

C++学习笔记——多线程(1)
目前在做推理引擎开发相关的工作,这块内容的话,对工程能力的要求还是比较高的,不再像以前只是写一些Python脚本训训模型就可以了,而且深入了解C++之后,也能感受到Python较C++暴露出的缺点,另一方面,由于模型推理所需的高效性,目前推理引擎的开发基本上都是用C++来实现,而且其中绕不开的一个难点就是多线程。这个系列我打算将我学习C++多线程开发的历程整理成文章,梳理相关知识点并整合到已有的知识体系中。
1. 线程和进程
线程和进程是操作系统的概念,这部分知识应该在学CSAPP的时候能够学习到,从另一个角度来说,假如已经编写了一个main.cpp文件,并且里面定义了main函数,然后通过编译该文件后就可以生成一个可执行文件(程序)main.o,当我们在终端中运行./main.o后,该可执行文件便会被操作系统加载到内存中,保存在一个相对独立的内存区域(虚拟地址空间),该空间的起始地址是0x00, 在32位操作系统上一个进程分配的空间大小最大为4GB,如下图所示,这里面的地址都是相对地址,真正访问的时候是会映射到内存物理地址上去的,这种策略可以有效防止多个进程运行时的地址重叠问题。这个虚拟地址空间中最重要的几个部分:
1、栈区(stack):由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap):般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回 收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后由系统释放。
4、文字常量区 :常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区 :存放函数体的二进制代码。
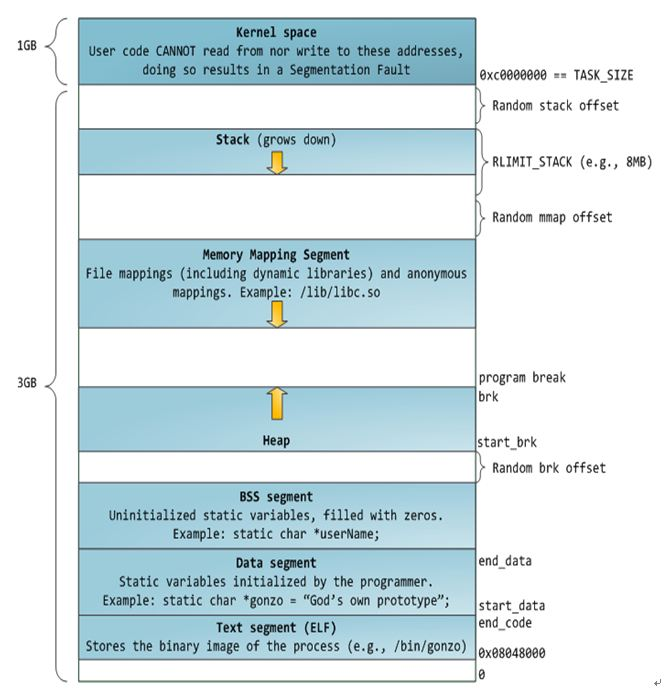
进程的虚拟地址空间
当程序加载到内存后,会自动开启一个主线程用来执行main函数中的代码,程序按照代码逻辑依次执行直至退出main函数,这个过程便称之为进程——即进行中的程序。可见程序运行时便会启动一个线程,此外我们也可以直接或间接调用创建线程的系统函数来在进程中继续创建除了主线程之外的其他线程,原理上这些线程可以共享该进程内存空间的所有东西。C++2.0已经提供了pthread库封装了多线程相关的一些函数。
2. C++多线程操作函数
多线程运行的目的是为了提高效率或者使不同模块的任务能够同时运行,一般情况下后台服务的目的都是前者,即提高服务吞吐量,服务部署之后是可以通过动态设置并发线程数来提高处理效率的。C++中常用的多线程相关的库函数有thread、mutex、future、conditional_variable等等。
①mutex: 创建一个互斥锁对象用于锁定临界区,临界区中主要包含了一些如果多个线程同时进入该区域,会导致操作混乱,所以在某一个线程进入临界区时,便给该区域上锁,当其他线程执行到要进入临界区时,发现该区域已经上锁,则阻塞在这个地方。拥有锁的线程直到退出该区域时再解锁,解锁之后,其他线程(包括已阻塞的线程才能继续运行)。原始的加解锁函数时lock()和unlock(), 但如果忘记了unlock则会导致死锁。所以比较常用的方法是创建临时对象 std::lock_guardstd::mutex lk(mutex_obj),这样可以实现在退出作用域时自动解锁。另外std::unique_lock也可以实现自动加解锁,但相比于std::lock_guard更加灵活,可以实现随时主动加解锁,但也会更加消耗系统资源,所以一般情况下lock_guard就够用了。
②thread: 用于创建线程。创建一个thread对象时,需要传入一个可调用对象,如果有传参还可以直接传参进去。
③future: 可以从异步执行的线程中获取结果,类似于一个占位符,当线程执行结束后便可通过.get()方法获取结果,未执行结束则阻塞直到结果返回。
④conditional_variable:当 std::condition_variable对象调用wait 函数后,当前线程会被阻塞,直到另一个线程在相同的 std::condition_variable 对象上调用了 notify 函数来唤醒当前线程。另外还有第二参数限制,只有当第二参数为false时才会执行阻塞,这个第二参数在生产者消费者模式中是任务队列的size,即如果队列为空则消费者停止获取任务。
3. C++线程池
构建线程池的目的是为了在任务很多的情况下,利用多个线程同时执行,以提高处理效率。我们只需要将任务传递给线程池,该任务便可以自动由线程池管理起来,在适当的时候执行。那么总的来说,线程池需要实现的两个模块分别是:①任务队列:用于暂存传递给线程池的任务;②线程队列:构建一定数目的线程用于执行线程队列中的任务。下面的线程池参照Skykey:基于C++11实现线程池 这篇写的,推荐大家去读原作者的这篇文章,写的很详细。
任务队列类:
template <typename T>
class SafeQueue
{
public:
SafeQueue() {}
~SafeQueue() {}
SafeQueue(SafeQueue&& other) {}
//获取empty状态
bool is_empty() {
std::lock_guard<std::mutex> m_guard(m);
return taskQ.empty();
}
// 入队和出队
int push(T& task) {
std::lock_guard<std::mutex> m_guard(m);
taskQ.push(task);
return 0;
}
