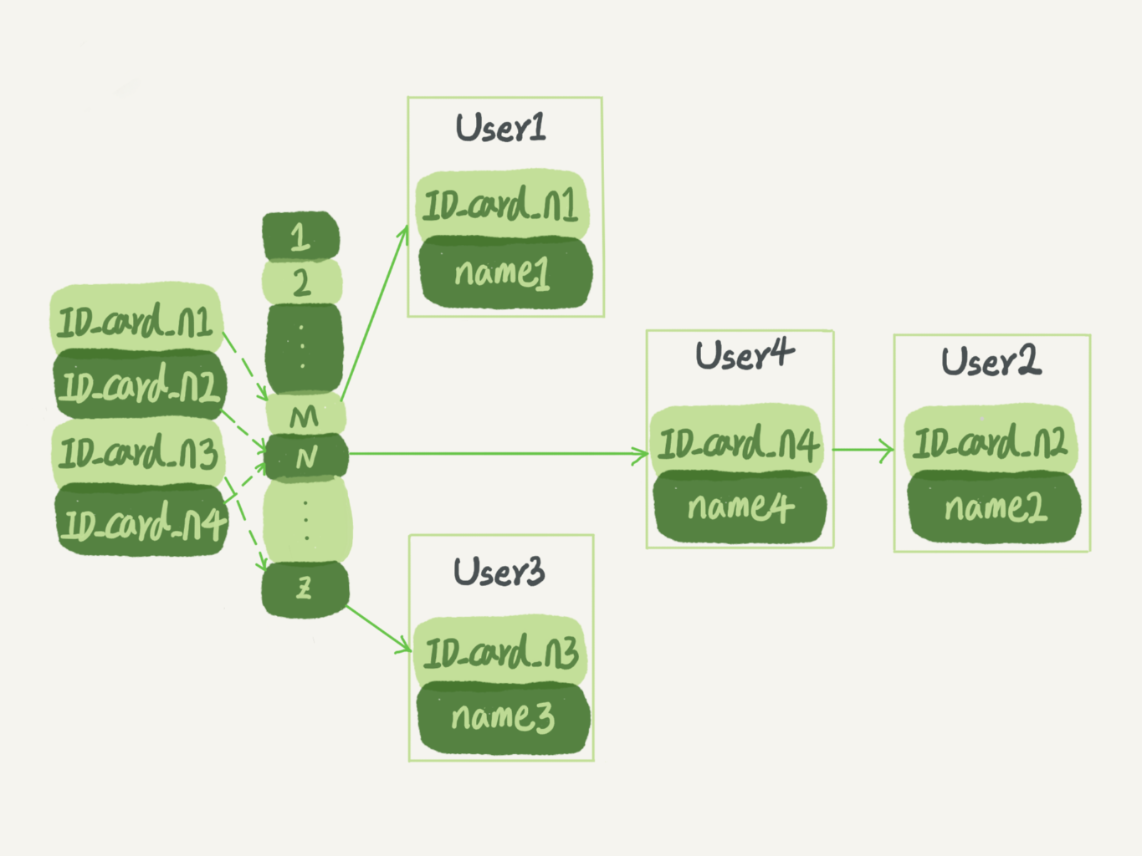
哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的键即 key,就可以找到其对应的值即 Value。适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
KV等值查询场景的意思就是,所有的查询都是where k=N,并没有>= 或者<= 这种操作(没有range操作)。
优点:
- 新增数据很快。
- 等值查询的场景速度快。
缺点:
- 区间查询的速度是很慢。比如,要找身份证号在[ID_card_X, ID_card_Y]这个区间的所有用户,就必须全部扫描一遍了。
- 有序数组
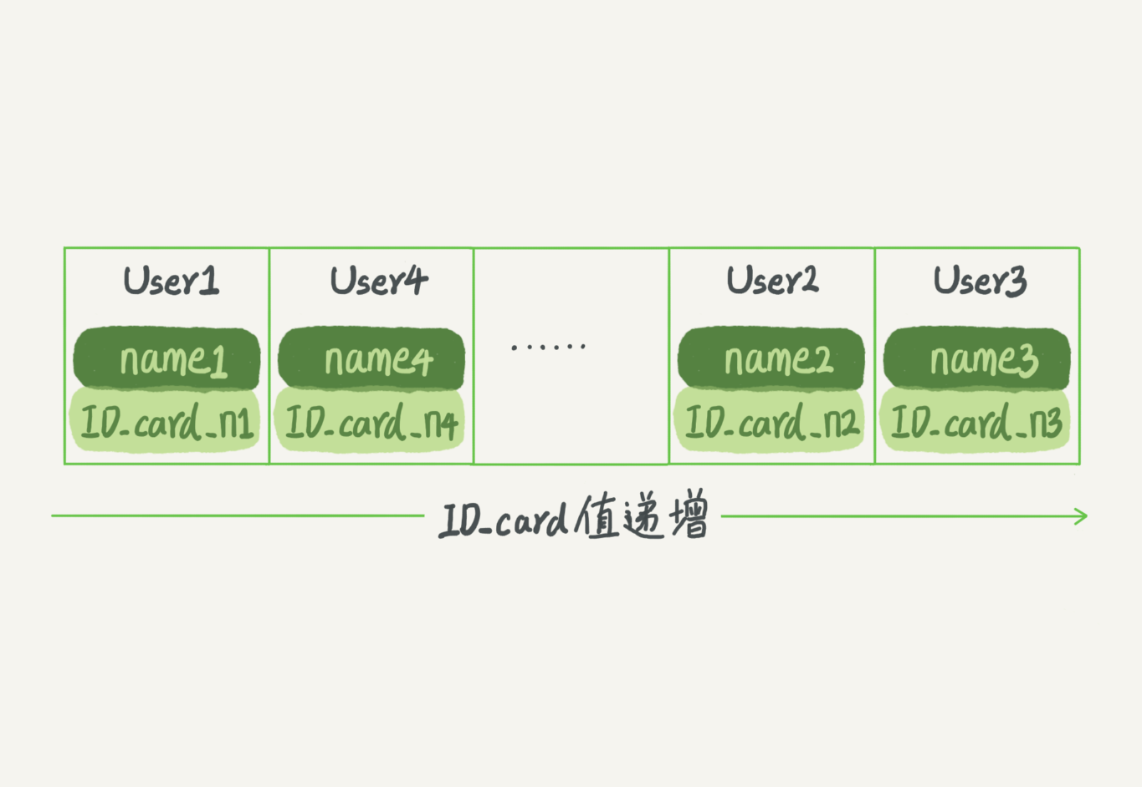
使用有序数组来实现,通过二分法来查找数据。有序数组索引只适用于静态存储引擎,比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。
优点:
- 等值查询和范围查询场景中的性能就都非常优秀。
缺点:
- 新增数据效率低。你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。