bool pop(T& task) {
std::lock_guard<std::mutex> m_guard(m);
if (taskQ.empty()) {
return false;
}
task = taskQ.front();
taskQ.pop();
return true;
}
private:
std::queue<T> taskQ;
std::mutex m;
};
任务队列类的实现关键是对每一个接口加锁(线程安全),防止多线程同时访问导致数据混乱,也有可能导致程序崩溃。主要接口有三个:
empty():用于返回当前队列是否为空的状态,该状态会作为后面worker线程阻塞的条件;
push(): 将任务压入任务队列;
pop(): 从任务队列获取一个任务,并返回一个获取成功与否的信号;
地外,该任务队列实现为一个模板类,所以可以传入的任务类型也比较灵活。
线程池类:
#include "taskqueue.h"
class ThreadPool
{
private:
class ThreadWorker
{
private:
int m_id;
ThreadPool* m_pool;
public:
ThreadWorker(ThreadPool* pool, const int id) :
m_id(id), m_pool(pool) {}
void operator()() {
std::function<void()> func;
bool dequeued;
while (!m_pool->m_shutdown)
{
{
std::unique_lock<std::mutex> lock(m_pool->m_conditional_mutex);
if (m_pool->m_queue.empty())
{
m_pool->m_conditional_lock.wait(lock);
}
dequeued = m_pool->m_queue.pop(func);
}
if (dequeued)
{
func();
}
}
}
};
public:
ThreadPool(const int n_threads = 4) :m_threads(std::vector<std::thread>(n_threads)), m_shutdown(false) {}
ThreadPool(const ThreadPool&) = default;
ThreadPool(ThreadPool&&) = default;
ThreadPool& operator=(const ThreadPool&) = default;
ThreadPool& operator=(ThreadPool&&) = default;
void init() {
for (int i = 0; i < m_threads.size(); ++i) {
m_threads.at(i) = std::thread(ThreadWorker(this, i));
}
}
void shutdown()
{
m_shutdown = true;
m_conditional_lock.notify_all();
for (int i = 0; i < m_threads.size(); i++)
{
if (m_threads.at(i).joinable()) {
m_threads.at(i).join();
}
}
}
template <typename F, typename... Args>
auto submit(F&& f, Args &&...args) -> std::future<decltype(f(args...))>
{
// Create a function with bounded parameter ready to execute
std::function<decltype(f(args...))()> func = std::bind(std::forward<F>(f), std::forward<Args>(args)...);// 连接函数和参数定义,特殊函数类型,避免左右值错误
// Encapsulate it into a shared pointer in order to be able to copy construct
auto task_ptr = std::make_shared<std::packaged_task<decltype(f(args...))()>>(func);
// Warp packaged task into void function
std::function<void()> warpper_func = [task_ptr]()
{
(*task_ptr)();
};
// 队列通用安全封包函数,并压入安全队列
m_queue.enqueue(warpper_func);
// 唤醒一个等待中的线程
m_conditional_lock.notify_one();
// 返回先前注册的任务指针
return task_ptr->get_future();
}
private:
bool m_shutdown;
SafeQueue<std::function<void()>> m_queue;
std::vector<std::thread> m_threads;
std::mutex m_conditional_mutex;
std::condition_variable m_conditional_lock;
};
线程池类的实现相对比较复杂,主要有以下几点:
ThreadWorker:其中的核心是工作者线程启动后自动获取任务队列中的任务并执行的过程,这里面涉及到同步的问题。一般我们都是给thread传入一个函数,让其自动执行完毕并自动销毁线程。这里原理上我们也可以这样做,但是反复创建和销毁线程会带来额外开销。所以线程池里我们是给每个线程传入一个可调用的工作者线程对象,该对象的()重载函数带有while(1)循环,可以反复从任务队列中读取任务并执行。
submit():该函数就有点复杂了(我也很懵),用到了c++高级用法,但核心就是对任意参数类型的任意函数用函数适配器和智能指针封装为一个返回类型固定为std::function<void()>的匿名函数,然后将其push到任务队列中,并随机唤醒一个由m_conditional_lock阻塞的线程继续运行。
init(): 启动每个工作者线程,如果任务队列为空则阻塞,非空则持续获取任务并执行,直到任务队列为空再次阻塞。
shutdown(): 将关闭信号置为true,并唤醒所有线程并紧接着阻塞等待所有工作者线程退出。此时工作者线程执行到while判断处时条件为假->退出循环->退出函数->线程关闭. 等到所有子线程退出后,shutdown函数也就退出了。
测试代码:
#include "threadpool/ThreadPool.h"
#include <random>
#include <iostream>
#include <chrono>
#include <future>
std::random_device rd;
std::mt19937 mt(rd());
std::uniform_int_distribution<int> dist(-1000, 1000);
auto rnd = std::bind(dist, mt);
void simulate_hard_computation()
{
std::this_thread::sleep_for(std::chrono::milliseconds(2000 + rnd()));
}
void multiply(const int a, const int b)
{
simulate_hard_computation();
const int res = a * b;
std::cout << a << "*" << b << "=" << res << std::endl;
}
void multiply_output(int& out, const int a, const int b)
{
simulate_hard_computation();
out = a * b;
std::cout << a << "*" << b << "=" << out << std::endl;
}
int multiply_return(const int a, const int b)
{
simulate_hard_computation();
const int res = a * b;
std::cout << a << "*" << b << "=" << std::endl;
return res;
}
int main()
{
ThreadPool pool(3);
pool.init();
//传递多个任务
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 10; j++) {
pool.submit(multiply, i, j);
}
}
//使用ref传递的输出参数提交函数
int output_ref;
auto future1 = pool.submit(multiply_output, std::ref(output_ref), 5, 6);
future1.get();
std::cout << "Last operation result is equals to " << output_ref << std::endl;
// 使用return参数提交函数
auto future2 = pool.submit(multiply_return, 30, 11);
// 等待乘法输出完成
int res = future2.get();
std::cout << "Last operation result is equals to " << res << std::endl;
pool.shutdown();
return 0;
}
测试代码中模拟了多种传参的函数类型,均可以通过submit方法传递给线程池执行:
①有传参无返回值void func(a,b):直接调用pool.submit(func,a,b)
②有传参且有返回值int func(a,b):直接调用并用future对象接收返回值,如 auto future_res = pool.submit(func,std::ref(res), a, b) , 然后调用future_res.get()方法阻塞到函数执行完毕并获取返回值。
③有传参且返回值通过参数返回void func(T &res, a,b),同样直接调用执行,但返回值要用std::ref封装一下,如auto future_res = pool.submit(func,std::ref(res), a, b),这里future_res是用来调用get()方法等待函数执行完毕的,等到执行完毕后,res的值便可以正常访问。
基础的线程池功能就是以上这些,此外还可以加入优先级任务队列、工作者线程数按照实时任务数量动态增减等高级功能。此外还可以在任务队列为空或者低于某一阈值时通知其他线程(生产者)提交任务到任务队列,即生产者消费者模式。目前C++相关知识还掌握的很浅,需要继续学习,等有新的知识点了再写,共勉。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理