- 搜索树
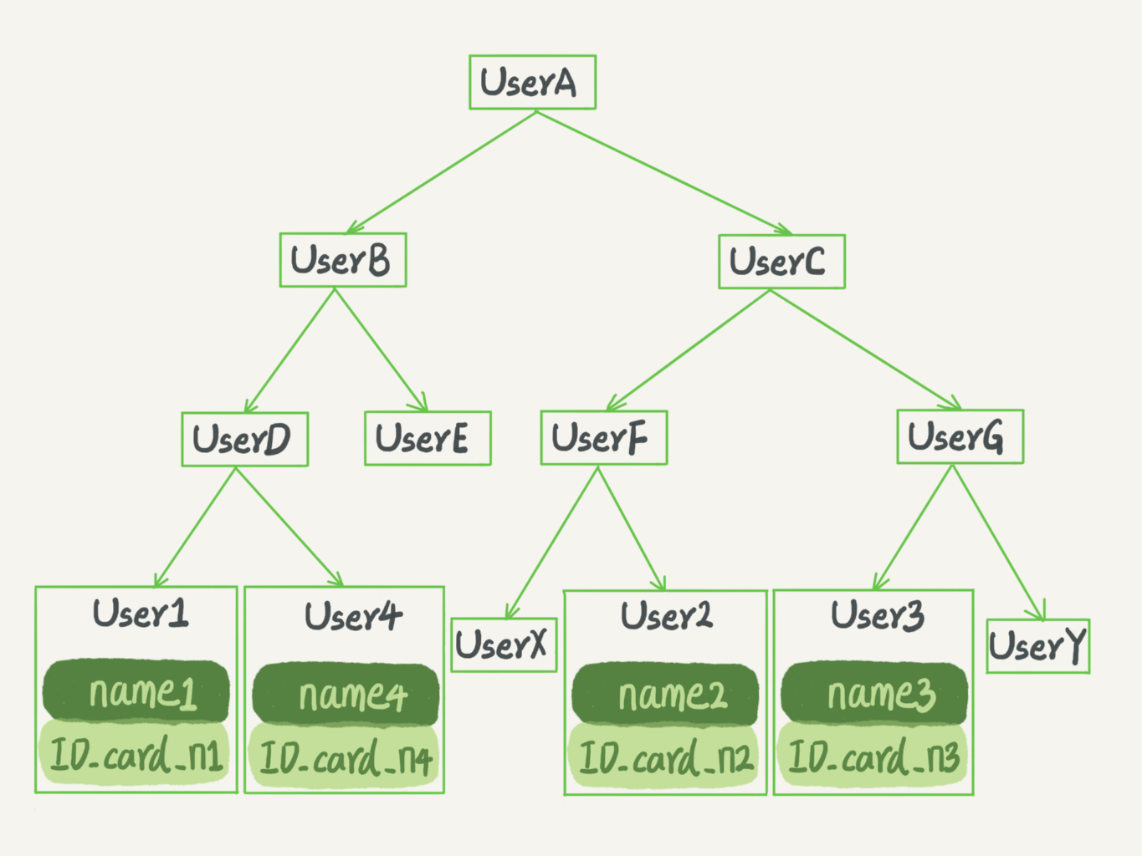
特点:每个节点的左儿子小于父节点,父节点又小于右儿子。
查找数据时间复杂度O(log(N))。更新的时间复杂度也是 O(log(N))。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
你心里要有个概念,数据库底层存储的核心就是基于这些数据模型的。每碰到一个新数据库,我们需要先关注它的数据模型,这样才能从理论上分析出这个数据库的适用场景。
InnoDB 的索引模型
每一个索引在 InnoDB 里面对应一棵 B+ 树。没有主键的表,innodb会给默认创建一个Rowid做主键。
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。这个表的建表语句是:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下。
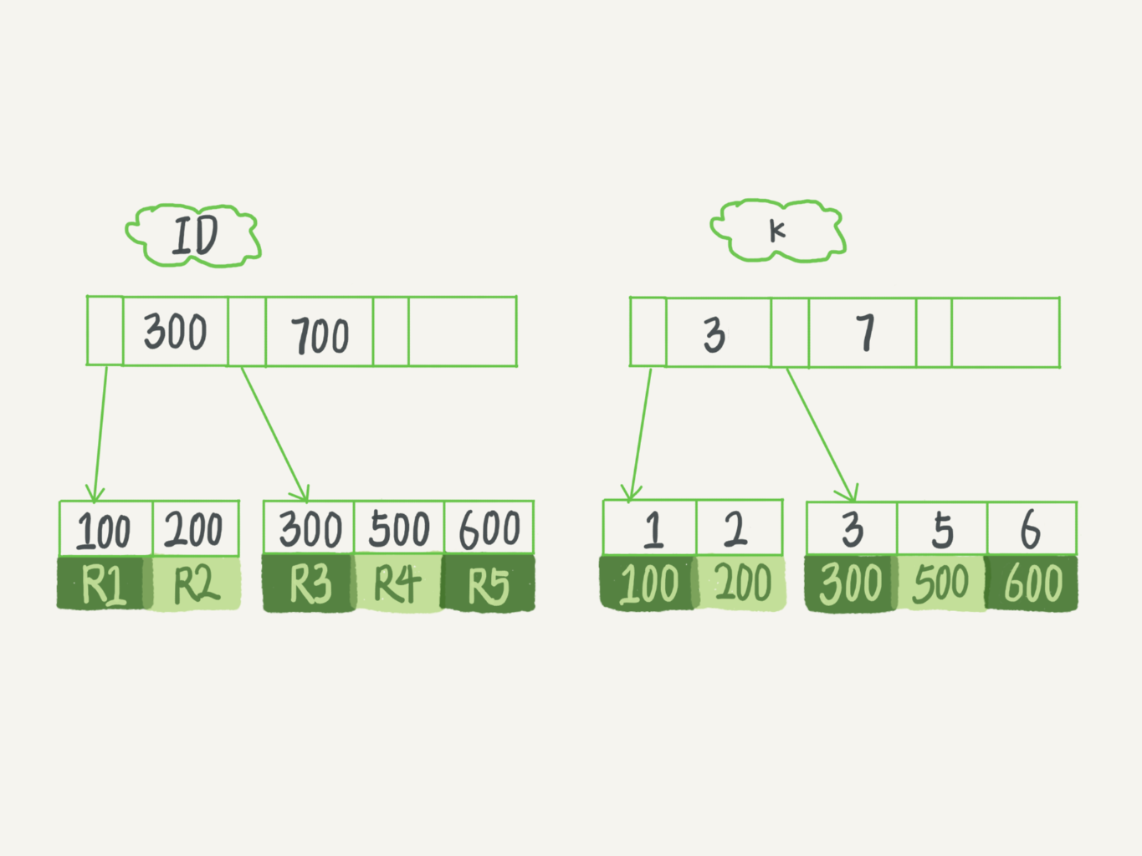
主键索引的叶子节点存的是page (页),一个页里面可以存多个整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
索引维护
如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
页分裂:如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。
页合并:当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。
哪些场景下应该使用自增主键?
时间效率上看:自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
存储空间上看:由于每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型(bigint)则是 8 个字节。
而哪些场景下不应该使用自增主键?
有些业务的场景需求是这样的:只有一个索引;该索引必须是唯一索引。你一定看出来了,这就是典型的 KV 场景。由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
现在一般自增索引都设置为bigint unsigned,因为现在很多业务插入数据容易超过int 上限,实际上是建议设置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号